人脸检测(十二)--DDFD算法
转自:blog.csdn.net/qq_14845119/article/details/52564519
DDFD(Deep Dense Face Detector)是一种基于AlexNet进行微调(finetune)改进的一种深度学习的网络模型。是雅虎公司2015年的作品,并发表在了cvpr,论文名为Multi-view Face Detection Using Deep Convolutional Neural Networks。可以实现基于多角度,遮挡,关照下的人脸检测。是一种unconstrain的人脸检测算法。
传统的人脸检测途径有3种:
(1)基于Cascade级联分类器的人脸检测,例如Viola Jones,NPD(Normalized Pixel Difference)等。
(2)基于DPM(deformable part models)的人脸检测,即将人脸分割成好几个部件进行检测的算法,例如DPM。
(3)基于神经网络的方法,例如,DDFD,RCNN等、
该模型由5个卷积层,3个全连接层组成,在最后一个全连接层直接输出,没有经过SVM分类器处理。网络结构face_full_conv.prototxt如下所示:
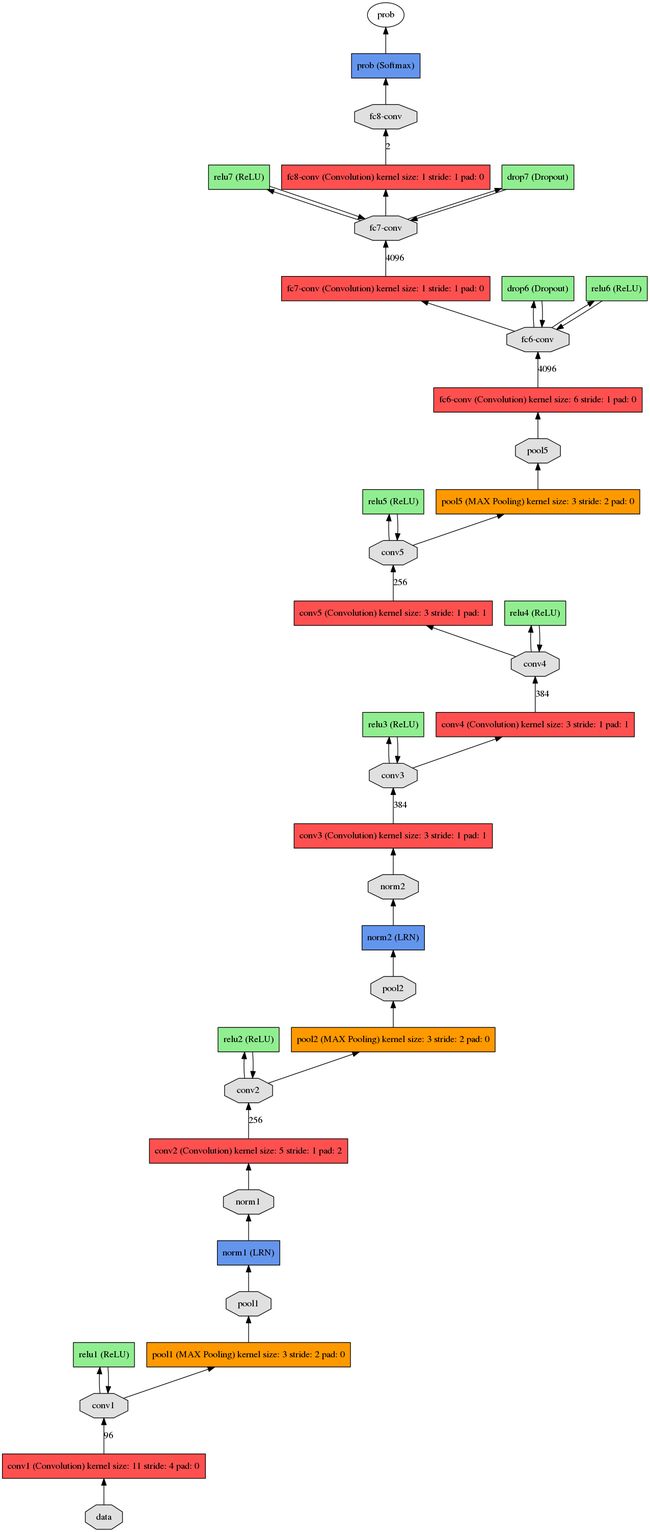
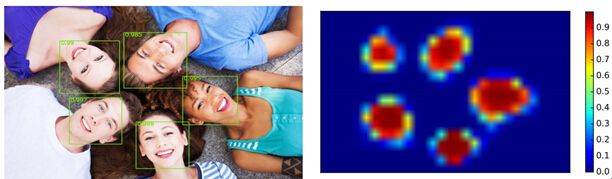
从下面左图的人脸检测,可以看出,DDFD对各种姿势有很强的抵抗能力,从右侧的能量图(heat-map),也叫特征图(就像ITTI模型提取的那样),可以看出对于正前方的人脸有着最高的score,而随着偏转角度、姿势的变换越大,score就会越低,但是都可以满足高于周围的背景区域,从而实现多角度,多姿态的人脸检测。
程序github网址https://github.com/watersink/caf_face_detection,模型文件下载地址https://pan.baidu.com/s/1i4Qokhn
由于原作者没有给出其CMakelists,这里贴出我自己的CMakeLists,将其中cafferoot替换为自己的caffe根目录,opencvroot替换为自己的opencv根目录。
[plain] view plain copy
- cmake_minimum_required (VERSION 2.8)
- project (caf_face_detection)
- add_executable(caf_face_detection data_transformer.hpp face_detection.cpp face_detection.hpp main.cpp)
- include(CheckCXXCompilerFlag)
- CHECK_CXX_COMPILER_FLAG("-std=c++11" COMPILER_SUPPORTS_CXX11)
- CHECK_CXX_COMPILER_FLAG("-std=c++0x" COMPILER_SUPPORTS_CXX0X)
