系统学习机器学习之随机场(四)--CRF++源码分析
以下转自:http://www.cnblogs.com/pangxiaodong/archive/2011/11/21/2256264.html,简单介绍下CRF++的使用。
1. 简述
最近要应用CRF模型,进行序列识别。选用了CRF++工具包,具体来说是在VS2008的C#环境下,使用CRF++的windows版本。本文总结一下了解到的和CRF++工具包相关的信息。
参考资料是CRF++的官方网站:CRF++: Yet Another CRF toolkit,网上的很多关于CRF++的博文就是这篇文章的全部或者部分的翻译,本文也翻译了一些。
2. 工具包下载
第一,版本选择,当前最新版本是2010-05-16日更新的CRF++ 0.54版本,不过这个版本以前我用过一次好像运行的时候存在一些问题,网上一些人也说有问题,所以这里用的是2009-05-06: CRF++ 0.53版本。关于运行出错的信息有http://ir.hit.edu.cn/bbs/viewthread.php?action=printable&tid=7945为证。
第二,文件下载,这个主页上面只有最新的0.54版本的文件,网上可以搜索,不过不是资源不是很多,我在CSDN上面下载了一个CRF++0.53版本的,包含linux和windows版本,其要花掉10个积分。因为,我没有找到比较稳定、长期、免费的链接,这里上传一份这个文件:CRF++ 0.53 Linux和Windows版本。
补充:
目前见到的版本,大概是CRF++ 0.58.
3. 工具包文件

doc文件夹:就是官方主页的内容。
example文件夹:有四个任务的训练数据、测试数据和模板文件。
sdk文件夹:CRF++的头文件和静态链接库。
crf_learn.exe:CRF++的训练程序。
crf_test.exe:CRF++的预测程序
libcrfpp.dll:训练程序和预测程序需要使用的静态链接库。
实际上,需要使用的就是crf_learn.exe,crf_test.exe和libcrfpp.dll,这三个文件。
4. 命令行格式
4.1 训练程序
命令行:
% crf_learn template_file train_file model_file
这个训练过程的时间、迭代次数等信息会输出到控制台上(感觉上是crf_learn程序的输出信息到标准输出流上了),如果想保存这些信息,我们可以将这些标准输出流到文件上,命令格式如下:
% crf_learn template_file train_file model_file >> train_info_file
有四个主要的参数可以调整:
-a CRF-L2 or CRF-L1
规范化算法选择。默认是CRF-L2。一般来说L2算法效果要比L1算法稍微好一点,虽然L1算法中非零特征的数值要比L2中大幅度的小。
-c float
这个参数设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。这个参数可以调整过度拟合和不拟合之间的平衡度。这个参数可以通过交叉验证等方法寻找较优的参数。
-f NUM
这个参数设置特征的cut-off threshold。CRF++使用训练数据中至少NUM次出现的特征。默认值为1。当使用CRF++到大规模数据时,只出现一次的特征可能会有几百万,这个选项就会在这样的情况下起到作用。
-p NUM
如果电脑有多个CPU,那么那么可以通过多线程提升训练速度。NUM是线程数量。
带两个参数的命令行例子:
% crf_learn -f 3 -c 1.5 template_file train_file model_file
4.2 测试程序
命令行:
% crf_test -m model_file test_files
有两个参数-v和-n都是显示一些信息的,-v可以显示预测标签的概率值,-n可以显示不同可能序列的概率值,对于准确率,召回率,运行效率,没有影响,这里不说明了。
与crf_learn类似,输出的结果放到了标准输出流上,而这个输出结果是最重要的预测结果信息(测试文件的内容+预测标注),同样可以使用重定向,将结果保存下来,命令行如下。
% crf_test -m model_file test_files >> result_file
5. 文件格式
5.1 训练文件
下面是一个训练文件的例子:

