SCRAPY 爬虫笔记
SCRAPY 爬虫笔记
- WINDOWS下载安装scrapy
(1) 直接在Anaconda(开源的Python包管理器)上下载

下载完成后在Environment 中选择 uninstall 搜索 scrapy 点击安装

下载完成后打开cmd 输入scrapy , 如果出现如上图的显示代表scrapy已经安装完成.
- 第一个scrapy 程序
首选在cmd 输入
scrapy startproject XXX
xxx 就是我们第一个项目的名称
在spiders文件夹下面建立一个新的Python文件
import scrapy
class firstSpider(scrapy.Spider):
name = "first_spider" # 爬虫名字
start_urls = [
'http://lab.scrapyd.cn' # 爬虫地址
]
def parse(self, response):
famous = response.css('div.quote') # 提取所有名言 放入famous
for f in famous:
content = f.css('.text::text').extract_first() # 提取第一条名言内容
author = f.css('.author::text').extract_first() # 提取作者
tags = f.css('.tags.tag::text').extract() # tags 有好多所以不是提取第一个
tags = ','.join(tags) # 数组转换成字符串
# 文件操作
fileName = '%s-语录.txt' % author # 文件名
with open(fileName, "a+") as file:
file.write(content)
file.write('\n') # 换行
file.write('标签:' + tags)
file.write('\n------------------------------------\n')
next_page = response.css('li.next a::attr(href)').extract_first() # 爬取下一页
if next_page is not None:
next_page = response.urljoin(next_page) # 相对路径拼成绝对路径
yield scrapy.Request(next_page, callback=self.parse)
运行scrapy 程序就是在项目目录下运行cmd
>>> scrapy crawl XXX(爬虫名字)
3.从网站爬取图片
scrapy框架已经帮助我们实现了图片的下载
首先在pipeline里面继承scrapy的ImagesPipeline,get_media_requests(self, item, info)方法
class FirstSpiderPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for imgUrl in item['imgUrls']:
yield Request(imgUrl)
然后在item文件里面加入
imgUrl = scrapy.Field()
在spiders文件夹下新建一个文件,这里写我们的爬虫内容
class imageSpider(scrapy.Spider):
name = 'imgSpider'
start_urls = [
'http://lab.scrapyd.cn/archives/57.html',
'http://lab.scrapyd.cn/archives/55.html',
]
def parse(self, response):
item = ImageSpiderItem() #实例化item
imgUrls = response.css(".post-content img::attr(src)").extract() # 获取url链接
item['imgUrl'] = imgUrls
imgNames = response.css(".post-title a::text").extract_first()
item['imgName'] = imgNames
yield item
在setting里面设置我们图片下载的位置,当然也不要忘记打开我们的管道
#图片存储位置
IMAGES_STORE = 'D:\ImageSpider'
ITEM_PIPELINES = {
'image_spider.pipelines.ImageSpiderPipeline': 300,
}
最后运行爬虫,我们就得到了图片
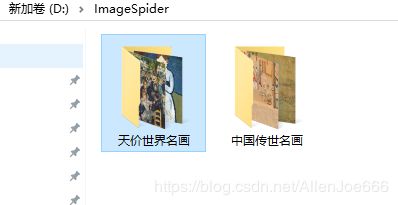
这里我讲同类文件按照名称分类下载了,只要在pipeline里面重写一个方法
def file_path(self, request, response=None, info=None):
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
image_guid = request.url.split('/')[-1] # 提取url前面名称作为图片名。
# 接收上面meta传递过来的图片名称
name = request.meta['name']
# 过滤windows字符串,不经过这么一个步骤,你会发现有乱码或无法下载
name = re.sub(r'[?\\*|“<>:/]', '', name)
# 分文件夹存储的关键:{0}对应着name;{1}对应着image_guid
filename = u'{0}/{1}'.format(name, image_guid)
return filename