我是一只百度贴吧的小爬虫
总体功能:查看特定帖子楼主的发言(不包含图片)
前段时间大概看了python的语法,但是确实第一次用python来写东西。很久之前就想学python,学爬虫了,现在终于开始了!谢了自己的第一个爬虫,很开心O(∩_∩)O 觉得学东西兴趣很重要,爬虫真的好玩!
整个功能的实现含有两个类,一个是工具类Tool,另一个是百度贴吧的爬虫类BaiduTieba,提取网页的内容主要还是正则表达式。代码如下:
# -*- coding:utf-8 -*-
import urllib
import urllib2
import re
#工具类,用于去除一些链接之类的特殊标签
class Tool:
#去除图片链接
removeImage = re.compile('![]() ')
#去除
')
#去除
removeBR = re.compile('
')
#去除超链接
removeHref = re.compile('')
def replaceStrange(self,x):
x = re.sub(self.removeImage,"",x)
x = re.sub(self.removeBR,"\n",x)
x = re.sub(self.removeHref,"",x)
return x.strip()
#百度贴吧爬虫类
class BaiduTieba:
def __init__(self,baseUrl,seeLZ):
#帖子基址
self.baseUrl = baseUrl
#只看楼主seeLZ=1
self.seeLZ = '?see_lz='+str(seeLZ)
self.tool = Tool()
def getPage(self,pageNum):
try:
url = self.baseUrl + self.seeLZ + '&pn=' + str(pageNum)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
#print response.read()
return response.read().decode('utf-8')
except urllib2.URLError,e:
if hasattr(e,"reason"):
print e.reason
return None
def getTitle(self):
page = self.getPage(1)
pattern = re.compile('if
result:
print "success!"
print result.group()
else:
print "failed!"
def getContent(self,page):
#正则表达式匹配
pattern = re.compile('1
for item in items:
print '\n',floor,u"楼-----------------------------------------------------------------------------------"
print self.tool.replaceStrange(item)
floor += 1
print u"请输入帖子编号:"
baseURL = 'http://tieba.baidu.com/p/' + str(raw_input(u'http://tieba.baidu.com/p/'))
baidu = BaiduTieba(baseURL,1)
baidu.getContent(baidu.getPage(1))
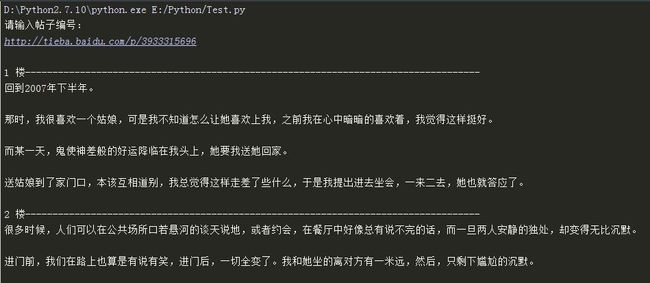
效果如图(扒一扒这些年朋友之上恋人未满的逗逼):