训练文件由若干个句子组成(可以理解为若干个训练样例),不同句子之间通过换行符分隔,上图中显示出的有两个句子。每个句子可以有若干组标签,最后一组标签是标注,上图中有三列,即第一列和第二列都是已知的数据,第三列是要预测的标注,以上面例子为例是,根据第一列的词语和和第二列的词性,预测第三列的标注。
当然这里有涉及到标注的问题,这个就是很多paper要研究的了,比如命名实体识别就有很多不同的标注集。这个超出本文范围。
5.2 测试文件
测试文件与训练文件格式自然是一样的,用过机器学习工具包的这个一般都理解吧。
与SVM不同,CRF++没有单独的结果文件,预测结果通过标准输出流输出了,因此前面4.2节的命令行中,将结果重定向到文件中了。结果文件比测试文件多了一列,即为预测的标签,我们可以计算最后两列,一列的标注的标签,一列的预测的标签,来得到标签预测的准确率。
5.3 模板文件
5.3.1 模板基础
模板文件中的每一行是一个模板。每个模板都是由%x[row,col]来指定输入数据中的一个token。row指定到当前token的行偏移,col指定列位置。
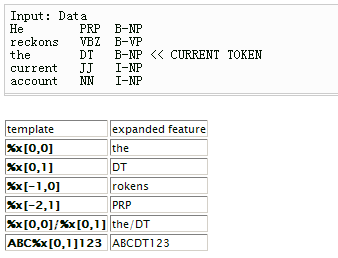
由上图可见,当前token是the这个单词。%x[-2,1]就就是the的前两行,1号列的元素(注意,列是从0号列开始的),即为PRP。
5.3.2 模板类型
有两种类型的模板,模板类型通过第一个字符指定。
Unigram template: first character, 'U'
当给出一个"U01:%x[0,1]"的模板时,CRF++会产生如下的一些特征函数集合(func1 ... funcN) 。

这几个函数我说明一下,%x[0,1]这个特征到前面的例子就是说,根据词语(第1列)的词性(第2列)来预测其标注(第3列),这些函数就是反应了训练样例的情况,func1反映了“训练样例中,词性是DT且标注是B-NP的情况”,func2反映了“训练样例中,词性是DT且标注是I-NP的情况”。
模板函数的数量是L*N,其中L是标注集中类别数量,N是从模板中扩展处理的字符串种类。
Bigram template: first character, 'B'
这个模板用来描述二元特征。这个模板会自动产生当前output token和前一个output token的合并。注意,这种类型的模板会产生L * L * N种不同的特征。
Unigram feature 和 Bigram feature有什么区别呢?
unigram/bigram很容易混淆,因为通过unigram-features也可以写出类似%x[-1,0]%x[0,0]这样的单词级别的bigram(二元特征)。而这里的unigram和bigram features指定是uni/bigrams的输出标签。
unigram: |output tag| x |all possible strings expanded with a macro|
bigram: |output tag| x |output tag| x |all possible strings expanded with a macro|
这里的一元/二元指的就是输出标签的情况,这个具体的例子我还没看到,example文件夹中四个例子,也都是只用了Unigram,没有用Bigarm,因此感觉一般Unigram feature就够了。
5.3.3 模板例子
这是CoNLL 2000的Base-NP chunking任务的模板例子。只使用了一个bigram template ('B')。这意味着只有前一个output token和当前token被当作bigram features。“#”开始的行是注释,空行没有意义。

6. 样例数据
example文件夹中有四个任务,basenp,chunking,JapaneseNE,seg。前两个是英文数据,后两个是日文数据。第一个应该是命名实体识别,第二个应该是分词,第三个应该是日文命名实体识别,第四个不清楚。这里主要跑了一下前两个任务,后两个是日文的搞不懂。
根据任务下面的linux的脚步文件,我写了个简单的windows批处理(其中用重定向保存了信息),比如命名为exec.bat,跑了一下。批处理文件放在要跑的任务的路径下就行,批处理文件内容如下:
..\..\crf_learn -c 10.0 template train.data model >> train-info.txt
..\..\crf_test -m model test.data >> test-info.txt
这里简单解释一下批处理,批处理文件运行后的当前目录就是该批处理文件所在的目录(至少我的是这样,如果不是,可以使用cd %~dp0这句命令,~dp0表示了“当前盘符和路径”),crf_learn和crf_test程序在当前目录的前两级目录上,所以用了..\..\。
下面这个转自:http://www.hankcs.com/ml/crf-code-analysis.html,(我做了部分修改)
本文按照调用顺序抽丝剥茧地分析了CRF++的代码,详细注释了主要函数,并指出了代码与理论公式的对应关系。内容包括拟牛顿法的目标函数、梯度、L2正则化、L-BFGS优化、概率图构建、前向后向算法、维特比算法等。

