MySQL多数据源实战(二)——Spring多数据源 一主多从读写分离
本篇文章将在代码层面实现主从复制读写分离
1.首先,得搞三个数据源,怎么做在上篇文章中已经介绍过,一主两从:如下图

3306作为主库,进行写,3307和3308作为读库,进行读取操作 。
2.创建一个Spring工程:具体怎么创建就不在进行赘述了。
3.因为有三个数据源,所以在jdbc.properties中要配置三份数据库的连接信息:
jdbc_url_m=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
jdbc_url_s_1=jdbc:mysql://localhost:3307/test?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
jdbc_url_s_2=jdbc:mysql://localhost:3308/test?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
jdbc_username=root
jdbc_password=root配置文件中的druid也要配置三份,一主两从:
那么问题来了,这地方配置了三个数据源,mybatis需要引入的DataSource怎么写?
解决办法:既然之前的无法满足我们,那我们就实现自己的数据源,Spring对这方面也提供了支持
先将自定义的数据源的bean贴上:
//默认数据源
创建一个DynamicDataSource类并集成Spring的AbstractRoutingDataSource:
public class DynamicDataSource extends AbstractRoutingDataSource {
/**
*@Author ZNX
*@Description:
* determineCurrentLookupKey中的key就是在spring配置文件中配置的关键词在这里先看一下AbstractRoutingDataSource这个类:
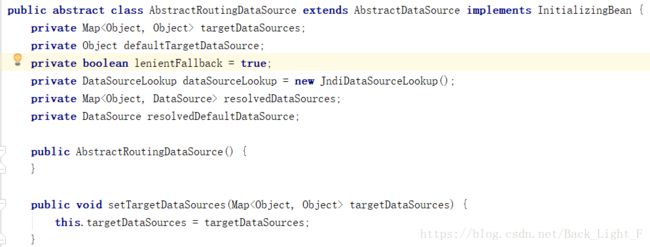
这个类又继承了AbstractDataSource,进入AbstractDataSource:

发现AbstractDataSource实现了DataSource接口,而DataSource是java.sql包下的,我们连接数据库,就是通过这个接口实现的。
接着回到自定义的数据源:再将代码贴一遍:
public class DynamicDataSource extends AbstractRoutingDataSource {
/**
*@Author ZNX
*@Description:
* determineCurrentLookupKey中的key就是在spring配置文件中配置的关键词我们都知道,Web程序是由多个用户,多个线程一起访问的,那这个数据源在Spring中是比较唯一的,每个用户过来都是共享一份数据源,现在进行数据源的切换,是会有线程安全问题的。我们未来解决线程问题。我们用并发编程中的知识来解决。
创建一个DynamicDataSourceHolder类:
public class DynamicDataSourceHolder {
/*解决多线程环境下数据源切换造成的线程问题*/
public static final ThreadLocal holder = new ThreadLocal<>();
//写库对应的数据源key
private static final String MASTER = "master";
/*请求累加器:用于切换从库的轮询算法*/
private static AtomicInteger counter = new AtomicInteger(-1);
//读库对应的数据源key
private static final String SLAVE_1 = "slave_1";
private static final String SLAVE_2 = "slave_2";
public static void setDataSource(DataSourceType dataSourceType){
if(dataSourceType==DataSourceType.MASTER){
System.out.println("========="+MASTER+"=============");
holder.set(MASTER);
}else if (dataSourceType==DataSourceType.SLAVE){
//设置从库
holder.set(roundRobinSlaveKey());
}
}
public static String getDataSource(){
return holder.get();
}
/*轮询两个从库*/
private static String roundRobinSlaveKey() {
Integer index = counter.incrementAndGet()%2;
if(counter.get()>9999){
counter.set(-1);
}
if(index==0){
System.out.println("========="+SLAVE_1+"=============");
return SLAVE_1;
}else {
System.out.println("========="+SLAVE_2+"=============");
return SLAVE_2;
}
}
} 这里使用了ThreadLocal解决线程问题,ThreadLocal的相关知识会在以后的文章中详细讲解。读者也可以去并发编程网等进行学习。
在这里,再新建一个枚举类对主从进行标识:
public enum DataSourceType {
MASTER,SLAVE;
}上面的DynamicDataSourceHolder类主要是对数据源的选择以及切换,但是我们应该什么时候切换数据源呢?怎么切换呢?
现在我们希望切换数据源由自己控制,比如在业务层打一个注解,进行读取操作的时候切换到从库,进行更新操作的时候切换到写库。首先自己定义一个注解:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface DataSource {
//默认主库
DataSourceType value() default DataSourceType.MASTER;
}这时在业务代码上就可以打相应的注解了:
/**
*@Description 根据用户名查询用户
*/
@DataSource(DataSourceType.SLAVE)
@Override
public User findUserByUserId(long id) {
User user=null;
try {
user =userMapper.selectByPrimaryKey(id);
}catch (Exception e){
e.printStackTrace();
throw e;
}
return user;
}现在还没有完成,还没有指明切换数据源。
接下来,我们就用切面编程的思想来解决这个问题:
我们切所有业务层的方法,获取到这个注解,看是slave还是Master,然后调用Holder方法对数据源进行设置;
定义一个切面,这里就不用注解了,用传统的方法来实现:
public class DataSourceAspect {
/*
一定要用前置通知
*/
public void before(JoinPoint point) throws NoSuchMethodException {
//获取切点
Object target = point.getTarget();
//获取方法名称
String method = point.getSignature().getName();
//用反射获取到class字节码对象
Class classz = target.getClass();
//获取参数列表
Class[] parameterTypes = ((MethodSignature)point.getSignature()).getMethod().getParameterTypes();
//我们的最终目的是拿到方法上的注解,首先要拿到方法
Method m = classz.getMethod(method,parameterTypes);
//判断方法是否存在以及是否存在DataSource的注解
if(m!=null&&m.isAnnotationPresent(DataSource.class)){
//得到注解
DataSource dataSource = m.getAnnotation(DataSource.class);
//设置数据源
DynamicDataSourceHolder.setDataSource(dataSource.value());
}
}
}在配置文件中配置一下切面,让切面生效:
到这里,基本上都配置完成了,我们来测试一下:
这是Controller:查询id为1的用户
/**
*@Description 获取用户信息
*/
@RequestMapping("/getuser")
@ResponseBody
public User getUser(){
return userService.findUserByUserId(1);
}
浏览器:
![]()
断点进来Service:发现已经查询到了:
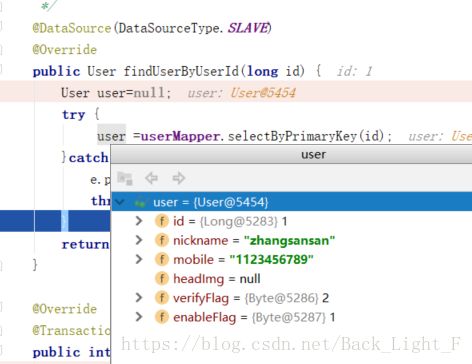
再看控制台输出:发现我们走的是slave1数据源:

再刷一次,发现走的就是slave2数据源了:
![]()
现在再来测试一下插入数据:
@Override
@Transactional
public int insertUser() {
User user = new User();
user.setMobile("1234567");
user.setNickname("zhangsan");
User user1 = new User();
user1.setMobile("11111111");
user1.setNickname("zhangsan");
userMapper.insertSelective(user);
userMapper.insertSelective(user1);
return 0;
}执行,查看数据库主库:已经插入

再查看从库:也同步过来了
![]()
在这里,我们再测试一下多数据源下的事务:插入两条数据,第二条id重复,插入失败,看事务是否会回滚
@Override
@Transactional
public int insertUser() {
User user = new User();
user.setMobile("123123123132");
user.setNickname("zhangsan1");
User user1 = new User();
user1.setId(12L);
user1.setMobile("321321321");
user1.setNickname("zhangsan2");
userMapper.insertSelective(user);
userMapper.insertSelective(user1);
return 0;
}
运行,毫无疑问报错了:

再看数据库,发现没有新数据插入,说明事务也生效了:

现在我们还要讨论一个问题:数据一致性的问题:
我们写操作是对主库进行操作,当我们写操作时,会产生一个二进制文件,从库接收到这个二进制日志时,将主库产生的操作再进行一遍,这样就使数据一致了。虽然这个复制的时候非常快,但在高并发时,刚对主库进行数据的写入,再去从库获取,可能会获取不到,这种情况叫做数据不一致的一种情况。
这时候这个问题是不太好解决的。
强一致性:
如果在一个业务里既包含了写,也包含了读,那么就将数据源设置为主库,虽然我们进行了读写分离,但不要过于依赖。
这样会导致主库的压力比较大。
弱一致性:
我们可以将写入的数据存入缓存(Redis),用户读的时候先走缓存,缓存没有,再走从库,等缓存中数据失效的时候,数据就已经同步到从库了。但是在极端的高并发情况下,缓存也是顶不住的。这时候可以牺牲一点用户体验,告诉用户服务器繁忙,稍后再查。
本篇文章就先到这里了,感谢您的阅读。