大数据笔记16:Hadoop入门
第16天——Hadoop入门
一、Hadoop概述
1、Hadoop创始人Doug Cutting
2、Hadoop简介
3、Hadoop发展简史
4、Hadoop特性
5、Hadoop应用现状
6、Hadoop在企业中的应用架构
7、Apache Hadoop版本演变
8、Hadoop各种版本
二、Hadoop项目结构
三、Hadoop安装方式
四、伪分布式安装Hadoop
五、小结
一、Hadoop概述
1、Hadoop创始人Doug Cutting
1985年毕业于美国斯坦福大学,他是Lucene、Nutch和Hadoop三个项目的创立者,先是参与了Lucene的开发,然后是Nutch,然后是Hadoop。最近几年,一直在专注于Hadoop生态系统的建设。比如Hbase,Hbase越来越稳定,也越来越高效。逐渐在升温。
2、Hadoop简介
- Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构
- Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中
- Hadoop的核心是分布式文件系统HDFS(Hadoop Distributed File System)和MapReduce
- Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力
- 几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等,都支持Hadoop
3、Hadoop发展简史
- Hadoop最初是由Apache Lucene项目的创始人Doug Cutting开发的文本搜索库。Hadoop源自始于2002年的Apache Nutch项目——一个开源的网络搜索引擎并且也是Lucene项目的一部分
- 在2004年,Nutch项目也模仿GFS开发了自己的分布式文件系统NDFS(Nutch Distributed File System),也就是HDFS的前身
- 2004年,谷歌公司又发表了另一篇具有深远影响的论文,阐述了MapReduce分布式编程思想
- 2005年,Nutch开源实现了谷歌的MapReduce
- 到了2006年2月,Nutch中的NDFS和MapReduce开始独立出来,成为Lucene项目的一个子项目,称为Hadoop,同时,Doug Cutting加盟雅虎
- 2008年1月,Hadoop正式成为Apache顶级项目,Hadoop也逐渐开始被雅虎之外的其他公司使用
- 2008年4月,Hadoop打破世界纪录,成为最快排序1TB数据的系统,它采用一个由910个节点构成的集群进行运算,排序时间只用了209秒
- 在2009年5月,Hadoop更是把1TB数据排序时间缩短到62秒。Hadoop从此名声大震,迅速发展成为大数据时代最具影响力的开源分布式开发平台,并成为事实上的大数据处理标准
4、Hadoop特性
Hadoop是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,它具有以下几个方面的特性:
- 高可靠性
- 高效性
- 高可扩展性
- 高容错性
- 成本低
- 运行在Linux平台上
- 支持多种编程语言
5、Hadoop应用现状
- Hadoop凭借其突出的优势,已经在各个领域得到了广泛的应用,而互联网领域是其应用的主阵地
- 2007年,雅虎在Sunnyvale总部建立了M45——一个包含了4000个处理器和1.5PB容量的Hadoop集群系统
- Facebook作为全球知名的社交网站,Hadoop是非常理想的选择,Facebook主要将Hadoop平台用于日志处理、推荐系统和数据仓库等方面
- 国内采用Hadoop的公司主要有百度、淘宝、网易、华为、中国移动等,其中,淘宝的Hadoop集群比较大
6、Hadoop在企业中的应用架构