- if(COMPILER_SUPPORTS_CXX11)
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
- elseif(COMPILER_SUPPORTS_CXX0X)
- set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++0x")
- else()
- message(STATUS "The compiler ${CMAKE_CXX_COMPILER} has no C++11 support. Please use a different C++ compiler.")
- endif()
- include_directories ( /cafferoot/include
- /usr/local/include
- /usr/local/cuda/include
- /usr/include)
- target_link_libraries(caf_face_detection / cafferoot /build/lib/libcaffe.so
- /usr/local/lib/libglog.so.0
- /usr/lib/x86_64-linux-gnu/libboost_system.so
- /opencvroot /build/lib/libopencv_highgui.so
- / opencvroot /build/lib/libopencv_core.so
- / opencvroot /build/lib/libopencv_imgproc.so
- )
运行该程序会发现,在程序的运行过程中,其会自动的跟新face_full_conv2.prototxt,有种增量学习(incremental learning)和在线学习(online learning)的味道,网络结构face_full_conv2.prototxt如下
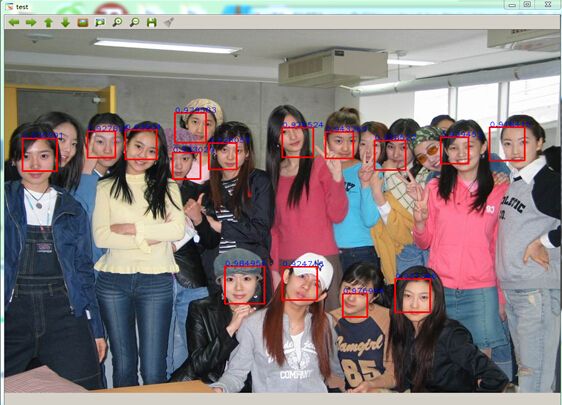
程序运行效果如下:
补充:
1- 构建深度学习训练数据集
AFLW原始数据集:[百度云链接——链接:http://pan.baidu.com/s/1czZXme 密码:rw3g)
尺寸归一化为224×224的正负训练样本:百度云链接——密码:zf98
深度学习需要大量的数据,否则根本无法发挥出深度神经网络的优势。雅虎的文章中为了训练一个性能优异的人脸分类器,制作了超过20W的正样本(人脸)和超过2000W的负样本(非人脸)。此外,为了有效解决遮挡、不同角度、光照的人脸检测,文章还强调训练样本中应包含大量这类的样本。这就需要应用一些特殊Data Augmentation方法,一方面扩充训练样本,另一方面改善样本的分布(即增加那些存在遮挡、倾斜、偏转等的人脸样本)。通常,我们可以采用随机平移、翻转、随机旋转、泛红泛绿等操作来完成上述扩充,但是需要注意人为的添加一些遮挡或者噪声通常是不可取的,因为深度网络很有可能学习到这些人为的“操作”。
1-1 制作训练正样本
