Raft协议学习笔记
目录
目录 1
1. 前言 1
2. 名词 1
3. 什么是分布式一致性? 3
4. Raft选举 3
4.1. 什么是Leader选举? 3
4.2. 选举的实现 4
4.3. Term和Lease比较 4
4.4. 选举图示 4
4.5. 选举总结 7
5. Raft日志复制 8
5.1. 什么是日志复制? 8
5.2. 日志复制的实现 8
5.3. 脑裂时的复制 10
6. 概念对比 12
7. 共性探讨 13
7.1. PacificA和HBase和Kafka 13
7.2. Redis&Raft&ZAB&PaxOS 13
8. 总结浓缩 13
8.1. 三种角色 13
8.2. 两种RPC 13
8.3. 两个超时时间 14
9. 参考 14
1. 前言
常见的一致性协议主要有:PaxOS、Raft、ZAB、PacificA等。同PaxOS,Raft也不考虑拜占庭将军问题(Byzantine failures,注:比特币采用工作量证明PoW和股权证明PoS解决了拜占庭将军问题)。
2. 名词
| Distributed Consensus |
分布式一致性 |
| Distributed Consensus Algorithms |
分布式一致性算法,PaxOS是分布式一致性算法的鼻祖,绝大多数的实现要么基于PaxOS,要么受PaxOS影响(如Zookeeper)。 |
| PaxOS
|
就分布式系统中的某个值(在PaxOS中叫决议,即Proposer)达成一致的算法。PaxOS是分布式一致性协议的鼻祖,在Google的三大件未推出之前少为人知,1989年莱斯利·兰伯特提出。Leslie Lamport是大神的英文名,出生于1941年2月7日纽约。兰伯特目前就职于微软研究院,他也是排版系统LaTeX的作者,2008年获得冯诺依曼奖,2013年获得图灵奖,麻省理工学院学士和布兰戴斯大学博士。最早的实现为Google内部使用的Chubby。 |
| Raft |
木筏协议,一种共识算法,旨在替代PaxOS,相比容易理解许多。斯坦福大学的两个博士Diego Ongaro和John Ousterhout两个人以易懂为目标设计的一致性算法,2013以论文方式发布。由于易懂,不从论文发布到不到两年的时间,即出现大量的Raft开源实现。为简化PaxOS的晦涩,它采用分而治之的办法,将算法分为三个子问题:选举(Leader Election)、日志复制(Log Replication)、安全性(Safety)和集群成员动态变更(Cluster Membership Changes)。 |
| ZAB |
Zookeeper采用的一致性算法,全称“ZooKeeper Atomic Broadcast”,即Zookeeper原子广播协议,实为Zookeeper版本的PaxOS。 |
| PacificA |
微软2008年提出的日志复制协议,与PaxOS和Raft不同,PacificA并不提供Leader选举,因此需要结合PaxOS或Raft,分布式消息队列Kafka的ISR算法类似于PacificA。小米开源的KV系统Pegasus基于PacificA实现。 |
| Viewstamped Replication |
简称VR,最初被提出是作为数据库中的一部分工作,2012年作为单独的分布式共识算法再次发表。 |
| Log Replication |
日志复制 |
| Leader Election |
领导选举 |
| Log |
代表一个修改操作 |
| Entry |
(日志)条目(代表一个修改操作),Log在Raft中的实体,即一个Entry表示一条Log |
| Term |
任期(可简单理解成租约,但稍有不同),是一个从0开始递增的整数值,每次发起选举时增一,最终所有节点的Term值是相同的。等同于ZAB协议中的zxid的高32位,即ZAB中的Epoch。 |
| Index |
和Term密切相关,Term针对的是选举,而Index针对的是一条Log,它的值也是从0开始递增。同样最终所有节点的Index也相同,如果两个节点的Term和Index均相同,则这两个节点的数据是完全一致的。等同于ZAB协议中的zxid的低32位。 |
| Node |
节点 |
| Single Node |
单节点 |
| Multiple Nodes |
多节点 |
| Leader |
领导(唯一接受修改操作的) |
| Follower |
跟随者(投票参与者) |
| Candidate |
候选人(唯一具有发起选举的) |
| Vote |
投票 |
| Heal |
恢复,比如恢复网络分区(Heal the network partition) |
| Step Down |
下台,当一个Leader发现有更大的Term时,自动降为Follower |
| Logic Clock |
逻辑时钟,由Lampert提出,原因是分布式中无法使用精准的时钟维护事件的先后顺序,方法是为每个消息(或日志)加上一个逻辑时间戳。在ZAB协议中,每个消息均由唯一的zxid标识。zxid是一个64位无符号整数值,被分成两部分:高32位是Epoch,低32位是一个从0开始的递增值。类似于Raft的Term,每次选举新Leader,Epoch值增一,但同时zxid值清0。而Raft也类似,实际也是两部分组成,Term对应于Epoch,Index对应于zxid的低32位。 |
| Quorum |
法定人数 |
| Brain Split |
脑裂,同一个网络的节点被分成了两个或多个不互通的部分 |

3. 什么是分布式一致性?
