Spring Boot数据——ElasticSearch
一、为什么需要ES?
1. 思考:大规模数据如何检索?
如:当系统数据量上了10亿、100亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑问题:
1)用什么数据库好?(mysql、sybase、oracle、达梦、神通、mongodb、hbase…)
2)如何解决单点故障;(lvs、F5、A10、Zookeep、MQ)
3)如何保证数据安全性;(热备、冷备、异地多活)
4)如何解决检索难题;(数据库代理中间件:mysql-proxy、Cobar、MaxScale等;)
5)如何解决统计分析问题;(离线、近实时)
2. 传统关系型数据库的应对解决方案
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈:
解决要点:
1)通过主从备份解决数据安全性问题;
2)通过数据库代理中间件心跳监测,解决单点故障问题;
3)通过代理中间件将查询语句分发到各个slave节点进行查询,并汇总结果

3. 非关系型数据库的解决方案
对于Nosql数据库,以mongodb为例,其它原理类似:
解决要点:
1)通过副本备份保证数据安全性;
2)通过节点竞选机制解决单点问题;
3)先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果

4. 完全把数据放入内存怎么样?
我们知道,完全把数据放在内存中是不可靠的,实际上也不太现实,当我们的数据达到PB级别时,按照每个节点96G内存计算,在内存完全装满的数据情况下,我们需要的机器是:1PB=1024T=1048576G
节点数=1048576/96=10922个
实际上,考虑到数据备份,节点数往往在2.5万台左右。成本巨大决定了其不现实!
从前面讨论我们了解到,把数据放在内存也好,不放在内存也好,都不能完完全全解决问题。
全部放在内存速度问题是解决了,但成本问题上来了。
为解决以上问题,从源头着手分析,通常会从以下方式来寻找方法:
1、存储数据时按有序存储;
2、将数据和索引分离;
3、压缩数据;
这就引出了Elasticsearch。
二、 什么是Elasticsearch
1. ES定义:
ES=elaticsearch简写, Elasticsearch是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2. Lucene与ES关系?
1> Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2> Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
3. ES主要解决问题:
1> 检索相关数据;
2> 返回统计结果;
3> 速度要快。
4. ES基础及索引原理分析
1> ES文件存储及与关系型数据库比较
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将
Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 记录行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互,可以使用Java API,也可以直接使用HTTP的Restful API方式,比如我们打算插入一条记录,可以简单发送一个HTTP的请求:
PUT /megacorp/employee/1
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
更新,查询也是类似这样的操作
2> ES索引
Elasticsearch最关键的就是提供强大的索引能力了,其实InfoQ的这篇时间序列数据库的秘密(2)——索引写的非常好,我这里也是围绕这篇结合自己的理解进一步梳理下,也希望可以帮助大家更好的理解这篇文章。
Elasticsearch索引的精髓:
一切设计都是为了提高搜索的性能
另一层意思:为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了。前面看到往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,比如上面例子中的name, sex, age, about, interests,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默的为这些字段建立索引–倒排索引,因为Elasticsearch最核心功能是搜索。
Elasticsearch是如何做到快速索引的?
InfoQ那篇文章里说Elasticsearch使用的倒排索引比关系型数据库的B-Tree索引快,为什么呢?
-
什么是B-Tree索引?
上大学读书时老师教过我们,二叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系型数据库采用了B-Tree/B+Tree这样的数据结构:

为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度。 -
什么是倒排索引?