我和原文一样,使用了AFLW数据集作为正负样本的来源。AFLW数据集中有大概2.1W张图片(基本都是高清的图片),其中标记了大概2.4W个人脸的矩形框、3维旋转角度、是否遮挡、是否戴眼镜等信息。因此,生成正样本时,我的主要操作就是将原有的矩形框进行随机的平移和旋转,如果操作之后的矩形框和原来矩形框相交面积比(IOU)大于某个阈值(如,我使用了0.64),那么就可以认为经过“采样”得到了一个新的正样本。如果原矩形框下的人脸是存在遮挡或者戴眼镜或者低头仰头的,那么“采样”的次数就会加倍。
- 关于正样本IOU阈值,原文设定的是0.5,我觉得这不是一个很好的数值。首先,AFLW数据集中标定的矩形框也不是特别准确,如果IOU太小,很容易生成较多的弱正样本,一方面这将增加未来训练分类器的难度,另一方面实际检测的时候也会在目标周围生成许多影响我们判断的矩形框(这一点后面会再次说明)。但是,IOU阈值过大也不好,因为这将降低未来我们对缺失人脸(部分人脸)的检测率。
1-2 制作训练负样本
制作负样本时,我设定了一个新的IOU阈值为0.1,然后对整个图像进行滑动窗口,如果窗口与原人脸矩形框的相交面积比小于0.1,就认为该窗口为负样本。窗口大小和滑动步长是根据图片大小来确定的,平均下来一张图片会滑动产生200个窗口,最终被认定为负样本的大概有120左右。
- 需要特别说明的是,AFLW数据集中存在这样的问题:一张图片中有多个人,但只标注了少数几个明显的目标;背景存在密集人群。这将导致我们滑动窗口产生的负样本中包含一些“正样本”。因此,对于负样本我们需要人工审核一遍来剔除那些“异常”。(因为我是一个人,而且还在上课,这部分剔除工作就花费了我半个月之多 T_T)
最终,我获得了352240的正样本和1600128的负样本(负样本本来有200W+,但我没有时间全部校验一遍了)。下面看几个正负样本的例子。
2- 训练一个深度人脸分类器
训练一个深度人脸分类器,也就是利用深度卷积神经网络训练一个图片二分类器,该分类器可以将输入图片分类为人脸或者非人脸。考虑到人脸检测的召回率和准确率以及时间花费,下面我尝试了多种网络结构。
2-1 ImageNet或者AlexNet网络
原文作者是在AlexNet上进行finetune的。AlexNet的输入图片尺寸是227×227,ImageNet的输入图片尺寸是224×224,二者的结构类似。以ImageNet网络为例,该网络共有8层,包含5个卷积层和3个全连接层(某些层后面还跟有pooling层和LRN层)。整个网络下来,有大概60millon 个参数,65W个神经元,其caffemodel大概有220M之大。
下面说一下,实际使用ImageNet模型做人脸和非人脸分类的感受:
- 模型太大,我实际用的caffemodel大概有225M大小,这也就导致运行模型时需要很大的系统内存,同时也导致时间花费增大。我用笔记本4G内存,跑这个模型基本无望。
- 输入图片尺寸太大,ImageNet要求输入224×224大小的图片,这也就意味着如果你需要检测到最小40×40左右大小的人脸时,你必须首先将你的图片放大至少5倍。这将带来更大的内存消耗和时间花费。