7、Apache Hadoop版本演变
- Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0
- 第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则增加了NameNode HA等新的重大特性
- 第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性
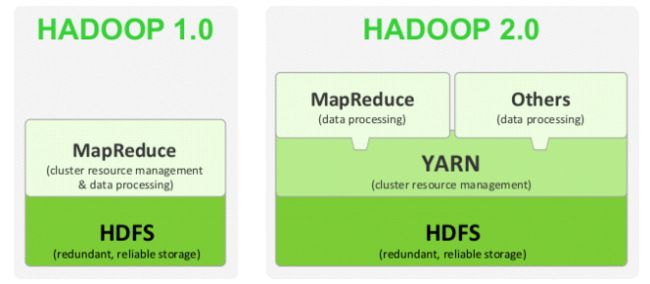
Hadoop1.0:HDFS + MapReduce
Hadoop2.0:引入Yarn,可以在集群中同时运行多种计算框架,比如Spark、Tez。(Yarn:Yet Another Resource Negotiator)
Hadoop3.0:Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,这直接迫使Hadoop社区基于JDK 1.8重新发布一个新的Hadoop版本,而这正是hadoop 3.0。Hadoop 3.0的alpha版预计2016年夏天发布,GA版本11月或12月发布。Hadoop 3.0中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR Native Task优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
8、Hadoop各种版本
(1)开源版和发行版
- Apache Hadoop
- Hortonworks
- Cloudera(CDH:Cloudera Distribution Hadoop)
- MapR
(2)选择Hadoop版本的考虑因素
- 是否开源(即是否免费)
- 是否有稳定版
- 是否经实践检验
- 是否有强大的社区支持

二、Hadoop项目结构
Hadoop项目结构不断丰富发展,已经形成一个丰富的Hadoop生态系统。


三、Hadoop安装方式
1、单机模式:不能使用HDFS,只能使用MapReduce,所以单机模式最主要的目的是在本机调试MapReduce代码。
2、伪分布式模式:用多个线程模拟多台真实机器,即模拟真实的分布式环境。Hadoop在单节点上以伪分布式方式运行,Hadoop进程以分离的Java进程来运行,节点既作为NameNode也作为DataNode,同时,读取的是HDFS中的文件。
3、完全分布式模式:使用多个节点构成集群环境来运行Hadoop。
四、伪分布式安装Hadoop
1、创建虚拟机hadoop
(1)克隆虚拟机hadoop

(2)启动虚拟机hadoop,设置网络连接


(3)关闭防火墙
执行:
service iptables stop
这个指令关闭完防火墙后,如果重启,防火墙会重新建立,所以,如果想重启后防火墙还关闭,需额外执行:
chkconfig iptables off。

注意:CentOS 7上,关闭防火墙命令变了。
- 停止防火墙服务:systemctl stop firewalld
- 禁用防火墙服务:systemctl disable firewalld
(4)用SecureCRT登录虚拟机hadoop

2、配置主机名
执行:vim /etc/sysconfig/network
编辑主机名:HOSTNAME=
hadoop
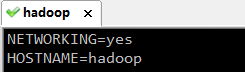
注意:主机名里不能有下滑线,或者特殊字符#或$,不然会找不到主机导致无法启动。这种方式更改主机名需要重启才能永久生效,因为主机名属于内核参数。
如果不想重启,可以执行:hostname hadoop。但是这种更改是临时的,重启后会恢复原主机名。可结合使用。先修改配置文件,然后执行:hostname hadoop 。可以达到不重启或重启都是主机名都是同一个的目的。
重启虚拟机:reboot。


3、配置hosts文件,做域名映射
执行:vim /etc/hosts

这样访问“192.168.225.100”,就可用主机名“hadoop”替代。
4、配置免秘钥登录
(1)执行:ssh-keygen 生成密钥对
一直敲回车,生成节点的公钥和私钥,生成的文件会自动放在/root/.ssh目录下,然后把公钥发往远程机器或本机。

5、配置免密登录自己
执行:ssh-copy-id
root@hadoop

验证一下,hadoop是否可以免密登录自己:

6、安装和配置JDK
(1)创建/home/software目录

当前目录已经切换到/home/software。
(2)利用rz上传JDK安装包


(3)利用rpm命令安装JDK
[root@hadoop software]# rpm -ivh jdk-8u111-linux-x64.rpm

查看JDK安装在何处:rpm -qc jdk1.8.0_111

(3)配置JDK环境变量
执行: vim /etc/profile
在尾行添加:
JAVA_HOME=/usr/java/jdk1.8.0_111
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH

