场景分类MATLAB代码实现
前面对论文《A Bayesian Hierarchical Model for Learning NaturalScene Categories》 进行了讲解,现在可以结合代码来看。
需要声明的是,下面的代码只是一个场景分类的demo,它和论文中提到的思想不一样,但它们可以帮助我们更好地理解论文。
原始代码是基于视觉词袋模型BOW的MATLAB实现的。整个程序的流程如下:
利用Dense-SIFT对图像进行特征提取 -> 利用K-means算法形成K个聚类中心,构成字典dictionary -> 对图像进行直方图统计得到BOW -> 利用SVM进行分类 –> 预测图像类别
含该SIFT特征提取的代码可在github上下载:
自然场景分类代码
除此之外,我将代码中的SIFT特征提取变为HOG特征提取,并比较了两者的精确度。
含该HOG特征提取的代码可在github上下载:
自然场景分类代码
这里提供该代码所用技术的介绍:
词袋模型BOW:
https://wenku.baidu.com/view/6370f28d26fff705cc170aab.html
https://wenku.baidu.com/view/7782de2fc281e53a5902ff03.html
Dense-SIFT:
http://blog.csdn.net/happyer88/article/details/46622657
HOG:
http://blog.csdn.net/dulingtingzi/article/details/51488060
SVM:
https://www.analyticsvidhya.com/blog/2017/09/understaing-support-vector-machine-example-code/
libsvm:
http://www.cnblogs.com/dawnminghuang/p/3825229.html
http://blog.csdn.net/on2way/article/details/47733861
现在结合代码讲一下Dense-SIFT/HOG + BOW模型建立过程:
1、如果利用sift特征提取算法,从每张图片中提取特征点也就是视觉单词。在代码中,比如有些图片大小是200*200,然后步长是8,将图片分成16*16的小patch,这样就有576个小patch,在每个小patch上都进行sift提取关键点,每个小patch上有一个关键点,这样就有576个关键点,也就是每张图片最终变成了576个128维的向量(sift特征点是128维的),也就是576*128这样大小的一个矩阵。图片包括训练样本和测试样本一共有360张图片,所以数据一共就是360*576*128。
(如果利用hog特征提取算法,从每张图片中提取特征点也就是视觉单词。在代码中,比如有些图片大小是200*200,然后cell大小是8(步长也默认为1个cell)。将图片分成25*25的小cell,这样就有625个小cell。在每个小cell上都进行hog提取关键点。然后,每2*2(取其他也可以)个cell合成一个block,所以这里就有(25-1)*(25-1)=576个block。所以每个block中都有2*2*9个特征(9是梯度方向的个数),一共有576个block,所以总特征为576*36的一个矩阵。图片包括训练样本和测试样本一共有360张图片,所以数据一共就是360*576*36)
2、利用K-means进行聚类,构建字典dictionary。在代码中是找了300个聚类中心,也就是300*128(在hog中是300*36),聚类中心个数的选取从几百到上千不等,一般数据越大,聚类中心越多。聚类的数据是训练数据240*576*128(在hog中是240*576*36)和测试数据120*576*128 (在hog中是120*576*36),最大迭代次数100,聚类完成后得到300个聚类中心,每个是1*128维(在hog中是1*36维)的向量。
3、利用得到的聚类中心得到词汇表以后,对360张图片进行直方图统计,也就是看每张图片中的576个关键点与哪个聚类中心的距离最小(最相似),然后再最近的那个聚类中心所代表的1-300之间的数上加1,这样最终得到了BOW的数据300*360大小的矩阵,这里面300*240是训练数据,300*120是测试数据。
注意由于这里每张图片的关键点的数目都是一样的,所以归一化的影响并不是特别的关键,但是如果每张图片上关键点的数目不是一样的,那就必须进行归一化,也就是将词数变成词频,就是除以总点数。
以上是基本的BOW建立的过程,作者的程序中有一个构造了pyramid_BOW的程序CompilePyramid。 BOW与pyramid BOW在统计每张图的词频时是一样的 ,关键是对这些词频的处理不一样,BOW是全局进行统计词频,而pyramid BOW如名字所示,是分层次的,在代码中,是首先将图片分成4*4小块,对每小块进行300个聚类中心的词频统计,并用2^-1进行加权,然后在将图片分成2*2小块进行300个聚类中心的词频统计,并用2^-2进行加权,最后再对整个图片全局的直方图进行直方图统计,并用2^-2进行加权,最后将这些直方图连在一起,这样最终的数据是6300*360这样的数据去进行训练(6300=(4*4+2*2+1*1)*300)。 也就是说,源程序里面是有两种词袋的数据结果,BOW和pyramid_BOW.
精确度评估(Dense-SIFT):
1. BOW+径向基核函数的SVM进行分类,精度是77.5%;
2. Pyramid_BOW+径向基核函数的SVM进行分类,精度是82.5%;
作者又自己定义了一种核函数,称之为inter。
3. BOW+inter核函数的分类精度是81.6667%;
4. Pyramid_BOW+inter核函数的分类精度是最高的,为90.8333%。
下面是SIFT+Pyramid_BOW+inter的分类结果:


混淆矩阵的概念在论文中已经讲了。在这里我们看到,Phoning类有90%分类正确,10%被错误地分到RidingHorse中。(横着看)
下面是HOG+Pyramid_BOW+inter的分类结果:

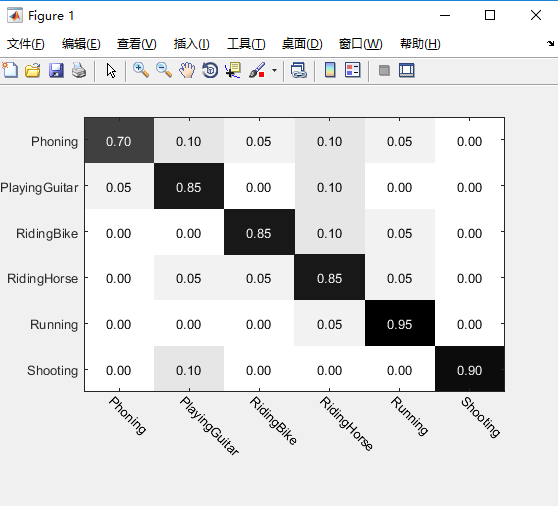
这个是没有调参数的结果。效果我就不吐槽了,有兴趣可以尝试调调参数什么的。
这里给大家留一个问题:为什么在自然场景分类中HOG特征提取的效果不如Dense-SIFT特征提取的效果?