CUDA编程基本概念与矩阵运算
1、并行计算
1)单核指令级并行ILP---让单个处理器的执行单元可以同时执行多条指令
2)多核并行TLP---在一个芯片上集成多个处理器核心,实现线程级并行
3)多处理器并行---在一块电路板上安装多个处理器,并实现进程和线程级并行
4)可借助网络实现大规模的集群或者分布式并行,每个节点就是一台独立的计算机,实现更大规模的并行计算。
多线程编程既可以在多个CPU核心间实现线程级并行,也可以通过超线程等技术更好的利用每一个核心内的资源,充分利用CPU的计算能力。
支持CUDA的GPU可以看成是一个由若干个向量处理器组成的超级计算机,性能也确实可以和小型的超级计算机相比。
GPU和CPU一般经北桥(主板上最大最重要的芯片,负责CPU和内存、显卡之间的数据交换,往往覆盖有散热片或风扇)通过AGP或者PCI-E总线连接,各自有独立的外部存储器,分别是内存和显存。
首先确定一个windowSize*windowSize大小的窗口,这里的windowSize是一个奇数,因此这个窗口一定会有一个中心的像素,中值滤波的过程就是不断的移动这个窗口,然后对窗口内的所有像素的像素值按照灰度级来排序,最后把排序后中间那个像素的灰度级赋值给窗口中心那个像素。这个就是中值滤波的意义。
2、CUDA基本概念
变量类型限定符
__shared__限定符可以与__device__结合使用,声明变量:
驻留在线程块的共享内存空间中,具有块的生命期,仅可被块内的所有线程访问。
执行配置
对__global__函数的任何调用必须为此调用指定执行配置内置变量
时间函数
同步函数
3、CUDA编程模型
// Kernel definition
__global__ void vecAdd(float* A, float* B, float* C)
{
}
int main()
{
// Kernel invocation
vecAdd<<<1, N>>>(A, B, C);
}以下示例代码将大小为N的向量A和向量B相加,并将结果存储在向量C中
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// Kernel invocation
vecAdd<<<1, N>>>(A, B, C);
}执行vecAdd()的每个线程都会执行一次成对的加法运算。
4、CUDA线程结构
一般来说,threadIdx会设置成一个包含三个组件的向量。
下面的示例代码将大小为N*N的矩阵A和矩阵B相加,并将结构储存在矩阵C中
__global__ void matAdd(float A[N][N], float B[N][N],float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
// Kernel invocation
dim3 dimBlock(N, N);
matAdd<<<1, dimBlock>>>(A, B, C);
}线程的索引和线程的ID有着直接的关系:
对一维块: 两者相同
对大小为(Dx,Dy)二维块: 索引:(x, y)ID : x + yDx
对大小为(Dx,Dy, Dz)的三维块 : 索引:(x, y, z) ID:x + yDx + ZDxDy
一个块中的所有线程都必须位于同一个处理器核心中。因而一个处理器核心的有限存储器资源制约了每个块的线程数量。在NVIDIA Tesla构架中,一个线程块最多可包含512个线程。
但一个内核可能由多个大小相同的线程块执行,因而线程总数应该等于每个块的线程数乘以块的数量。这些块将组织称为一个一维或二维的线程块网格。
该网格的维度由<<<...>>>语法的第一个参数指定。
网格内的多个块可由一个一维或二维索引标示,可通过内置的blockIdx变量在内核中访问此索引。可以通过内置的blockDim变量在内核中访问块的维度。
此时,之前的示例代码应该改为:
__global__ void matAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
// Kernel invocation
dim3 dimBlock(16, 16);
dim3 dimGrid((N + dimBlock.x – 1) / dimBlock.x,
(N + dimBlock.y – 1) / dimBlock.y);
matAdd<<>>(A, B, C);
} 实际上在CUDA中应该使用由cudaMallocPitch()分配的空间存储二维数组中的数据。
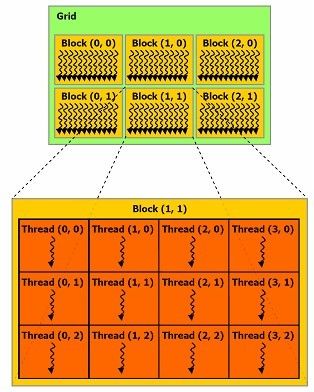
总体来说就是:
一个grid中有多个block,可以为一维,二维,三维
一个block中有多个thread,可以为一维,二维,三维
grid中的block个数由gridDim确定(最多二维)
grid中的block定位使用blockIdx来确定
block中的thread个数由blockDim确定(最多三维)
block中的thread定位使用threadIdx来确定
5、矩阵运算
计算两个维度分别为(wA,hA)和(wB,wA)的矩阵A和B的乘积C的任务以下列方式分为多个线程:
1、每个线程块负责计算C的一个子方阵Csub;
2、块内的每个线程负责计算Csub的一个元素。
选择Csub的维度block_size等于16,以便每块的线程数是warp大小的倍数,且低于每块的最大线程数

如图所示Csub等于两个矩阵的乘积:A的子矩阵(wA,block_size)与Csub具有相同的行索引,B的子矩阵(block_size,wA)与Csub具有相同的列索引。为了适应设备的资源,这两个矩形矩阵可根据需要划分为许多维度的block_size的方阵,并且Csub计算为这些方阵的乘积之和。其中每个乘积的执行过程是:首先使用每个线程加载每个方阵的一个元素,将两个相应的方阵从全局内部加载到共享内存,然后让每个线程计算结果为方阵的一个元素。每一线程将其中每个乘积的结果累计到寄存器中,执行完毕后,将结果写入全局内存。
通过这种方式分块计算,我们可以有效利用快速的共享内存,并节省许多全局内存带宽,因为A和B仅从全局内存读取(wA/block_size次)
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the device multiplication function
__global__ void Muld(float*, float*, int, int, float*);
// Host multiplication function
// Compute C = A * B
