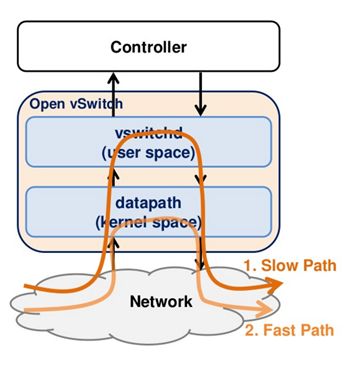
【OpenVswitch源码分析之六】内核空间转发面数据结构与流程
内核态的报文处理起始有不少人已经写了比较详细的分析,这里有SDNLAB的一篇文章(http://www.sdnlab.com/15713.html),这里只是对那些文章再做些总结;内核对报文的处理整体上分为三个大的步骤:
- 报文头的提取
- 流表项的匹配
- 动作的执行
对于报文头的提取,与传统的路由器、交换机不同,OpenFlow的匹配域包含了L2-L4等匹配域。所以其设计了一个数据结构sw_flow_key来做提取
struct sw_flow_key {
u8 tun_opts[255];
u8 tun_opts_len;
struct ip_tunnel_key tun_key; /* Encapsulating tunnel key. */
struct {
u32 priority; /* Packet QoS priority. */
u32 skb_mark; /* SKB mark. */
u16 in_port; /* Input switch port (or DP_MAX_PORTS). */
} __packed phy; /* Safe when right after 'tun_key'. */
u8 tun_proto; /* Protocol of encapsulating tunnel. */
u32 ovs_flow_hash; /* Datapath computed hash value. */
u32 recirc_id; /* Recirculation ID. */
struct {
u8 src[ETH_ALEN]; /* Ethernet source address. */
u8 dst[ETH_ALEN]; /* Ethernet destination address. */
__be16 tci; /* 0 if no VLAN, VLAN_TAG_PRESENT set otherwise. */
__be16 type; /* Ethernet frame type. */
} eth;
union {
struct {
__be32 top_lse; /* top label stack entry */
} mpls;
struct {
u8 proto; /* IP protocol or lower 8 bits of ARP opcode. */
u8 tos; /* IP ToS. */
u8 ttl; /* IP TTL/hop limit. */
u8 frag; /* One of OVS_FRAG_TYPE_*. */
} ip;
};
struct {
__be16 src; /* TCP/UDP/SCTP source port. */
__be16 dst; /* TCP/UDP/SCTP destination port. */
__be16 flags; /* TCP flags. */
} tp;
union {
struct {
struct {
__be32 src; /* IP source address. */
__be32 dst; /* IP destination address. */
} addr;
struct {
u8 sha[ETH_ALEN]; /* ARP source hardware address. */
u8 tha[ETH_ALEN]; /* ARP target hardware address. */
} arp;
} ipv4;
struct {
struct {
struct in6_addr src; /* IPv6 source address. */
struct in6_addr dst; /* IPv6 destination address. */
} addr;
__be32 label; /* IPv6 flow label. */
struct {
struct in6_addr target; /* ND target address. */
u8 sll[ETH_ALEN]; /* ND source link layer address. */
u8 tll[ETH_ALEN]; /* ND target link layer address. */
} nd;
} ipv6;
};
struct {
/* Connection tracking fields. */
u16 zone;
u32 mark;
u8 state;
struct ovs_key_ct_labels labels;
} ct;
} __aligned(BITS_PER_LONG/8); /* Ensure that we can do comparisons as longs. */struct sw_flow {
struct rcu_head rcu;
struct {
struct hlist_node node[2];
u32 hash;
} flow_table, ufid_table;
int stats_last_writer; /* NUMA-node id of the last writer on
* 'stats[0]'.
*/
struct sw_flow_key key;
struct sw_flow_id id;
struct sw_flow_mask *mask;
struct sw_flow_actions __rcu *sf_acts;
struct flow_stats __rcu *stats[]; /* One for each NUMA node. First one
* is allocated at flow creation time,
* the rest are allocated on demand
* while holding the 'stats[0].lock'.
