Scrapy学习笔记(1)
我是scrapy初学者,所以只是爬取一些小资源拿来练练手,scrapy还有很多强大的功能没学,所以把这篇笔记当成初学者的笔记也好。因为总共学习编程不到半年,拿爬虫练手,即可以爬取有趣的资源,也会对编程更加热爱,提高编程能力。本次学习的scrapy就是爬虫很强大的框架。我参考的是scrapy的官方英文文档,不过实例都是我自己写的
本笔记假设你已经安装了scrapy。
我在装scrapy的时候也遇到了一些问题,比如python的win32api没有安装、lxml库找不到etree模块,其中win32api我是手动安装的;lxml是因为版本是4.0.0的,而且好像没有etree这个模块,所以我手动安装了3.8.0版本的,有etree,问题得以解决,全程都是靠百度,所以花点时间就可以装上,记得配好环境变量(Python根目录以及scripts目录)。
一、创建一个新工程
选择一个目录(我选在了D:\Project),打开命令行并输入
scrapy startproject MyProject
成功的话就会像下图所示

你将会产生这样的一个目录:
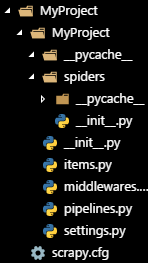
MyProject/外层目录
scrapy.cfg部署Scrapy爬虫的配置文件
/MyProject/你将要写代码的地方
__init__.py初始化脚本
items.pyitems代码
middlewares.pyMiddlewares代码
pipelines.pyPipelines代码
settings.pyScrapy爬虫的配置文件
spiders/写爬虫代码的地方
二、第一个爬虫
写一个爬虫
你可以手动编写一个python脚本或者使用命令行来完成它,这里以http://588ku.com/为例,有很多素材,可以爬爬爬
先进入MyProject目录下:
cd MyProject
命令行输入:
scrapy genspider material 588ku.com
接下来在spiders/目录下产生了名为material.py的文件,快去看看它的内容
# -*- coding: utf-8 -*-
import scrapy
class MaterialSpider(scrapy.Spider):
name = 'material'
allowed_domains = ['588ku.com']
start_urls = ['http://588ku.com/']
def parse(self, response):
pass它现在只是默认的格式,我们来修改它,让它可以爬取一些内容:
# -*- coding: utf-8 -*-
import scrapy
class MaterialSpider(scrapy.Spider):
name = 'material'
def start_requests(self):
urls = [
'http://588ku.com/pt/chengshi.html',
'http://588ku.com/pt/lvxing.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split('/')[-1][:-5]
filename = 'material-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
如你所见,这个名为MaterialSpider的类继承了scrapy.Spider类,并且定义了如下属性和方法:
name:用来识别爬虫,在一个工程中,爬虫的名字必须是独一无二的,你不能创建同一个名字的两个或更多的爬虫start_requests():必须返回一个可迭代的请求(你可以写一个列表或者生成器),爬虫将根据这些请求爬取网站parse():将调用此方法来对每一个请求进行下载处理。response属性是TextResponse的一个实例,它拥有页面的内容并且有更深入的方法来处理它;
parse()方法常常用来解析response属性,将提取爬下来的数据作为字典类型或找到新的URL连接并建立新的请求
运行我们的爬虫
打开命令行,在MyProject/下,输入:
scrapy crawl material
你将会看到如图所示的一堆log:
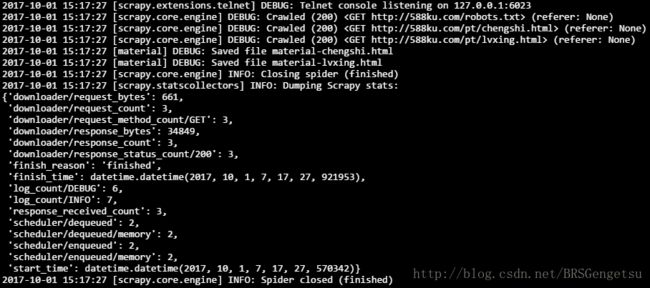
可以看到,在DEBUG之后,GET请求的返回值都是200,说明爬取成功。其中对于robots.txt的请求也是200,说明该网站有相关的robots协议,我们刚刚爬取的城市和旅行并没有在disallow的范围内,所以作为练习,只要不大量、无节制地爬取,就不会对该网站造成负担。
scrapy是默认遵守robots协议的,所以你不必担心违反了robots协议,如果(referer: None)则是没有违反,否则的话会被禁止,如果你硬是想要爬取一些网站的话…(我不会告诉你在settings.py中把ROBOTSTXT_OBEY = True改为False)
接下来你会找到material-chengshi.html和material-lvxing.html两个文件。
Scrapy将start_requests()方法返回的scrapy.Request对象列入计划表, 根据收到每个对象的响应, 实例化Response对象并且调用callback方法和请求联系在一起(也就是解析,即parse()方法)把响应(response)作为参数返回。