继续上面的例子,假设有这么几条数据(为了简单,去掉about, interests这两个field):
| ID | Name | Age | Sex |
| -- |:------------:| -----:| -----:|
| 1 | Kate | 24 | Female
| 2 | John | 24 | Male
| 3 | Bill | 29 | Male
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
| -- |:----:|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age:
| Term | Posting List |
| -- |:----:|
| 24 | [1,2] |
| 29 | 3 |
Sex:
| Term | Posting List |
| -- |:----:|
| Female | 1 |
| Male | [2,3] |
参考:
https://www.cnblogs.com/dreamroute/p/8484457.html
我写不下去了,有时间再说,这会有点忙
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
- 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的 - 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
关于ID因素: 上面看到的压缩算法,都是对Posting list里的大量ID进行压缩的,那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;
另外一个因素: 可能是最影响查询性能的,应该是最后通过Posting list里的ID到磁盘中查找Document信息的那步,因为Elasticsearch是分Segment存储的,根据ID这个大范围的Term定位到Segment的效率直接影响了最后查询的性能,如果ID是有规律的,可以快速跳过不包含该ID的Segment,从而减少不必要的磁盘读次数,具体可以参考这篇如何选择一个高效的全局ID方案(评论也很精彩)
5. ES基本概念
1> Cluster:集群。
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2> Node:节点。
形成集群的每个服务器称为节点。
3> Shard:分片。
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4> Replia:副本。
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
5> 全文检索。
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于MySQL里的like语句。
全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”你们的激情是因为什么事情来的” 可能会被分词成:“你们“,”激情“,“什么事情“,”来“ 等token,这样当你搜索“你们” 或者 “激情” 都会把这句搜出来。
6. ES工作原理
1> 启动过程
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示:
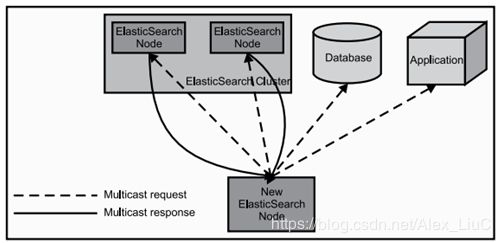
在集群中,一个节点被选举成主节点(master node)。这个节点负责管理集群的状态,当群集的拓扑结构改变时把索引分片分派到相应的节点上。
从用户的角度来看,主节点在ElasticSearch中并没有占据着重要的地位,这与其它的系统(比如数据库系统)是不同的。实际上用户并不需要知道哪个节点是主节点;所有的操作需求可以分发到任意的节点,ElasticSearch内部会完成这些让用户感到不明觉历的工作。在必要的情况下,任何节点都可以并发地把查询子句分发到其它的节点,然后合并各个节点返回的查询结果。最后返回给用户一个完整的数据集。所有的这些工作都不需要经过主节点转发(节点之间通过P2P的方式通信)。
主节点会去读取集群状态信息;在必要的时候,会进行恢复工作。在这个阶段,主节点会去检查哪些分片可用,决定哪些分片作为主分片。处理完成后,集群就会转入到黄色状态。
这意味着集群已经可以处理搜索请求了,但是还没有火力全开(这主要是由于所有的主索引分片(primary shard)都已经分配好了,但是索引副本还没有)。接下来需要做的事情就是找到复制好的分片,并设置成索引副本。当一个分片的副本数量少了,主节点会决定将缺少的分片放置到哪个节点中,并且依照主分片创建副本。所有工作完成后,集群就会变成绿色的状态(表示所有的主分片的索引副本都已经分配完成)。
2> 探测失效节点
在正常工作时,主节点会监控所有的节点,查看各个节点是否工作正常。如果在指定的时间里面,节点无法访问,该节点就被视为出故障了,接下来错误处理程序就会启动。集群需要重新均衡——由于该节点出现故障,分配到该节点的索引分片丢失。其它节点上相应的分片就会把工作接管过来。换句话说,对于每个丢失的主分片,新的主分片将从剩余的分片副本(Replica)中选举出来。重新安置新的分片和副本的这个过程可以通过配置来满足用户需求。
由于只是展示ElasticSearch的工作原理,我们就以下图三个节点的集群为例。集群中有一个主节点和两个数据节点。主节点向其它的节点发送Ping命令然后等待回应。如果没有得到回应(实际上可能得不到回复的Ping命令个数取决于用户配置),该节点就会被移出集群。

3> 与ElasticSearch进行通信
我们已经探讨了ElasticSearch是如何构建起来的,但是归根到底,最重要的是如何往ElasticSearch中添加数据以及如何查询数据。为了实现上述的需求,ElasticSearch提供了精心设计的API。
ElasticSearch认为数据应该伴随在URL中,或者作为请求的主体(request body),以一种JSON格式(http://en.wikipedia.org/wiki/JSON )的文档发送给服务器。如果读者用Java或者其它运行在JVM虚拟机上的语言,应该关注一下Java API,它除了是群集中内置的REST风格API外,功能与URL请求是一样的。值得一提的是在ElasticSearch内部,节点之间的通信也是用相关的Java API。
4> 索引数据
ElasticSearch提供了4种索引数据的办法。
第1种:最简单的是使用索引API。通过它可以将文档添加到指定的索引中去。比如,通过curl工具(访问http://curl.haxx.se/ ),我们可以通过如下的命令创建一个新的文档:
curl -XPUT http://localhost:9200/blog/article/1 ‘{“title”: “Newversion of Elastic Search released!”, “content”: “…”,“tags”:[“announce”, “elasticsearch”, “release”] }’
第2种和第3种办法可以通过bulk API和UDP bulk API批量添加文档。通常的bulk API采用HTTP协议,UDP bulk API采用非连接的数据包协议。UDP协议传输速度会更快,但是可靠性要差一点。
第4种办法就是通过river插件。river运行在ElasticSearch集群的节点上,能够从外部系统中获取数据。
有一点需要注意,索引数据的操作只会发生在主分片(primary shard)上,而不会发生在分片副本(Replica) 上。如果索引数据的请求发送到的节点没有合适的分片或者分片是副本,那么请求会被转发到含有主分片的节点。