*/
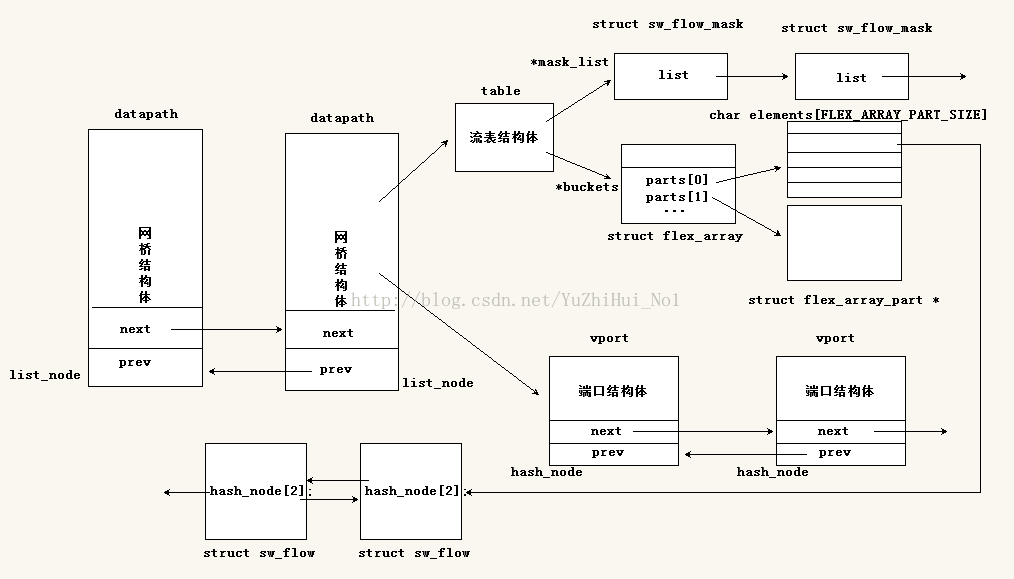
};相关数据结构的关系及详细内容都在上面有表述,下面讲讲具体的工作步骤:
第一步,它会根据网桥上的流表结构体(table)中的mask_list成员来遍历,这个mask_list成员是一条链表的头结点,这条链表是由mask元素链接组成(里面的list是没有数据的链表结构,作用就是负责链接多个mask结构,是mask的成员);流表查询函数开始就是循环遍历这条链表,每遍历到得到一个mask结构体,就调用函数进入第二步。
第二步,是操作key值,调用函数让从数据包提取到的key值和第一步得到的mask中的key值,进行与操作,然后把结构存放到另外一个key值中(masked_key)。顺序执行第三步。
第三步,把第二步中得到的那个与操作后的key值(masked_key),传入 jhash2()算法函数中,该算法是经典的哈希算法,想深入了解可以自己查资料(不过都是些数学推理,感觉挺难的),linux内核中也多处使用到了这个算法函数。通过这个函数把key值(masked_key)转换成hash关键字。
第四步,把第三步得到的hash值,传入 find_bucket()函数中,在该函数中再通过jhash_1word()算法函数,把hash关键字再次哈希得到一个全新的hash关键字。这个函数和第三步的哈希算法函数类似,只是参数不同,多了一个word。经过两个哈希算法函数的计算得到一个新的hash值。
第五步,把第四步得到的hash关键字,传入到flex_array_get()函数中,这个函数的作用就是找到对应的哈希头位置。具体的请看上面的图,流表结构(table)中有个buckets成员,该成员称作为哈希桶,哈希桶里面存放的是成员字段和弹性数组parts[n],而这个parts[n]数组里面存放的就是所要找的哈希头指针,这个哈希头指针指向了一个流表项链表(在图中的最下面struct sw_flow),所以这个才是我们等下要匹配的流表项。(这个哈希桶到弹性数组这一段,我有点疑问,不是很清楚,在下一篇blog中会分析下这个疑问,大家看到如果和源代码有出入,请按源代码来分析),这一步就是根据hash关键字查找到流表项的链表头指针。
第六步,由第五步得到的流表项链表头指针,根据这个指针遍历整个流表项节点元素(就是struct sw_flow结构体元素),每遍历得到一个流表项sw_flow结构体元素,就把流表项中的mask成员和第一步遍历得到的mask变量(忘记了可以重新回到第一步去看下)进行比较;比较完后还要让流表项sw_flow结构体元素中的key值成员和第二步中得到的key值(masked_key)进行比较;只有当上面两个比较都相等时,这个流表项才是我们要匹配查询的流表项了。然后直接返回该流表项的地址。如果找到了,很好说明用户态的流表已经放入内核,则走fast path就可了。于是直接调用ovs_execute_actions,执行这个key对应的action。
如果不能找到,则只好调用ovs_dp_upcall,让用户态去查找流表。会调用static int queue_userspace_packet(struct datapath *dp, struct sk_buff *skb, const struct sw_flow_key *key, const struct dp_upcall_info *upcall_info)
它会调用err = genlmsg_unicast(ovs_dp_get_net(dp), user_skb, upcall_info->portid);通过netlink将消息发送给用户态。在用户态,有线程监听消息,一旦有消息,则触发udpif_upcall_handler。