这样,我们成功运行了第一个爬虫
start_reauests()方法的捷径
就像刚刚初始化那样,你可以不用实现start_requests()方法来从URL连接中生成scrapy.Resquest对象,而是仅仅定义一个叫做start_urls的属性,即一个包括url连接的列表。这个列表将会被默认的start_requests()方法调用来为你的爬虫创建初始的请求。两种方法都可取。
三、导出爬取的数据
0、scrapy shell
Scrapy学习提取数据最好的方法就是使用Scrapy shell,在任意目录下打开命令行(配好scrapy的环境变量即可)并输入:
scrapy shell+网址
比如:
scrapy shell “http://588ku.com/pt/lvxing.html”
然后会如下所示:

(1)CSS selectors
你可以试着输入:
response.css(‘title’)
结果是:
[
其结果是一个像列表一样的SelectorList对象,代表了一系列的Selector对象, 包括XML/HTML的元素并且允许你查询更深入的Selector或者获取数据。
为了获取title里的内容(text)可以输入:
response.css(‘title::text’).extract()
结果:
['【旅行图片大全】_高清旅行图片下载_千库网配图'] ::text
有两个需要注意的地方,一个就是我们在css中加了,表示我们仅仅想选择中的text元素[‘【旅行图片大全】高清旅行图片下载千库网配图‘]
如果不加的话,就会是下面这样:
我们会直接获得整个标签。
另一个就是我们在末尾加了,调用它的结果就是我们获得的结果是列表(list),是因为我们正在处理*SelectorList*的一个实例。 【旅行图片大全】高清旅行图片下载千库网配图’
当你知道你只想获得第一个结果时,你可以这样输入:
response.css('title::text').extract_first()
结果:
【旅行图片大全】高清旅行图片下载千库网配图’
你也可以这么写:
response.css('title::text')[0].extract()
结果:
**然而**,使用
因此我们得到了一个教训:对于大多数的爬虫代码,你希望在它没有找到所需要的东西时发生的错误是可以复原的,因此即使一部分爬取失败,你依然可以获得一些数据。
(2)re()
除了extract()和extract_first()方法,你也可以用re()方法即正则表达式来提取数据:
response.css(‘title::text’).re(r’.+’)[0]
结果:
'【旅行图片大全】_高清旅行图片下载_千库网配图'
当然,它取决于正则表达式的熟练程度
(3)XPath
为了找到合适的CSS选择器(CSS selectors)来使用, 你可能需要打开浏览器来查看源代码,或者使用浏览器的开发者工具或相关的扩展(插件),在scrapy shell中输入
>>>view(response)
就会用系统的默认浏览器打开该网址,鼠标右键点击查看源代码,或者F12打开开发者工具,也可以安装相关的扩展(这就要看是什么浏览器了,多到网络中问问有经验的人,推荐一个叫做 Selector Gadget的插件,很多浏览器都有),他们对于CSS或XPath十分有帮助,接下来简单介绍下XPath
我们和CSS对比来看
>>> response.css('title')
>>> response.xpath('//title')
>>> response.css('title::text').extract()
>>> response.xpath('//title/text()').extract()
XPath的语法看上去没有CSS简洁,但是实际上它十分强大,是Scrapy选择器的基础。事实上,CSS选择器是由XPath修改过来的,这个可以查阅更多的资料,简单来说就是CSS更加简洁,但是XPath更加强大。
虽然CSS更加受人欢迎,但是XPath提供了更强大的功能,因为在操作结构的同时它也能看着内容。使用XPath,你能够像这样选择:
包含有’下一页’内容的链接(以后肯定会提到)
response.xpath('//a[@class="downPage"]/@href').extract_first()
在@后跟上属性,[]来确定属性,如果没有=那就是选择拥有该属性的结点
以后会用其他的方法找到这个链接
这使得XPath非常适合爬虫的任务, 并且我鼓励你去学习XPath 即使你已经了解了CSS选择器的构建。使用XPath将会使得爬虫更加的容易。
1、提取数据
在shell中测试xpath
现在我们已经对选择器和提取有了一点了解让我们完成我们的爬虫来提取一些图片,和相关的信息。
每张图片如下所示:
<div class="fl img-list-box masonry-brick" style="position: absolute; top: 0px; left: 0px;">
<div class="img-box" style="height:188.86px">
<a href="http://588ku.com/peitu/52086.html" target="_blank">