多个节点(Multiple Nodes)的数据完全相同,即为分布式一致性。但因为多个节点通过网络互联,并不一定时刻可用,而服务不能因为某些节点(特别是少数节点)不可用时,导致整个系统不可用。
Raft将节点分成三种角色:Leader、Follower和Candidate,一个节点可为三种角色中的任意一种,但同一时刻只会为其中一种角色。正常情况下,只有Leader和Follower两种角色的节点,只有在选举时才会出现Candidate角色节点,而且可能多个节点同时处于Candidate角色同时竞争选举。
4. Raft选举
4.1. 什么是Leader选举?
Raft协议中,一个节点有三个状态:Leader、Follower和Candidate,但同一时刻只能处于其中一种状态。Raft选举实际是指选举Leader,选举是由候选者(Candidate)主动发起,而不是由其它第三者。
并且约束只有Leader才能接受写和读请求,只有Candidate才能发起选举。如果一个Follower和它的Leader失联(失联时长超过一个Term),则它自动转为Candidate,并发起选举。
发起选举的目的是Candidate请求(Request)其它所有节点投票给自己,如果Candidate获得多数节点(a majority of nodes)的投票(Votes),则自动成为Leader,这个过程即叫Leader选举。
在Raft协议中,正常情况下Leader会周期性(不能大于Term)的向所有节点发送AppendEntries RPC,以维持它的Leader地位。
相应的,如果一个Follower在一个Term内没有接收到Leader发来的AppendEntries RPC,则它在延迟随机时间(150ms~300ms)后,即向所有其它节点发起选举。
采取随机时间的目的是避免多个Followers同时发起选举,而同时发起选举容易导致所有Candidates都未能获得多数Followers的投票(脑裂,比如各获得了一半的投票,谁也不占多数,导致选举无效需重选),因而延迟随机时间可以提高一次选举的成功性。
4.2. 选举的实现
在Raft中,和选举有关的超时值有两个:
| 选举超时(Election Timeout) |
Follower等待成为Candidate的时间,为随机时间,随机范围为150ms~250ms。如果在超时之前收到了其它的AppendEntries,则重置选举超时重新计时,否则在选举超时后,Follower成为Candidate,投票给自己(Votes for itself)并发起新的选举任期(Term),发送RequestVote给所有其它节点,以请求投票给自己。如果在这个Term时间内仍然没有获得投票,则重置选举超时,以准备重新发起选举。而一旦获得多数节点的投票,则成为Leader。成为Leader后,定期性的发送AppendEntries给所有Followers,以维持Leader地位。发送AppendEntries的间隔叫作心跳超时。 |
| 心跳超时(Heartbeat Timeout) |