5> 数据查询
我们能够与集群中包括主节点的任何节点通信。任何一个节点互相知道文档存在于哪个节点上,它们可以转发请求到我们需要数据所在的节点上。我们通信的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch透明的管理。
关于数据查询,其核心点在于查询过程不是一个简单、单一的流程。通常这个过程分为两个阶段:
- 查询分发阶段,会从各个分片中查询数据;
- 在结果汇总阶段,会把从各个分片上查询到的结果进行合并、排序等其它处理过程,然后返回给用户。
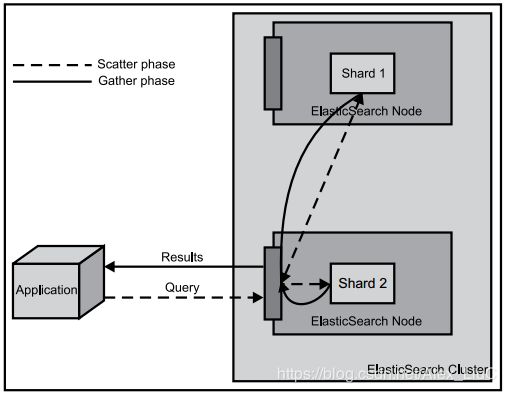
用户可以通过指定搜索类型来控制查询的分发和汇总过程:
-
QUERY_THEN_FETCH
是针对所有的块执行的,但返回的是足够的信息,而不是文档内容(Document)。结果会被排序和分级,基于此,只有相关的块的文档对象会被返回。由于被取到的仅仅是这些,故而返回的hit的大小正好等于指定的size。这对于有许多块的index来说是很便利的(返回结果不会有重复的,因为块被分组了)。 -
QUERY_AND_FETCH
最原始(也可能是最快的)实现就是简单的在所有相关的shard上执行检索并返回结果。每个shard返回一定尺寸的结果。由于每个shard已经返回了一定尺寸的hit,这种类型实际上是返回多个shard的一定尺寸的结果给调用者。最快,但不准确 -
DFS_QUERY_THEN_FETCH
与QUERY_THEN_FETCH相同,预期一个初始的散射相伴用来为更准确的score计算分配了的term频率。 -
DFS_QUERY_AND_FETCH
与QUERY_AND_FETCH相同,预期一个初始的散射相伴用来为更准确的score计算分配了的term频率。SCAN被用来检索大量的结果(甚至所有的结果),就像在传统数据库中使用的游标.全局排序,若禁止排序,无法查询实时数据。官网3.0会弃用.
查询API在ElasticSearch中有着很大的比重。通过使用Query DSL(基于JSON,用来构建复杂查询的语言) ,我们能够:
- 使用各种类型的查询方式,包括:简单的关键词查询(termquery) ,短语(phrase)、区间(range)、布尔(boolean)、模糊(fuzzy)、跨度(span)、通配符(wildcard)、地理位置(spatial)等其它类型的查询方式。
- 通过组合简单查询构建出复杂的查询。
- 过滤文档,去除不符合标准的文档而且不影响打分排序。
- 查找给定文档的相似文档。
- 查找给定短语的搜索建议和查询短语修正。
- 通过faceting构建动态的导航和数据统计
- 使用prospective search而且找到匹配文档的查询语句。(关于prospective search,似乎是一种推送方式。即把用户的查询语句存储到索引中,如果新的文档添加到索引中,就把文档关联到匹配的查询语句中。这种查询适合于新闻、博客等会定时更新的应用场景)
三、Spring Boot 中如何集成ES
1. 环境依赖
修改 POM 文件,添加 spring-boot-starter-data-elasticsearch 依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2. 数据源
方案一 使用 Spring Boot 默认配置
在 src/main/resources/application.properties 中配置数据源信息。
spring.data.elasticsearch.properties.host = 127.0.0.1
spring.data.elasticsearch.properties.port = 9300
通过 Java Config 创建ElasticSearchConfig。
@Configuration
@EnableElasticsearchRepositories("com.lianggzone.springboot.action.data.elasticsearch")
public class ElasticSearchConfig {}
方案二 手动创建
通过 Java Config 创建ElasticSearchConfig。
@Configuration
@EnableElasticsearchRepositories("com.lianggzone.springboot.action.data.elasticsearch")
public class ElasticsearchConfig2 {
private String hostname = "127.0.0.1";
private int port = 9300;
@Bean
public ElasticsearchOperations elasticsearchTemplate() {
return new ElasticsearchTemplate(client());
}
@Bean
public Client client() {
TransportClient client = new TransportClient();
TransportAddress address = new InetSocketTransportAddress(hostname, port);
client.addTransportAddress(address);
return client;
}
}
3. 业务操作
实体对象
@Document(indexName = "springbootdb", type = "news")
public class News {
@Id
private String id;
private String title;
private String content;
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyyMMdd'T'HHmmss.SSS'Z'")
@Field(type = FieldType.Date, format = DateFormat.basic_date_time, index = FieldIndex.not_analyzed)
@CreatedDate
private Date createdDateTime;
// GET和SET方法
}
DAO相关
public interface NewsRepository extends ElasticsearchRepository {
public List findByTitle(String title);
}
Service和Controller相关常规讨论在此不做赘述。
四、Elasticsearch的适用场景
- 百科类,类似百度百科、维基百科,例如牙膏的维基百科,全文检索,高亮,搜索推荐
- The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
- Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
- GitHub(开源代码管理),搜索上千亿行代码
- 电商网站,检索商品
- 日志数据分析,logstash采集日志,ES进行复杂的数据分析,ELK技术elasticsearch+logstash+kibana
- 商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
- BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化
- 站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
五、ES面试题
公众号程序员面试
ES面试要点