Java IO流
IO:
- 输入机制:允许程序读取外部数据(包括来自磁盘、光盘等存储设备的数据)、用户输入数据;
- 输出机制:允许程序记录运行状态,将程序数据输出到磁盘、光盘等存储设备中;
File:
File类是java.io包下代表与平台无关的文件和目录,不管是文件还是目录都是使用File来操作的,File能新建、删除和重命名文件和目录,File不能访问文件本身内容,若需访问文件内容本身,则需要使用输入/输出流;
| 构造方法摘要 | |
|---|---|
File(File parent, String child)根据 parent 抽象路径名和 child 路径名字符串创建一个新 File 实例。 |
|
File(String pathname)通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。 |
|
File(String parent, String child)根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。 |
|
File(URI uri)通过将给定的 file: URI 转换为一个抽象路径名来创建一个新的 File 实例。 |
|
| 方法摘要 | |
|---|---|
boolean |
canExecute()测试应用程序是否可以执行此抽象路径名表示的文件。 |
boolean |
canRead()测试应用程序是否可以读取此抽象路径名表示的文件。 |
boolean |
canWrite()测试应用程序是否可以修改此抽象路径名表示的文件。 |
int |
compareTo(File pathname)按字母顺序比较两个抽象路径名。 |
boolean |
createNewFile()当且仅当不存在具有此抽象路径名指定名称的文件时,不可分地创建一个新的空文件。 |
static File |
createTempFile(String prefix, String suffix)在默认临时文件目录中创建一个空文件,使用给定前缀和后缀生成其名称。 |
static File |
createTempFile(String prefix, String suffix, File directory)在指定目录中创建一个新的空文件,使用给定的前缀和后缀字符串生成其名称。 |
boolean |
delete()删除此抽象路径名表示的文件或目录。 |
void |
deleteOnExit()在虚拟机终止时,请求删除此抽象路径名表示的文件或目录。 |
boolean |
equals(Object obj)测试此抽象路径名与给定对象是否相等。 |
boolean |
exists()测试此抽象路径名表示的文件或目录是否存在。 |
File |
getAbsoluteFile()返回此抽象路径名的绝对路径名形式。 |
String |
getAbsolutePath()返回此抽象路径名的绝对路径名字符串。 |
File |
getCanonicalFile()返回此抽象路径名的规范形式。 |
String |
getCanonicalPath()返回此抽象路径名的规范路径名字符串。 |
long |
getFreeSpace()返回此抽象路径名指定的分区中未分配的字节数。 |
String |
getName()返回由此抽象路径名表示的文件或目录的名称。 |
String |
getParent()返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。 |
File |
getParentFile()返回此抽象路径名父目录的抽象路径名;如果此路径名没有指定父目录,则返回 null。 |
String |
getPath()将此抽象路径名转换为一个路径名字符串。 |
long |
getTotalSpace()返回此抽象路径名指定的分区大小。 |
long |
getUsableSpace()返回此抽象路径名指定的分区上可用于此虚拟机的字节数。 |
int |
hashCode()计算此抽象路径名的哈希码。 |
boolean |
isAbsolute()测试此抽象路径名是否为绝对路径名。 |
boolean |
isDirectory()测试此抽象路径名表示的文件是否是一个目录。 |
boolean |
isFile()测试此抽象路径名表示的文件是否是一个标准文件。 |
boolean |
isHidden()测试此抽象路径名指定的文件是否是一个隐藏文件。 |
long |
lastModified()返回此抽象路径名表示的文件最后一次被修改的时间。 |
long |
length()返回由此抽象路径名表示的文件的长度。 |
String[] |
list()返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中的文件和目录。 |
String[] |
list(FilenameFilter filter)返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
File[] |
listFiles()返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件。 |
File[] |
listFiles(FileFilter filter)返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
File[] |
listFiles(FilenameFilter filter)返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。 |
static File[] |
listRoots()列出可用的文件系统根。 |
boolean |
mkdir()创建此抽象路径名指定的目录。 |
boolean |
mkdirs()创建此抽象路径名指定的目录,包括所有必需但不存在的父目录。 |
boolean |
renameTo(File dest)重新命名此抽象路径名表示的文件。 |
boolean |
setExecutable(boolean executable)设置此抽象路径名所有者执行权限的一个便捷方法。 |
boolean |
setExecutable(boolean executable, boolean ownerOnly)设置此抽象路径名的所有者或所有用户的执行权限。 |
boolean |
setLastModified(long time)设置此抽象路径名指定的文件或目录的最后一次修改时间。 |