<img class="lazy" src="http://xpic.588ku.com/figure/00/00/00/08/95/6355a1603812235.jpg!/fw/284" data-original="http://xpic.588ku.com/figure/00/00/00/08/95/6355a1603812235.jpg!/fw/284" width="284px" style="display: inline;">
a>
<div class="hover-content bglist_52086" style="display: block">
<a href="javascript:;" class="down-big-img" data="52086" type="3">下载<i>i>a>
<a href="javascript:;" class="favV2 nonofavV2" data="52086" type="3">a>
div>
div>
<div class="img-info">
<a href="http://588ku.com/peitu/52086.html" target="_black">女子之一风景旅行旅行a>
div>
div>根据开发者模式F12/检查第一个img标签是略缩图,而我们要找的是最后的那个链接,它在有[@class="img-info"]的div中,同时它里面的text内容就是标题,我们先来爬取这两个信息 链接 和 标题 。
先打开shell,输入
response.xpath(‘//div[@class=”img-info”]/a/text()’).extract()
获取所有的图片标题,再输入
response.xpath(‘//div[@class=”img-info”]/a/@href’).extract()
获取所有的图片链接
当然我们也可以试着这样做:
>>> a = response.xpath('//div[@class="img-info"]/a')
>>> for i in a:
... title = i.xpath('text()').extract_first()
... href = i.xpath('@href').extract_first()
... print(dict(title=title, href=href))
...结果就会像这样:
{‘title’: ‘女子之一风景旅行旅行’, ‘href’: ‘http://588ku.com/peitu/52086.html‘}
{‘title’: ‘海滩沙滩风景旅行海洋’, ‘href’: ‘http://588ku.com/peitu/58341.html‘}
{‘title’: ‘海滩沙滩风景旅行海洋’, ‘href’: ‘http://588ku.com/peitu/58342.html‘}
{‘title’: ‘海滩沙滩风景旅行海洋’, ‘href’: ‘http://588ku.com/peitu/58343.html‘}
{‘title’: ‘海滩沙滩风景旅行海洋’, ‘href’: ‘http://588ku.com/peitu/58345.html‘}
在爬虫中提取
回到material.py,之前只是把网页整个保存到本地而已,并没有提取什么有用的信息,让我们接下来在爬虫中提取。
一个Scrapy爬虫典型特征就是将页面中爬取到的信息生成字典,为了这样做,我们要用到yield关键字来callback回调,如下所示:
# -*- coding: utf-8 -*-
import scrapy
class MaterialSpider(scrapy.Spider):
name = 'material'
def start_requests(self):
urls = [
'http://588ku.com/pt/lvxing.html'
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for info in response.xpath('//div[@class="img-info"]/a'):
yield {
'title': info.xpath('text()').extract_first(),
'href': info.xpath('@href').extract_first()
}运行爬虫,你会在cmd的输出中看到类似于{'title': '女子之一风景旅行旅行', 'href': 'http://588ku.com/peitu/52086.html'}
的log(日志)
2、储存数据
(1)Feed exports
最简单的存储方式就是使用Feed exports,命令:
scrapy crawl material -o material.json
于是,在/MyProject下就生成了一个material.json文件,把它打开(我用VS code,你们随意:)
发现,汉字全是Unicode字符,诶,又是编码问题:(
不过别担心,我会说明解决办法。
除了编码问题,还有一点需要说明:
由于历史原因,Scrapy是在原有的文件中继续追加而不是创建新的文件覆盖,如果你运行该命令两次并且没有除去原来的.json文件,你将会得到一个破损的JSON文件。
(2)JSON Lines
(记得先把刚刚的material.json移到别处去!)