2-2 Cifar10网络
这里尝试了Cifar10-quick网络结构,该网络输入图片尺寸为32×32,包含3个卷积层和2个全连接层(某些层后面有pooling层)。最终的caffemodel大小不足600K,是一个轻量级的网络模型。
- 模型过小,分类能力不足。
2-3 NIN_Cifar10网络
NIN,也即是Network in Network. 。这篇文章,主要讲
- 传统的线性卷积+非线性激活的方式不能很好地描述一个高度非线性的图像分类空间;
- 在每一层网络之间添加一个具有良好非线性表示能力的“多层感知机”可以改善上述问题。
图示如下: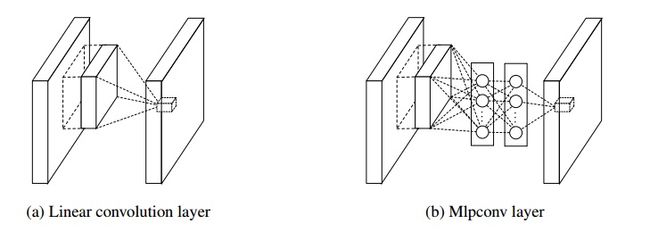
因为每层之间又添加了一个“多层感知机”网络,因此称为Network in Network.
其实,这个方法只是名字叫的特别好听,其本质只不过是加深了网络深度,但确实又是work的(关于这一点,大家可以通过查看NIN模型的train_val.prototxt来认识)
NIN_Cifar10的cafemodel大小约3M,但在测试集上的准确率要高于单纯的Cifar10,接近ImageNet的测试准确率。
2-4 自定义滑窗网络SlipW
这是我自己定义的一个网络结构,输入大小32×32,caffemodel大小约2.2M,测试集分类准确率97.2%,接近NIN_Cifar10的表现。为什么我最终要自己设计这样一个名为“滑窗”的网络?接下来我将说明原因。
将一个人脸分类器升级为一个人脸检测器的最简单直接的方法就是滑动窗口。但是,假如我的待检测图片大小为640×480,当以16的步长去滑动32×32的窗口时,那么将产生39×29=1131个窗口,如果把这些窗口一个一个去送到神经网络中做分类,那么可想而知效率会有多低。为了加快这个滑窗检测的过程,有人采用了下面的一种“全卷积”网络的方法:
2-4-1 全卷积网络
了解卷积神经网络的都应该知道,在卷积层中有“卷积核大小:kernel_size”、“卷积步长:stride”等参数。大家是否觉得卷积整个图像的过程和滑窗有点类似?于是,有人就从这个角度出发,去改造已有的网络使之只包含卷积层,从而使得网络可以接受任意尺寸大小的图片输入,并自动完成“滑窗”的过程。具体改造如下:(以ImageNet改造为例)
改造即是将全连接层改为卷积层,原来的ImageNet最后的3个全连接层,参数维度分别为fc6: 4096×9216×1×1,fc7: 4096×4096×1×1,fc8: 2×4096×1×1(分2类)。
-
1- 在deploy文件中将最后2层重写为卷积核大小为1,卷积步长为1的卷积层。以最后一层的改造为例,下图左边是改造之前,右图是改造之后的结果。

-
2- 倒数第3层fc6稍微有点不同,为了和上一个卷积层的输出个数256对齐,因此需要将9216拆解成6×6的卷积核(256×6×6=9216)。如下图:

-
3- 完成上述改造之后,实际使用的时候还要做一点工作。因为我们在deploy.prototxt中已经固定了输入图片的尺寸,如下图:
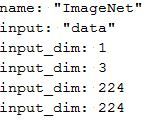
如果我们想要输入一张451×451的图片,那么你需要修改deploy文件为: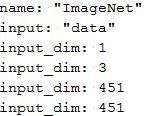
这样看起来很麻烦,因为直接在deploy文件中修改的话,你需要改完之后保存deploy文件然后重新读取caffemodel。幸亏这里还有简单的方法:
%读取我的图片的尺寸
[newM,newN,newD]=size(myimage);
blobdata = imNet.blob_vec(imNet.name2blob_index('data'));
newshape=[newM newN newD 1];
%将data层reshape为我的尺寸
blobdata.reshape(newshape);- 1
- 2
- 3
- 4
- 5
- 6
上面的方法使得我们只需创建一次网络,便可以通过快速reshape来应对各种不同尺寸的输入图片。
最终,我们可以直接将一张大小为451×451的图片输入到神经网络当中,而得到一个8×8×2的输出。其中8=(451-224)/32+1。也就是说改造之后的网络相当于以滑动步长32的进行窗口大小为224×224的滑动。(其中滑动步长等于网络中所有卷积步长stride的乘积)。
更加详细的介绍也可参考这里:http://nbviewer.ipython.org/github/BVLC/caffe/blob/master/examples/net_surgery.ipynb
但是,上述改造的网络其实并不等于滑动窗口。因为该网络中的每一个卷积层中卷积步长都小于卷积核的大小,这也就意味着上述过程中产生的窗口其实都有着相互之间的影响。于是,本来不存在人脸的地方就可能由于“滑动窗口”而受到远处的人脸影响,最终被检测为人脸
为此,我设计了下面的滑窗网络
2-4-2 我自己设计的滑窗网络SlipW
我这个网络主要就是针对上面的问题而设计的,方法很简单:只要出现卷积核的地方,卷积步长一定等于卷积核大小。至于整体结构,主要参考了NIN的设计思想,多次使用了卷积核为大小1的卷积层。
下面是第一层的示例:
layers {
name: "conv1"
type: CONVOLUTION
bottom: "data"
top: "conv1"
convolution_param {
num_output: 256
stride: 4
kernel_size: 4
}
}最终,模型大小2.2M,测试集上分类准确率为97.5%。
具体可参考我打包的源代码中的SlipW_net2文件夹。
3- 应用分类器进行人脸检测
所有代码,包括样本制作、以及一些尝试等等:百度云链接 密码:m3zw
前面也提到过,将一个人脸分类器转化为人脸检测器的最简单直接的方法就是“滑动窗口”,所幸我们的神经网络可以“自动滑窗”。现在还有一个问题,我们的窗口是32×32的,但实际当中的人脸尺寸可能远大于此。为了检测到更大的人脸,我们需要按照一定比例缩小图片,然后再用固定窗口检测。文章中建议该比例因子为0.7937.