boolean |
setReadable(boolean readable)设置此抽象路径名所有者读权限的一个便捷方法。 |
boolean |
setReadable(boolean readable, boolean ownerOnly)设置此抽象路径名的所有者或所有用户的读权限。 |
boolean |
setReadOnly()标记此抽象路径名指定的文件或目录,从而只能对其进行读操作。 |
boolean |
setWritable(boolean writable)设置此抽象路径名所有者写权限的一个便捷方法。 |
boolean |
setWritable(boolean writable, boolean ownerOnly)设置此抽象路径名的所有者或所有用户的写权限。 |
String |
toString()返回此抽象路径名的路径名字符串。 |
URI |
toURI()构造一个表示此抽象路径名的 file: URI。 |
实例:
public void test(){
String path="C:/Users/Administrator/IdeaProjects/FUXI/src/file/TestFile.java";
File file=new File(path);
System.out.println("文件名称:" + file.getName());
System.out.println("文件是否存在:" + file.exists());
System.out.println("文件的相对路径:" + file.getPath());
System.out.println("文件的绝对路径:" + file.getAbsolutePath());
System.out.println("是否为可执行文件:" + file.canExecute());
System.out.println("文件可以读取:" + file.canRead());
System.out.println("文件可以写入:" + file.canWrite());
System.out.println("文件上级路径:" + file.getParent());
System.out.println("文件大小:" + file.length() + "B");
System.out.println("文件最后修改时间:" + new Date(file.lastModified()));
System.out.println("是否文件类型:" + file.isFile());
System.out.println("是否为文件夹:" + file.isDirectory());
}IO流:
Java的IO流是实现输入/出的基础,它可以方便地实现数据的输入/输出操作,Java中把不同的输入/输出源(键盘、文件、网络连接等)抽象表述为“流”,通过流的方式允许Java程序使用相同的方式来访问不同的输入/输出源,stram是从起源(source)到接收的(sink)的有序数据。
IO流的分类:
按照流的流向分:
- 输入流:只能从中读取数据,而不能向其写入数据;
- 输出流:只能向其写入数据,而不能从中读取数据;
按照操作单元分,可以分为字节流和字符流:
字节流和字符流的用法几乎完成全一样,区别在于字节流和字符流所操作的数据单元不同,字节流操作的单元是数据单元是8位的字节,字符流操作的是数据单元为16位的字符。
字节流主要是由InputStream和outPutStream作为基类,而字符流则主要有Reader和Writer作为基类。
按照流的角色分,可以分为节点流和处理流:
可以从/向一个特定的IO设备(磁盘、网络)读/写数据的流,称为节点流(低级流);当使用节点流进行输入和输出时,程序直接连接到实际的数据源,和实际的输入/输出节点连接;

处理流(高级流)则是用于一个已存在的流进行连接和封装,通过封装后的流来实现数据的读/写功能,
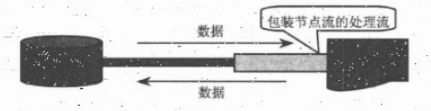
流的概念模型:
java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java Io流的40多个类都是从如下4个抽象类基类中派生出来的。
- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
处理流的功能主要体现在以下两方面:
- 性能的提高:主要以增加缓冲的方式来提供输入和输出的效率;
- 操作的便捷:处理流可能提供了一系列便捷的方法来一次输入和输出大批量的内容,而不是输入/输出一个或多个字节(字符);
处理流可以“嫁接”在任何已存在的流的基础之上,这就允许Java应用程序采用相同的代码,透明的方式来访问不同的输入和输出设备的数据流。
字节流和字符流:
InputStream/Reader:
是所有输入流的抽象基类,本身并不能创建实例来执行输入,但它们将成为所有输入流的模板,所以它们的方法是所有输入流都可使用的方法。
在InputStream里面包含如下3个方法。
- int read(); 从输入流中读取单个字节,返回所读取的字节数据(字节数据可直接转换为int类型)。
- int read(byte[] b)从输入流中最多读取b.length个字节的数据,并将其存储在字节数组b中,返回实际读取的字节数。
- int read(byte[] b,int off,int len); 从输入流中最多读取len个字节的数据,并将其存储在数组b中,放入数组b中时,并不是从数组起点开始,而是从off位置开始,返回实际读取的字节数。
在Reader中包含如下3个方法。
- int read(); 从输入流中读取单个字符,返回所读取的字符数据(字节数据可直接转换为int类型)。
- int read(char[] b)从输入流中最多读取b.length个字符的数据,并将其存储在字节数组b中,返回实际读取的字符数。
-
int read(char[] b,int off,int len); 从输入流中最多读取len个字符的数据,并将其存储在数组b中,放入数组b中时,并不是从数组起点开始,而是从off位置开始,返回实际读取的字符数。
InputStream和Reader都是抽象类,本身不能创建实例,但它们分别有一个用于读取文件的输入流:FileInputStream和FileReader,它们都是节点流——会直接和指定文件关联。
FileInputStream:
public class TestFileInputStream {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream=null;