末行模式下:wq,保存退出。
发布
source /etc/profile
使更改的配置立即生效。
发布java -version 查看JDK版本信息。

7、下载、上传和解压Hadoop安装包
(1)下载Hadoop
下载地址:
http://hadoop.apache.org/releases.html

注意:source表示源码;binary表示二进制包(安装包)


(2)利用rz上传hadoop-2.7.4.tar.gz

(3)解压缩hadoop-2.7.4.tar.gz
执行:tar -zxvf hadoop-2.7.4.tar.gz,生成目录hadoop-2.7.4。

(4)进入目录hadoop-2.7.4,查看其子目录

- bin目录:命令脚本
- etc/hadoop:存放hadoop的配置文件
- lib目录:hadoop运行的依赖jar包
- sbin目录:存放启动和关闭hadoop等命令
- libexec目录:存放的也是hadoop命令,但一般不常用,最常用的就是bin和etc目录。
查看etc/hadoop目录:

查看sbin目录:

8、修改hadoop环境配置文件hadoop-env.sh
进入hadoop配置目录,执行vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_111
export HADOOP_HOME=/home/software/hadoop-2.7.4
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"

然后执行:source hadoop-env.sh 让配置立即生效。
9、修改hadoop核心配置文件core-site.xml
在etc/hadoop目录下执行:vim core-site.xml

10、修改分布式文件系统配置文件hdfs-site .xml
[root@hadoop hadoop]# vim hdfs-site.xml

11、修改MapReduce配置文件mapred-site.xml
将模板文件mapred-site.xml.template拷贝一份,并重命名为mapred-site.xml
[root@hadoop hadoop]# cp mapred-site.xml.template mapred-site.xml
执行:vim mapred-site.xml

yarn是资源协调工具。
12、修改yarn配置文件yarn-site.xml
[root@hadoop hadoop]# vim yarn-site.xml

13、配置hadoop的环境变量
[root@hadoop hadoop]# vim /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_111
HADOOP_HOME=/home/software/hadoop-2.7.4
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME HADOOP_HOME CLASSPATH PATH

执行source /etc/profile,让配置生效。
[root@hadoop hadoop]# source /etc/profile
14、创建hadoop存放生成文件的临时目录tmp
15、格式化名称节点namenode
格式化namenode,形成可用的分布式文件系统HDFS。
执行:hadoop namenode -format
如果不好使,可以重启Linux。
当出现:successfully,证明格式化成功。

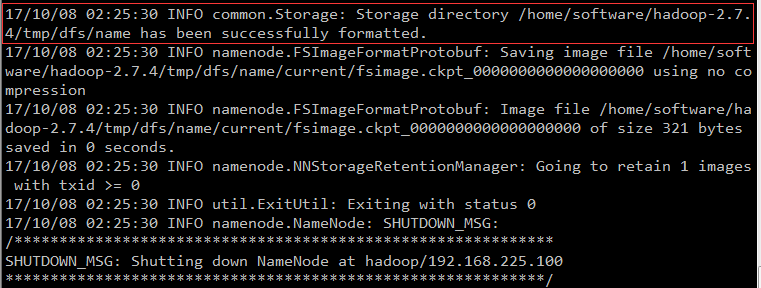
建议使用命令:
hdfs namenode -format
五、小结
1、Hadoop被视为事实上的大数据处理标准,讲述了Hadoop的发展历程,并阐述了Hadoop的高可靠性、高效性、高可扩展性、高容错性、成本低、运行在Linux平台上、支持多种编程语言等特性。
2、Hadoop目前已经在各个领域得到了广泛的应用,雅虎、Facebook、百度、淘宝、网易等公司都建立了自己的Hadoop集群。
3、经过多年发展,Hadoop项目已经变得非常成熟和完善,包括Common、Avro、Zookeeper、HDFS、MapReduce、HBase、Hive、Chukwa、Pig等子项目,其中,HDFS和MapReduce是Hadoop的两大核心组件。