背景知识请参考系统学习机器学习之随机场(二)--MRF,CRF。
训练
先从训练开始说起吧
- /**
- * 命令行式训练
- * @param argc 命令个数
- * @param argv 命令数组
- * @return 0表示正常执行,其他表示错误
- */
- int crfpp_learn(int argc, char **argv)
该函数解析命令行之后调用:
- /**
- * 训练CRF模型
- * @param param 参数
- * @return
- */
- int crfpp_learn(const Param ¶m)
该函数会调用:
- /**
- * 训练
- * @param templfile 模板文件
- * @param trainfile 训练文件
- * @param modelfile 模型文件
- * @param textmodelfile 是否输出文本形式的模型文件
- * @param maxitr 最大迭代次数
- * @param freq 特征最低频次,也就是说,在某特征出现的次数超过该值,才进入模型,默认为1,即只要出现就进入模型。
- * @param eta 收敛阈值
- * @param C cost-factor 实际定义的是权重共享系数
- * @param thread_num 线程数
- * @param shrinking_size 该参数在CRF算法中没用,在MIRA算法中使用,也就是与CRF模型无关,可以不考虑。
- * @param algorithm 训练算法
- * @return
- */
- bool learn(const char *templfile,
- const char *trainfile,
- const char *modelfile,
- bool textmodelfile,
- size_t maxitr,
- size_t freq,
- double eta,
- double C,
- unsigned short thread_num,
- unsigned short shrinking_size,
- int algorithm);
该函数先读取特征模板和训练文件
- /**
- * 打开配置文件和训练文件
- * @param template_filename
- * @param train_filename
- * @return
- */
- bool open(const char *template_filename, const char *train_filename);
这个open方法并没有构建训练实例,而是简单地解析特征模板和统计标注集:
- /**
- * 读取特征模板文件
- * @param filename
- * @return
- */
- bool openTemplate(const char *filename);
- /**
- * 读取训练文件中的标注集
- * @param filename
- * @return
- */
- bool openTagSet(const char *filename);
这里补充一下:
每个句子表示一个样例,每个样例中的单词+标注,作为一个token。这里在open结束后,系统开始针对每个样例中的每个token,映射特征函数。比如例子中,有一个特征模板有19个特征函数,那么任何一个样子(句子)中的任何一个单词+标注就有19个特征。所有这些特征全部综合存储在feature_cache中,你可以把这个cache里理解为一个二维缓存,其中,水平方向为样本类别,也就是Y集,例如该例子中Y有14个元素,也就是水平方向宽度为14,则ID每次针对一元模板增加14,也就是在相同水平位置对应的下一个垂直位置放置。最后整个cache就是一个水平为Y集,垂直为tokent特征集X的缓存。而该缓存的元素值对应特征出现的次数(因为要对所有样例的所有token的所有特征函数统计)。需要指出的是,特征函数和ID之间的关系是预先确定好的,例如特征函数作用后结果为U00:B-2,则直接找到相应编码表中的B-2对应的index即可,这个表我也不是很清楚,因为是分词标注领域的一个标准。
TaggerImpl存储训练样例,x_存储相应的output序列,result_存储相应的状态序列,answer_存储模型算出来的状态序列;为了实现多线程并发处理,另外存储了处理该TaggerImpl的线程thread_id_;output序列中的每一个token都对应一个feature集合,整个output序列对应了feature集合的序列,系统将所有训练样例的feature集合顺序存储在一个feature_cache中,因此在每一个TaggerImpl中保存了自己的feature序列在feature_cache中偏移量feature_id_,而这个feature_cache存在于FeatureIndex对象中。系统中所有的TaggerImpl都共享一个FeatureIndex对象;为了DP编程的方便,又包含一个Node二维数组,横轴对应output中的每一个token,纵轴代表系统状态集合中的每一个状态。Node存储DP中的每一个状态,包括alpha,beta,verterbi路径前驱等。
回到learn方法中来,做完了这些诸如IO和参数解析之后,learn方法会根据算法参数的不同而调用不同的训练算法。取最常用的说明如下:
- /**
- * CRF训练
- * @param x 句子列表
- * @param feature_index 特征编号表
- * @param alpha 特征函数的代价
- * @param maxitr 最大迭代次数
- * @param C cost factor
- * @param eta 收敛阈值
- * @param shrinking_size 未使用
- * @param thread_num 线程数
- * @param orthant 是否使用L1范数
- * @return 是否成功
- */
- bool runCRF(const std::vector
- float C, double eta, unsigned short shrinking_size, unsigned short thread_num, bool orthant)
计算梯度,
补充:

需要注意的是,CRF++实现的是线性链式CRF。主要区别在于势函数的计算不同,其他相同。计算梯度主要的方式是,经验分布的数学期望与模型的条件概率的数学期望的差,再加上正则项,经验分布的数学期望为训练数据集中随机变量 (x,y)满足特征约束的个数,模型的条件概率的数学期望的计算实质上是计算条件概率p(y|x,alpha)。因此,算法主要就是计算条件概率。
创建多个CRFEncoderThread,平均地将句子分给每个线程。每个线程的工作其实只是计算梯度:
- /**
- * 计算梯度
- * @param expected 梯度向量
- * @return 损失函数的值
- */
- double TaggerImpl::gradient(double *expected)
梯度计算时,先构建网格:
- void TaggerImpl::buildLattice()
由于CRF是概率图模型,所以有一些图的特有概念,如顶点和边:
- /**
- * 图模型中的节点
- */
- struct Node
- /**
- * 边
- */
- struct Path
buildLattice方法调用rebuildFeatures对每个时刻的每个状态分别构造边和顶点,实际上是条件概率的矩阵计算:
- for (size_t cur = 0; cur < tagger->size(); ++cur)
- {
- const int *f = (*feature_cache)[fid++];
- for (size_t i = 0; i < y_.size(); ++i)
- {
- Node *n = allocator->newNode(thread_id);
- n->clear();
- n->x = cur;
- n->y = i;
- n->fvector = f;
- tagger->set_node(n, cur, i);
- }
- }
- for (size_t cur = 1; cur < tagger->size(); ++cur)
- {
- const int *f = (*feature_cache)[fid++];
- for (size_t j = 0; j < y_.size(); ++j)
- {
- for (size_t i = 0; i < y_.size(); ++i)
- {
- Path *p = allocator->newPath(thread_id);
- p->clear();
- p->add(tagger->node(cur - 1, j), tagger->node(cur, i));
- p->fvector = f;
- }
- }
- }
这也就是大家经常看到的类似如下的图:

补充下:
这里采用矩阵方式计算条件概率,对于一阶线性链式CRF,在图模型中增加起始Y0,和结束Yn+1,Yi-1 为Y',Yi为y,定义一组矩阵{Mi(x)|i = 1, 2, ......n+1},其中每个Mi(x)是一个y*y阶随机变量矩阵,矩阵中每个元素为:
图示如下:

则条件概率为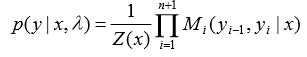 ,其中归一化:
,其中归一化: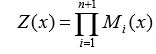
然后计算每个节点和每条边的代价(也就是特征函数乘以相应的权值,简称代价):
- /**
- * 计算状态特征函数的代价
- * @param node 顶点
- */
- void FeatureIndex::calcCost(Node *n) const
- {
- n->cost = 0.0;
- #define ADD_COST(T, A) \
- do { T c = 0; \
- for (const int *f = n->fvector; *f != -1; ++f) { c += (A)[*f + n->y]; } \
- n->cost =cost_factor_ *(T)c; } while (0)
- if (alpha_float_)
- {
- ADD_COST(float, alpha_float_);
- }
- else
- {
- ADD_COST(double, alpha_);
- }
- #undef ADD_COST
- }
- /**
- * 计算转移特征函数的代价
- * @param path 边
- */
- void FeatureIndex::calcCost(Path *p) const
- {
- p->cost = 0.0;
- #define ADD_COST(T, A) \
- { T c = 0.0; \
- for (const int *f = p->fvector; *f != -1; ++f) { \
- c += (A)[*f + p->lnode->y * y_.size() + p->rnode->y]; \
- } \
- p->cost =cost_factor_*(T)c; }
- if (alpha_float_)
- {
- ADD_COST(float, alpha_float_);
- }
- else
- {
- ADD_COST(double, alpha_);
- }
- }
其中fvector是当前命中特征函数的起始id集合,对于每个起始id,都有连续标签个数种y值;n->y是当前时刻的标签,由于每个特征函数都必须同时接受x和y才能决定输出1或0,所以要把两者加起来才能确定最终特征函数的id。用此id就能在alpha向量中取到最终的权值,将权值累加起来,乘以一个倍率(也就是所谓的代价参数cost_factor),得到最终的代价cost。
对于边来说,也是类似的,只不过对每个起始id,都有连续标签个数平方种y值组合。
这部分对应
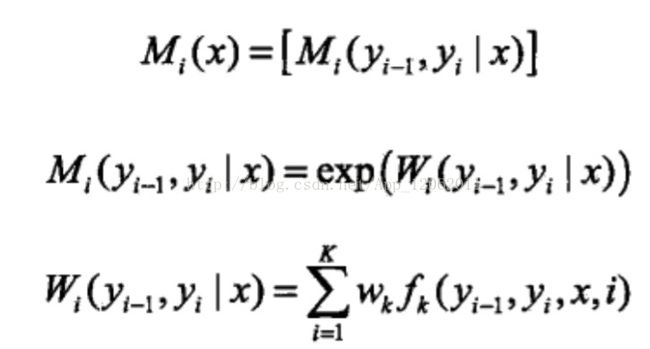
需要强调的是:算法内部对于exp没有计算,实际上,所有关于exp{F}的计算,都是只计算F,而在实际使用中,exp{F}参与计算时,直接采用log形式。例如下面的前向算法中,要计算两个expX1,expX2的乘积,则直接用log(X1+X2)表示,代码直接计算X1+X2
前向后向算法
网格建完了,就可以在这个图上面跑前向后向算法了:
- /**
- * 前向后向算法
- */
- void forwardbackward();
该方法依次计算前后向概率:
- for (int i = 0; i < static_cast
(x_.size()); ++i) - {
- for (size_t j = 0; j < ysize_; ++j)
- {
- node_[i][j]->calcAlpha();
- }
- }
- for (int i = static_cast
(x_.size() - 1); i >= 0; --i) - {
- for (size_t j = 0; j < ysize_; ++j)
- {
- node_[i][j]->calcBeta();
- }
- }
计算前向概率的具体实现是:
- void Node::calcAlpha()
- {
- alpha = 0.0;
- for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it)
- {
- alpha = logsumexp(alpha, (*it)->cost + (*it)->lnode->alpha, (it == lpath.begin()));
- }
- alpha += cost;
- }
其中cost是我们刚刚计算的当前节点的M_i(x),而alpha则是当前节点的前向概率。lpath是入边,如代码和图片所示,一个顶点可能有多个入边。
对应:

后向概率同理略过。
前后向概率都有了之后,计算规范化因子:
- Z_ = 0.0;
- for (size_t j = 0; j < ysize_; ++j)
- {
- Z_ = logsumexp(Z_, node_[0][j]->beta, j == 0);
- }
对应着