try{
fileInputStream=new FileInputStream("C:\\Users\\Administrator\\IdeaProjects\\FUXI\\src\\file\\TestFileInputStream.java");
byte[] bytes=new byte[1024];
int readLine=0;
while ((readLine=fileInputStream.read(bytes))>0){
System.out.println(new String(bytes));
}
}catch (IOException e) {
e.printStackTrace();
}finally {
fileInputStream.close();
}
}
}FileReader:
public class TestFileReader {
public static void main(String[] args) throws IOException {
FileReader fileReader=null;
try{
fileReader=new FileReader("C:\\Users\\Administrator\\IdeaProjects\\FUXI\\src\\file\\TestFileReader.java");
char[] chars=new char[32];
int readLine=0;
while ((readLine=fileReader.read(chars))>0){
System.out.println(new String(chars));
}
}catch (IOException e){
e.printStackTrace();
}finally {
fileReader.close();
}
}
}OutputStream/Writer:
OutputStream和Writer的用法也非常相似,两个流都提供了如下三个方法:
- void write(int c); 将指定的字节/字符输出到输出流中,其中c即可以代表字节,也可以代表字符。
- void write(byte[]/char[] buf); 将字节数组/字符数组中的数据输出到指定输出流中。
- void write(byte[]/char[] buf, int off,int len ); 将字节数组/字符数组中从off位置开始,长度为len的字节/字符输出到输出流中。
因为字符流直接以字符作为操作单位,所以Writer可以用字符串来代替字符数组,即以String对象作为参数。Writer里面还包含如下两个方法。
- void write(String str); 将str字符串里包含的字符输出到指定输出流中。
- void write (String str, int off, int len); 将str字符串里面从off位置开始,长度为len的字符输出到指定输出流中。
FileOutputStream:
public class TestFileOutputStream {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream=null;
FileOutputStream fileOutputStream=null;
try{
fileInputStream=new FileInputStream("C:\\Users\\Administrator\\IdeaProjects\\FUXI\\src\\file\\TestFileOutputStream.java");
fileOutputStream=new FileOutputStream("C:/new.txt");
byte[] bytes=new byte[1024];
int readLine=0;
while ((readLine=fileInputStream.read(bytes))>0){
fileOutputStream.write(bytes,0,readLine);
}
}catch (IOException e){
e.printStackTrace();
}finally {
fileInputStream.close();
fileOutputStream.close();
}
}
}FileWriter:
public class TestFileWriter {
public static void main(String[] args) throws IOException {
FileWriter fileWriter=null;
try{
fileWriter=new FileWriter("C:/new1.txt");
fileWriter.write("answer");
}catch (IOException e){
e.printStackTrace();
}finally {
fileWriter.close();
}
}
}缓冲流(处理流):
BufferedInputStream/BufferedReader, BufferedOutputStream/BufferedWriter类在数据流流动的路径上增加了一个特定大小的数据缓冲区。数据缓冲区通过减少与read()和write()方法调用相对应的读取和写入的物理操作,从而提高了效率。
public class TestBufferStream {
public static void main(String[] args) throws IOException {
FileInputStream fileInputStream=null;
FileOutputStream fileOutputStream=null;
BufferedInputStream bufferedInputStream=null;
BufferedOutputStream bufferedOutputStream=null;
try{
fileInputStream=new FileInputStream("C:\\Users\\Administrator\\IdeaProjects\\FUXI\\src\\file\\TestBufferStream.java");
fileOutputStream=new FileOutputStream("C:/a.txt");
bufferedInputStream=new BufferedInputStream(fileInputStream,1024);
bufferedOutputStream=new BufferedOutputStream(fileOutputStream);