// hA is the height of A
// wA is the width of A
// wB is the width of B
void Mul(const float* A, const float* B, int hA, int wA, int wB,float* C)
{
int size;
// Load A and B to the device
float* Ad;
size = hA * wA * sizeof(float);
cudaMalloc((void**)&Ad, size);
cudaMemcpy(Ad, A, size, cudaMemcpyHostToDevice);
float* Bd;
size = wA * wB * sizeof(float);
cudaMalloc((void**)&Bd, size);
cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice);
// Allocate C on the device
float* Cd;
size = hA * wB * sizeof(float);
cudaMalloc((void**)&Cd, size);
// Compute the execution configuration assuming
// the matrix dimensions are multiples of BLOCK_SIZE
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(wB / dimBlock.x, hA / dimBlock.y);
// Launch the device computation
Muld<<>>(Ad, Bd, wA, wB, Cd);
// Read C from the device
cudaMemcpy(C, Cd, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(Ad);
cudaFree(Bd);
cudaFree(Cd);
}
// Device multiplication function called by Mul()
// Compute C = A * B
// wA is the width of A
// wB is the width of B
__global__ void Muld(float* A, float* B, int wA, int wB, float* C)
{
// Block index
int bx = blockIdx.x;
int by = blockIdx.y;
// Thread index
int tx = threadIdx.x;
int ty = threadIdx.y;
// Index of the first sub-matrix of A processed by the block
int aBegin = wA * BLOCK_SIZE * by;
// Index of the last sub-matrix of A processed by the block
int aEnd = aBegin + wA - 1;
// Step size used to iterate through the sub-matrices of A
int aStep = BLOCK_SIZE;
// Index of the first sub-matrix of B processed by the block
int bBegin = BLOCK_SIZE * bx;
// Step size used to iterate through the sub-matrices of B
int bStep = BLOCK_SIZE * wB;
// The element of the block sub-matrix that is computed
// by the thread
float Csub = 0;
// Loop over all the sub-matrices of A and B required to
// compute the block sub-matrix
for (int a = aBegin, b = bBegin;
a <= aEnd;
a += aStep, b += bStep) {
// Shared memory for the sub-matrix of A
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
// Shared memory for the sub-matrix of B
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
// Load the matrices from global memory to shared memory;
// each thread loads one element of each matrix
As[ty][tx] = A[a + wA * ty + tx];
Bs[ty][tx] = B[b + wB * ty + tx];
// Synchronize to make sure the matrices are loaded
__syncthreads();
// Multiply the two matrices together;
// each thread computes one element
// of the block sub-matrix
for (int k = 0; k < BLOCK_SIZE; ++k)
Csub += As[ty][k] * Bs[k][tx];
// Synchronize to make sure that the preceding
// computation is done before loading two new
// sub-matrices of A and B in the next iteration
__syncthreads();
}
// Write the block sub-matrix to global memory;
// each thread writes one element
int c = wB * BLOCK_SIZE * by + BLOCK_SIZE * bx;
C[c + wB * ty + tx] = Csub;
}