关于函数logsumexp的意义,请参考《计算指数函数的和的对数》。
于是完成整个前后向概率的计算。
期望值的计算
节点期望值
所谓的节点期望值指的是节点对应的状态特征函数关于条件分布p(Y|X)的数学期望。
- for (size_t i = 0; i < x_.size(); ++i)
- {
- for (size_t j = 0; j < ysize_; ++j)
- {
- node_[i][j]->calcExpectation(expected, Z_, ysize_);
- }
- }
calcExpectation具体实现是:
- /**
- * 计算节点期望
- * @param expected 输出期望
- * @param Z 规范化因子
- * @param size 标签个数
- */
- void Node::calcExpectation(double *expected, double Z, size_t size) const
- {
- const double c = std::exp(alpha + beta - cost - Z);
- for (const int *f = fvector; *f != -1; ++f)
- {
- expected[*f + y] += c;
- }
- for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it)
- {
- (*it)->calcExpectation(expected, Z, size);
- }
- }
第一个for对应下式的求和
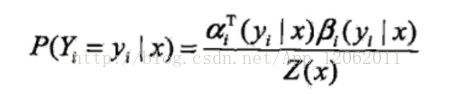
概率求和意味着得到期望。
第二个for对应边的期望值。
边的期望值
所谓边的期望指的是边对应的转移特征函数关于条件分布p(Y|X)的数学期望。
- /**
- * 计算边的期望
- * @param expected 输出期望
- * @param Z 规范化因子
- * @param size 标签个数
- */
- void Path::calcExpectation(double *expected, double Z, size_t size) const
- {
- const double c = std::exp(lnode->alpha + cost + rnode->beta - Z);
- for (const int *f = fvector; *f != -1; ++f)
- {
- expected[*f + lnode->y * size + rnode->y] += c;
- }
- }
对应下式的求和

这样就得到了条件分布的数学期望:

梯度计算
- for (size_t i = 0; i < x_.size(); ++i)
- {
- for (const int *f = node_[i][answer_[i]]->fvector; *f != -1; ++f)
- {
- --expected[*f + answer_[i]];
- }
- s += node_[i][answer_[i]]->cost; // UNIGRAM cost
- const std::vector
- for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it)
- {
- if ((*it)->lnode->y == answer_[(*it)->lnode->x])
- {
- for (const int *f = (*it)->fvector; *f != -1; ++f)
- {
- --expected[*f + (*it)->lnode->y * ysize_ + (*it)->rnode->y];
- }
- s += (*it)->cost; // BIGRAM COST
- break;
- }
- }
- }
–expected表示模型期望(条件分布)减去观测期望,得到目标函数的梯度:

有人可能要问了,expected的确存的是条件分布的期望,但观测期望还没计算呢,把条件分布的期望减一是干什么?
这是因为对观测数据(训练数据)来讲,它一定是对的,也就是在y!=answer_[i]的时候概率为0,在y=answer_[i]的时候概率为1,乘以特征函数的输出1,就等于1,这就是观测期望。也就是上面说的,训练数据中(x,y)出现的次数。
维特比算法
紧接着gradient函数还顺便调了一下TaggerImpl::viterbi:
- void TaggerImpl::viterbi()
- {
- for (size_t i = 0; i < x_.size(); ++i)
- {
- for (size_t j = 0; j < ysize_; ++j)
- {
- double bestc = -1e37;
- Node *best = 0;
- const std::vector
- for (const_Path_iterator it = lpath.begin(); it != lpath.end(); ++it)
- {
- double cost = (*it)->lnode->bestCost + (*it)->cost + node_[i][j]->cost;
- if (cost > bestc)
- {
- bestc = cost;
- best = (*it)->lnode;
- }
- }
- node_[i][j]->prev = best;
- node_[i][j]->bestCost = best ? bestc : node_[i][j]->cost;
- }
- }
- double bestc = -1e37;
- Node *best = 0;
- size_t s = x_.size() - 1;
- for (size_t j = 0; j < ysize_; ++j)
- {
- if (bestc < node_[s][j]->bestCost)
- {
- best = node_[s][j];
- bestc = node_[s][j]->bestCost;
- }
- }
- for (Node *n = best; n; n = n->prev)
- {
- result_[n->x] = n->y;
- }
- cost_ = -node_[x_.size() - 1][result_[x_.size() - 1]]->bestCost;
- }
其中prev构成一个前驱数组,在动态规划结束后通过prev回溯最优路径的标签y,存放于result数组中。
跑viterbi算法的目的是为了评估当前模型的准确度,以辅助决定是否终止训练。关于Viterbi算法,可以参考:系统学习机器学习之马尔科夫假设(一)--HMM
正则化
为了防止过拟合,CRF++采用了L1或L2正则化:
- if (orthant)
- { // L1
- for (size_t k = 0; k < feature_index->size(); ++k)
- {
- thread[0].obj += std::abs(alpha[k] / C);
- if (alpha[k] != 0.0)
- {
- ++num_nonzero;
- }
- }
- }
- else
- {
- num_nonzero = feature_index->size();
- for (size_t k = 0; k < feature_index->size(); ++k)
- {
- thread[0].obj += (alpha[k] * alpha[k] / (2.0 * C));
- thread[0].expected[k] += alpha[k] / C;
- }
- }
以L2正则为例,L2正则在目标函数上加了一个正则项:
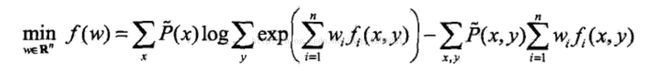 +
+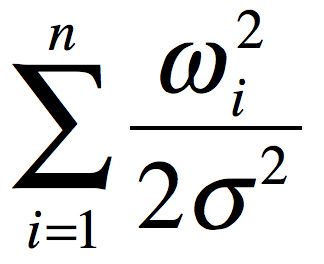
其中,σ是一个常数,在CRF++中其平方被称作cost-factor,1/2*σ^2控制着惩罚因子的强度。可见要最小化目标函数,正则化项也必须尽量小才行。模型参数的平方和小,其复杂度就低,于是就不容易过拟合。关于L1、L2正则化推荐看Andrew Ng的ML公开课。
目标函数加了正则项之后,梯度顺理成章地也应加上正则项的导数:
+Wi/σ^2
这也就是代码中为什么要自加这两项的原因了:
- thread[0].obj += (alpha[k] * alpha[k] / (2.0 * C));
- thread[0].expected[k] += alpha[k] / C;
L-BFGS优化
梯度和损失函数有了,之后就是通用的凸函数LBFGS优化了。CRF++直接将这些参数送入一个LBFGS模块中:
- if (lbfgs.optimize(feature_index->size(), &alpha[0], thread[0].obj, &thread[0].expected[0], orthant, C) <=
- 0)
- {
- return false;
- }
据说这个模块是用一个叫f2c的工具从FORTRAN代码转成的C代码,可读性并不好,也就不再深入了。
- // lbfgs.c was ported from the FORTRAN code of lbfgs.m to C
- // using f2c converter
- //
- // http://www.ece.northwestern.edu/~nocedal/lbfgs.html
有兴趣的话看看《数值优化:理解L-BFGS算法》即可。
预测
预测就简单多了,主要对应下列方法:
- bool TaggerImpl::parse()
- {
- CHECK_FALSE(feature_index_->buildFeatures(this)) << feature_index_->what();
- if (x_.empty())
- {
- return true;
- }
- buildLattice();
- if (nbest_ || vlevel_ >= 1)
- {
- forwardbackward();
- }
- viterbi();
- if (nbest_)
- {
- initNbest();
- }
- return true;
- }
主要的方法也就是建立网格和维特比这两个,由于前面训练的时候已经分析过,这里就不再赘述了。
Reference
![]() crf-tutorial.pdf
crf-tutorial.pdf
![]() 条件随机场理论综述.pdf
条件随机场理论综述.pdf
http://mi.eng.cam.ac.uk/~cz277/doc/Slides-CRFASR-CSLT.pdf
http://blog.sina.com.cn/s/blog_a6962c6401016gob.html