Follower会应答每一个AppendEntries,一个选举任期(Election Term)会一直存在,直到有新的Follower成为Candidate。Leader节点通过定期发送AppendEntries维护自己的Leader地位,定期的间隔时长即为心跳超时时长。在Raft中,心跳方向是:Leader -> Follower。 |
如果一个Follower在一个Term时间内没有收到AppendEntries(并非要求是来自Leader的AppendEntries,其它Candidates也一样有效),则它成为Candidate,并在等待选举超时(Election Timeout)后发起选举。
要求获得多数节点的投票,可以保证每个任期(Term)内只有一个Leader。如果两个Candidates同时发起选举,则会分割投票,这样需要再重新发起选举。Raft设计“选举超时”,可以降低两个或多个Candidates同时发起选举的概率,减少连续重选举。
Redis的选举有个借鉴意义,在Redis集群中,不同节点可有不同权重,权重大的优先获得发起选举几率。在Redis中,权重是指复制节点数据的新旧程度,而对Raft来说可考虑机架机房等作为权重。
4.3. Term和Lease比较
Raft中的Term可以简单看成Lease(租约),但概念上仍然是有区别的。Lease通常是一个节点向一个中心化节点请求,而Term是无中心化的。
如果没有发生选举超时,则Term的值不会发生变化,否则至少增一。
4.4. 选举图示
每个节点的Term值初始化为1(圆圈中的数字),每个节点选举超时时间为一个150ms~300ms的随机值(实际实现可以调整,但这个值是发明者测试得到的优值,详情请参见两位斯坦福大学教授的论文):
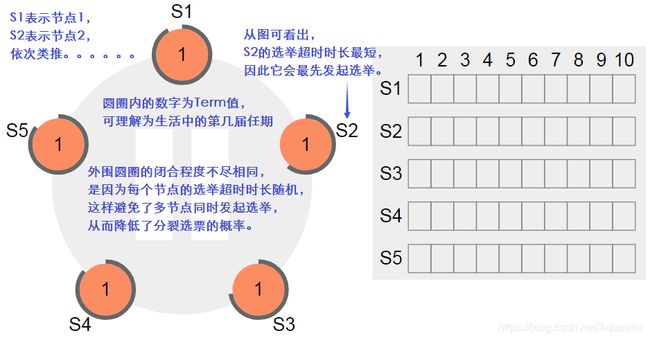
节点S2最先发起选举成为Leader,在发起选举之前,它需要先自增自己的Term值,因此Term值由1变成2,同时其它节点的Term值也需要更新为比自己大的Term值(如果一个Leader遇到一个更大的Term,它需要主动降为Follower):
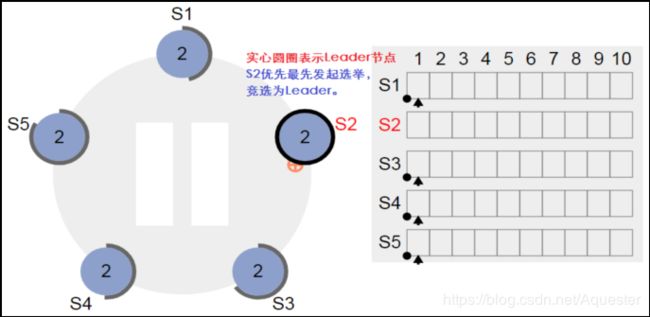
人工将节点S1和S2停掉,这时两者不可用。这会导致其它正常的节点S3、节点S4和节点S5在选举超时时间内收不到来自Leader的心跳(实为AppendEntry),因此会触发节点S3、节点S4和节点S5发起选举(究竟哪个节点发起选举,视哪个节点最先达到选举超时):
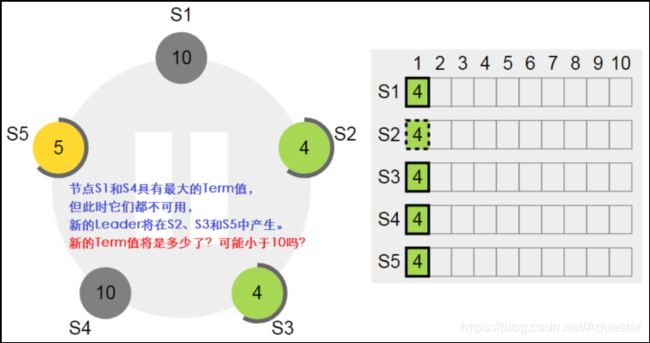
因为节点S2的数据处于未提交状态,因为它的已提交Index值要小于S3和S5,它没有最新的数据,不可能成为新的Leader。新的Leader必然在S3和S5中产生。先强制重置S2的选举超时时长,以让出优先发起选举:
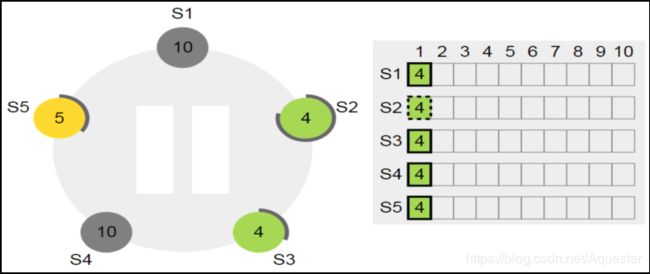
虽然S3和S5均有最新的数据,但因为S3的Term小于S5的Term,因此只有S5才能成为Leader,这样最新的Term值将为5+1为6:
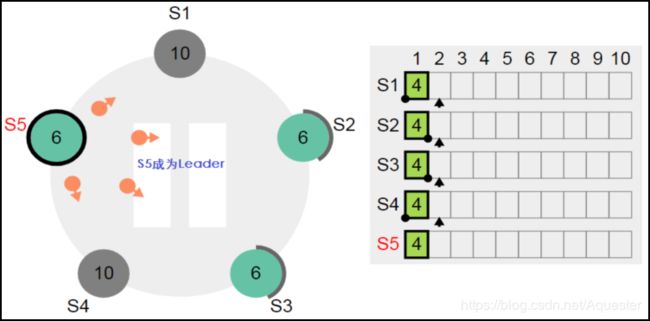
这个时候恢复节点S1,Term值是否会改变?