3-1 NMS-多窗口融合
上面多尺度检测之后,同一个目标一般会得到多个框,就像下面这样: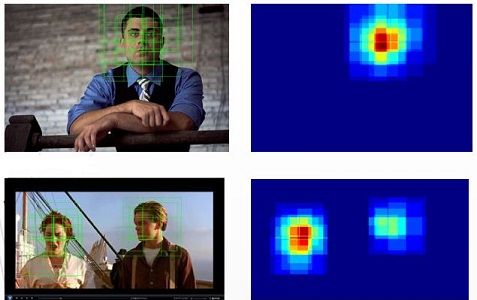
所以接下来我们还要做一点最后的处理工作,使得每一个目标只有一个矩形框。
这一部分到目前为止,我还没有特别理想的方法,我觉得这是一个很有挑战和技巧性的佛你工作。主要因为:
- 为了检测到侧脸和遮挡的人脸,我们在训练样本中增加了很多“部分”人脸。但是,这也导致实际应用时会在目标周围产生各种偏离的框。
- 经过深度卷积神经网络分类器,正面好的人脸的输出得分并不一定就比侧面较差人脸的得分高。这将导致,很多按照得分进行排序合并的NMS算法不能正常工作
- 由于存在偏离的框比较多,当目标比较密集或者一个较大目标旁边有一个较小目标时,合并的难度可想而知
检测的入口函数为face_detection.m,下面我就依照该函数来简要说明最终的检测流程:
下面的代码只是简单的流程,大家可以只看红色注释部分,就可以快速把握检测的流程
caffe_('reset');%caffe初始化
%构建滑窗网络
imNet=Net('SlipW_net2\SlipW_deploy.prototxt','SlipW_net2\SlipW_2_iter_444000','test');
%再建立另外两个网络,用于最后对检测结果做校验
test_net1=Net('Cifar10\cifar10_deploy.prototxt','Cifar10\cifar10_iter_270000','test');
test_net2=Net('SlipW_net1\SlipW_deploy.prototxt','SlipW_net1\SlipW_1_iter_553000','test');
%一些参数设置
winsize=32;%窗口大小
stride=16; %滑动步长
mean_data=[94.6683 104.1116 117.5282];%像素均值BGR
img=imread([PathName,FileName]);%读取待检测图片
[M,N,~]=size(img);%图片尺寸
factor= 0.793700526; %图像的缩小比例因子0.5^(1/3)
minL=min(M,N);
scales=factor.^(0:fix(-log(minL/winsize)/log(factor))); %缩放比例表
%依据缩放比例表,来循环对图像进行缩放,然后检测
for i=1:length(scales)
imimg=imresize(img,scales(i)*[M N]);%按表缩放
intemp =io.load_image(imimg);%图像预处理(RBG->BGR,Width<->Height)
[newM,newN,newD]=size(intemp);
%减去均值
intemp(:,:,1)=intemp(:,:,1)-mean_data(1);
intemp(:,:,2)=intemp(:,:,2)-mean_data(2);
%reshape网络data层,使之可以接受当前尺寸的输入
blobdata= imNet.blob_vec(imNet.name2blob_index('data'));
newshape=[newM newN newD 1];
blobdata.reshape(newshape);
%前向传播,输出分类结果
out=imNet.forward({intemp});
%对分类结果判断整理,并依据缩放比例还原出包围框位置
mboundingBox=generateBoundingBox(out);
boundingBox=[boundingBox;mboundingBox]; %存储所有的矩形框
end
%处理得到的大量矩形框:NMS+验证
if ~isempty(boundingBox)
boundingBox=sortrows(boundingBox,-6);%将矩形框按照得分降序排列
leftboxes=nms_gauss(double(boundingBox),0.15);%应用基于gauss的NMS方法,进行窗口合并
[numboxes,~]=size(leftboxes);
%利用2个test CNNs来对最后的检测结果进一步进行验证,减少误检
for i=1:numboxes
...
out1=test_net1.forward({intemp});
out2=test_net2.forward({intemp});
%如果2个网络验证为人脸的概率都大于0.1或者概率之和大于1.2,则确定为人脸
if out2{1}(2)>0.1 && out1{1}(2)>0.1 && blobout1(2)>0.5 || out1{1}(2)+out2{1}(2)>1.2
...
end
end下面放一些检测结果,大家可以发现,准确率和召回率没有太大问题,对遮挡,光照,偏转的鲁棒性也挺高,但就是定位不够准确.各位读者有好的方法,我们也可以相互交流一下.