int readLine=0;
byte[] bytes=new byte[1024];
while ((readLine=bufferedInputStream.read(bytes))>0){
bufferedOutputStream.write(bytes,0,readLine);
}
}catch (IOException e){
e.printStackTrace();
}finally {
bufferedInputStream.close();
bufferedOutputStream.close();
}
}
}当我们使用处理流套接到节点流上的使用的时候,只需要关闭最上层的处理就可以了。java会自动帮我们关闭下层的节点流。
转换流:
InputStreamReader/OutputStreamWriter用于实现将字节流转换为字符流;
public class TestZhuanhuanStream {
public static void main(String[] args) throws IOException {
BufferedReader bufferedReader=null;
try{
//将字节流装换为字符流
InputStreamReader reader=new InputStreamReader(System.in);
bufferedReader=new BufferedReader(reader);
String buffer=null;
while ((buffer=bufferedReader.readLine())!=null){
if(buffer.equals("exit")){
System.exit(1);
}System.out.println(buffer);
}
}catch (IOException e){
e.printStackTrace();
}finally {
bufferedReader.close();
}
}
}对象序列化:
对象序列化的目标是将对象保存到磁盘中,或允许在网络中直接传输对象,对象序列化机制允许把内存中的Java对象转换为平台无关的二进制流,从而允许把这种二进制流持久保存在磁盘上,通过网络将这种二进制流传输到另一个网络节点,其它程序一旦获得该二进制流,都可以将其恢复为Java对象;
对象的序列化指将一个Java对象写入 IO流中,对象的反序列化指从IO流中恢复该对象;如果需要让某个对象支持序列化机制,必须让它的类是可序列化的,为了让某个类是可序列化的,该类必须实现Serializable接口或Externalizable接口;Serializable接口只是一个标记接口;
使用对象流实现序列化与反序列化:
Person类:
public class Peron implements Serializable {
private String name;
private int age;
public Peron(String name,int age){
this.name=name;
this.age=age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}序列化:
public class ObjectWrite {
public static void main(String[] args) throws IOException {
ObjectOutputStream objectOutputStream=null;
try{
objectOutputStream=new ObjectOutputStream(new FileOutputStream("C:/object1.tmp"));
Peron peron=new Peron("answer",20);
objectOutputStream.writeObject(peron);
}catch (IOException e){
e.printStackTrace();
}finally {
if(objectOutputStream!=null){
objectOutputStream.close();
}
}
}
}反序列化:
public class ObjectRead {
public static void main(String[] args) throws IOException {
ObjectInputStream objectInputStream=null;
try{
objectInputStream=new ObjectInputStream(new FileInputStream("C:/object.txt"));
Peron peron=(Peron) objectInputStream.readObject();
System.out.println(peron.getAge()+":"+peron.getName());
}catch (Exception e){
e.printStackTrace();
}finally {
if(objectInputStream!=null){
objectInputStream.close();
}
}
}
}对象引用的序列化:
如果某个类的属性类型不是基本类型或者String类型,而是一个引用类型,那么这个引用类必须是可序列化的,否则拥有该类型属性类是不可序列化的,
当一个对象被多次序列化时,Java序列化机制采用了一种特殊的序列化算法:
- 所有保存到磁盘中的对象都有一个序列化编号;
- 当程序试图序列化一个对象时,程序将先检查该对象是否已经被序列化过,只有当该对象未(在本次虚拟机中)被序列化过,系统才将该对象转换成字节序列并输出;
- 如果某个对象是已经序列化过的,程序将直接只是输出一个序列化编号,而不是再次序列化该对象;
当使用Java序列化机制序列化可变对象时需注意,只有当第一次调用writeObject方法来输出对象时才会将对象转换成字节序列,并写出到ObjectOutoutStream;在后面程序中如果该对象的属性发生了变化,即再次调用writeObject方法来输出对象时,改变后的属性不会被输出;
序列化注意事项:
- 被static修饰的属性不会被序列化;
- 对象的类名、属性都会被实例化,方法不会被序列化;
- 要保证 序列化对象所在类的属性也是可以被序列化;
- 当通过网络、文件进行序列化时,必须按照写入的顺序读取对象;
- 反序列化时必须有序列化对象时的class文件;
- 最好显示的声明serializable ID,因为在不同的JVM中,其默认可能不同,会造成反序列化失败;