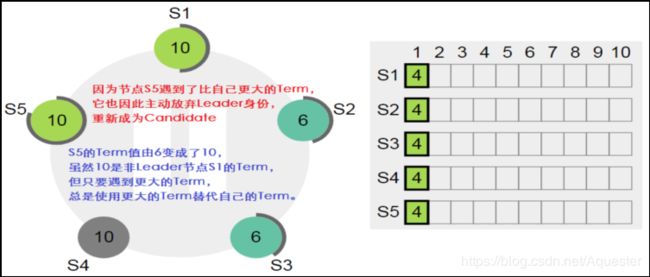
一个Leader节点,如果遇到比自有更大的Term值,则主动放弃Leader身份,并使用原Term替代自己的Term,然后转变为Candidate重新开始选举。
非Leader节点也是一样的,只要遇到比自己大的Term,都会使用更大的Term替代自己的Term。这样能保证节点均能正常通信时,Leader节点总是持有最大的Term。
4.5. 选举总结
能成为Leader的条件:
1) 有最大的Term;
2) 如果Term相同,则有最大的Index;
3) 如果Term相同,Index也相同,就看谁最先发起;
4) 最先发起者也不一定成为Leader,还得看谁最先获得多数选票。
一个Leader主动放弃Leader条件:
1) 遇到比自己更大的Term,这个时候会转为Follower。
5. Raft日志复制
5.1. 什么是日志复制?
Leader收到一个修改请求后,先将该请求记录到本地日志,这条日志在Raft中叫作Enry,此时处于未提交状态(Uncommitted),然后复制Entry给所有的Followers。当多数Followers节点确认已完成该Entry的写入后,Leader本地提交该Entry,响应客户端成功,这个过程叫日志复制(Log Replication)。如果一个Entry不能复制到多数节点,则该Entry状态一直为未提交,如果发生Leader转换,有可能被覆盖。
5.2. 日志复制的实现
正常的复制不需要理解,主要看异常时的复制处理。让节点S5成为Leader,然后停掉节点S2、S3和S4,然后客户端再请求写操作,但此时由于写操作不能得到多数节点的确认,所以无法提交(不能应用到状态机中):
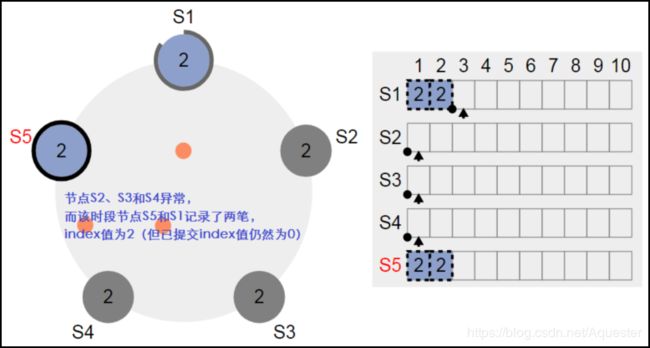
先停掉节点S1和S5,再恢复节点S2、S3和S4,并让节点S3成为Leader,然后客户端发起一笔写操作。让写操作在三个节点S2、S3和S4中得到确认,这样该笔写操作为已提交状态(Committed),可以看到变成如下状态了。显然节点S1和节点S5上存在了两笔脏数据:
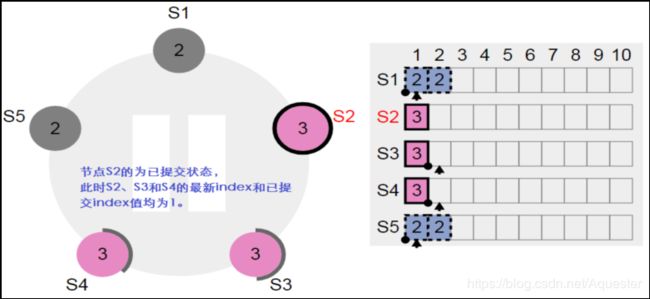
恢复节点S1:
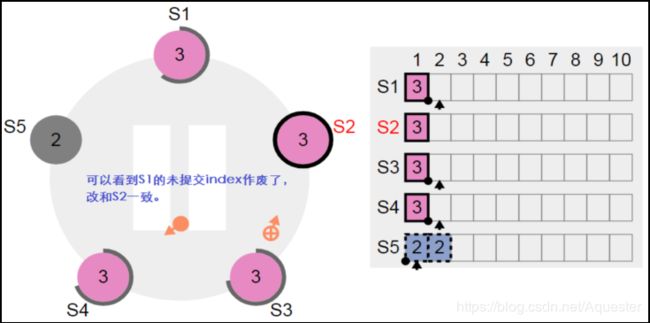