你也可以用这种格式,就像JSON Lines,缩写jl:
scrapy crawl material -o material.jl
JSON Lines格式很有用因为它就像溪流一样连续,你可以很轻松地在文件后边继续添加信息而不像上边的Feed exports只能用一次。当然,每一条信息都是隔行的,你可以处理很大的数据而不用记住一切信息。
也有像JQ等其他的格式,有兴趣的话你可以从其他文章中学习。
(Extra)Item Pipeline简介
在一些小项目中,以上的知识就足够了。然而,如果你想处理更复杂的数据,你可以写一个Item Pipeline,一个占位符(placeholder)文件在创建project的时候就已经被创建,即MyProject/pipelines.py,如果你只想存储数据的话并不需要写item pipeline。当然,要解决中文编码问题就要写了。
当一个item被爬虫爬下来后,它会被送到 Item Pipeline,也就是通过几个按顺序执行的组件来处理它。
每个item pipeline组件(有时候就是指item pipeline)是一个实现简单方法的类,它收到item后执行一系列处理,同时决定pipeline是否进行下去或者扔掉部分或者终止处理。
下面是典型的item pipeline的使用:
- 净化(cleanse)HTML数据
- 确认爬取的数据(检查条目是否包含某个字段)
- 检查是否有重复的(并且去掉他们)
- 在database中存储他们
item pipeline方法
每个item pipeline组件是一个python类,并且必须实现以下方法:
1、process_item(self, item, spider)
这个方法被所有的item pipeline组件调用。process_item()必须做到:
return一个有数据的dict
return一个Item对象(或子类的对象)
return一个Twisted Deferred(Twist延迟对象)或raise DropItem异常
被终止的Item不再被item pipeline处理。
参数:
- item(Item object 或者一个字典):爬取的item对象
- spider(Spider object):爬取item的爬虫对象
另外,还需要实现下面的方法:
2、open_spider(self, spider)
当爬虫打开时,这个方法就被调用
参数:
- spider(Spider object):被打开的爬虫对象
3、close_spider(self, spider)
当爬虫关闭时,调用这个方法
参数:
- spider(Spider object):被关闭的爬虫对象
4、from_crawler(cls, crawler)
如果实现了这个类方法(@classmethod),它被Crawler调用来创建一个pipeline实例。它必须返回一个pipeline的实例,Crawler对象提供对所有Scrapy核心组件的访问,比如settings和signal,pipeline访问它们并将其功能连接到Scrapy。
参数:
- crawler(Crawler object):使用这个pipeline的Crawler对象
item pipeline例子
接着上边的例子,我们爬取到了标题和链接,存放到material.jl中,接下来我们写一个item pipeline来处理
打开pipelines.py,里面有一个类MyprojectPipeline(object)
代码如下:
import json
class MyprojectPipeline(object):
def open_spider(self, spider):
self.file = open('items.jl', 'w', encoding='utf-8')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
别忘了在settings.py中,找到这一项并取消注释:
ITEM_PIPELINES = {
'MyProject.pipelines.MyprojectPipeline': 300,
}
这样刚刚写的pipeline在运行爬虫时就会被调用
执行scrapy crawl material
urf-8版的item.jl就被创建

图片
没记错的话,我们的目的是要爬取图片,否则干嘛拿一个图片的链接来当作实例。scrapy自带了下载项目图片的功能,如果放在这里介绍的话,会显得内容太多。所以我这里写了个简单的。因为比较简陋,所以缺点很明显,不过足够爬几千个图片了
# -*- coding: utf-8 -*-
import scrapy
from requests import get
class MaterialSpider(scrapy.Spider):
name = 'material'
start_urls = ['http://588ku.com/?m=peitu&a=search&keyword=lvxing&page=1']
def parse(self, response):
'找到所有的图片链接'
for info in response.xpath('//div[@class="img-info"]/a/@href').extract():
'交给img_parse()处理'
yield scrapy.Request(info, callback=self.img_parse)
next_page = response.xpath('//a[@class="downPage"]/@href').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(str(next_page), callback=self.parse)
def img_parse(self, response):
title = response.xpath('//title/text()').extract_first()
img = response.xpath('//div[@class="main"]/img/@src').extract_first().split('jpg')[0] + 'jpg'
r = get(img)
yield {'title': title}
with open('D:\\Project\\MyProject\\MyProject\\img\\'+title + '.jpg', 'wb+') as f:
f.write(r.content)一顿饭回来已经爬了6000+图片,估计能爬上万。。。我就不继续测试了,基本走了一套流程,关于scrapy还有很多强大的功能,我会逐渐深入学习。