停止节点S3,构造条件让S1成为新的Leader:
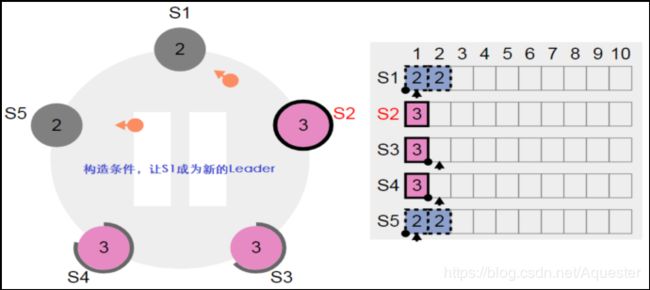
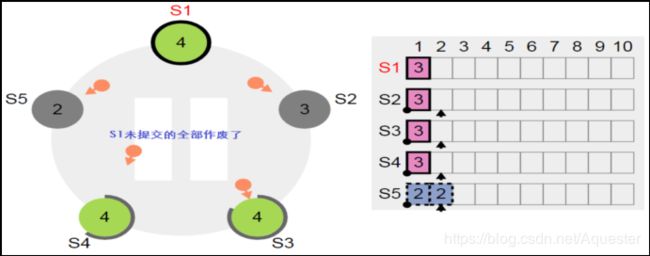
5.3. 脑裂时的复制
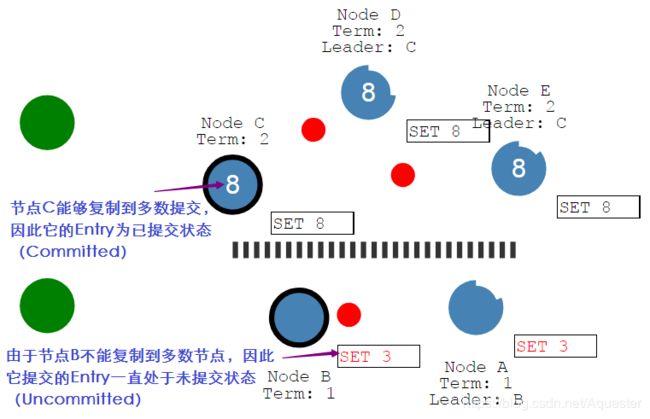
网络分裂时,出现两个Leader:
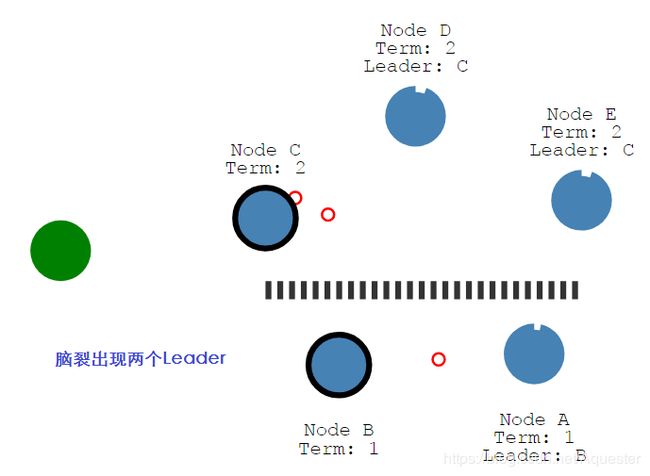
具有多数节点的一方仍然能够继续,但少数一方已不可用,这个时候从节点B读不到最新的数据:
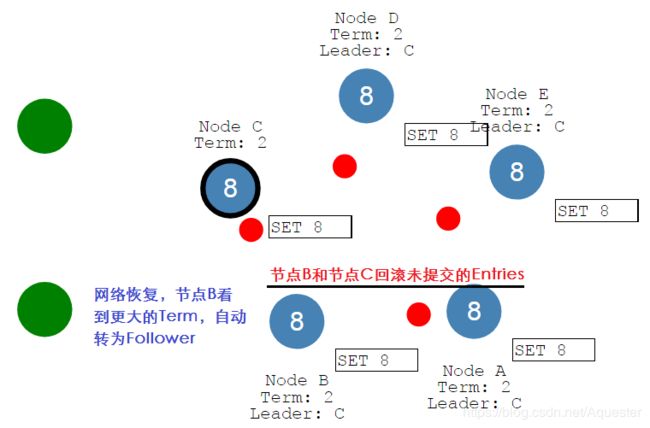
当网络恢复后,节点B发现更大的Term,自动从Leader将为Follower,同时回滚未提交的Entries,集群又重新实现一致。
6. 概念对比
| Raft |
PaxOS (Multi PaxOS) |
ZAB |
PacificA |
Viewstamped Replication |
| 获得多数同意 |
获得多数同意 |
获得多数同意 |
需所有都同意 |
获得多数同意 |
| 强Leader(领导),总是包含了最全最新的日志,日志无空洞,随机化简化Leader选举(Redis也采用了这个方法,并且加了节点权重)。 |
Proposer(提议者),允许有多个Proposer,并且不一定最包含了最全最新的日志,日志可存在空洞 |
强Leader(领导) |
Primary(主) |
Primary |
| Follower(跟随者) |
Acceptor(接受者) |
Follower(跟随者,参与投票) |
Secondary(副),接收Primary的心跳,一个Primary对多个Secondary |
Backup |
| Candidate(候选者) |
Learner(学习者) |
Looking(竞选状态) |
|
|
|
|
|
Observing(观察者,不参与投票,只同步状态) |
|
|
| Entry |
达到一致的叫Value(即决议),达到一致前叫提议 |
类似PaxOS |
|
|
| Term(任期) |
Ballot(选票) |
Epoch(纪元),为txid的高32位(注:Redis中也叫Epoch,作用类似) |
View |
|
| Index(序号) |
Proposal Number |
txid的低32位 |
Serial Number |
|
7. 共性探讨
所有的并不是完全孤立的,而是存在很多共性。
7.1. PacificA和HBase和Kafka
PacificA和HBase均依赖于PaxOS这样的设施,HBase依赖于Zookeeper,PacificA同样依赖于类似的配置管理服务。
如同HBase依赖Zookeeper来发现Keys的位置信息,PacificA依赖配置管理服务发现分片的位置。
Kafka其实也类似,早期Kafka直接将位置信息存储在了Zookeeper中,遭遇了Zookeeper吞吐瓶颈,于是采取和HBase类似的做法,将位置信息作为一个特殊的Partition。
7.2. Redis&Raft&ZAB&PaxOS
Redis同Raft、ZAB和PaxOS并不是一类东西,但核心均有Quorum的朴素思想,即服从多数(多数人理解的即为真理),而且均依赖于一个递增的值来达到一致性状态,这个递增的值在Redis和ZAB中叫Epoch,Raft中叫Term。
8. 总结浓缩
8.1. 三种角色
1) Leader(领导者)
2) Follower(跟随者)
3) Candidate(候选人)
8.2. 两种RPC
1) AppendEntry(心跳和写操作)
2) RequestVote(请求投票)
8.3. 两个超时时间
| 中文名 |
英文名 |
主要问题 |
小技巧 |
| 选举超时 |
Election Timeout |
选票分裂造成活锁 |
随机时间(Redis非强一致,另加了权重) |
| 心跳超时 |
Heartbeat Timeout |
不能小于选举超时时长 |
|
9. 参考
1) https://translate.google.cn
2) https://raft.github.io/raft.pdf
3) https://raft.github.io/
4) http://thesecretlivesofdata.com/raft/
5) PacificA:微软设计的分布式存储框架
6) 分布式共识(Consensus):Viewstamped Replication、Raft以及Paxos
7) https://static.googleusercontent.com/media/research.google.com/en//archive/paxos_made_live.pdf