爬虫实例(一)
1.京东商品页面的爬取
https://item.jd.com/2967929.html

代码:
import requests
url = "https://item.jd.com/2967929.html"
try:
r = requests.get(url)
r.raise_for_status()
r.encodint = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
"""
结果如下:
<html lang="zh-CN">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gbk" />
<title>【华为荣耀8】荣耀8 4GB+64GB 全网通4G手机 魅海蓝【行情 报价 价格 评测】-京东title>
<meta name="keywords" content="HUAWEI荣耀8,华为荣耀8,华为荣耀8报价,HUAWEI荣耀8报价"/>
<meta name="description" content="【华为荣耀8】京东JD.COM提供华为荣耀8正品行货,并包括HUAWEI荣耀8网购指南,以及华为荣耀8图片、荣耀8参数、荣耀8评论、荣耀8心得、荣耀8技巧等信息,网购华为荣耀8上京东,放心又轻松" />
<meta name="format-detection" content="telephone=no">
<meta http-equiv="mobile-agent" content="format=xhtml; url=//item.m.jd.com/product/2967929.html">
<meta http-equiv="mobile-agent" content="format=html5; url=//item.m.jd.com/product/2967929.html">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<link rel="canonical" href="//item.jd.com/2967929.html"/>
<link rel="dns-prefetch" href="//misc.360buyimg.com"/>
<link rel="dns-prefetch" href="//static.360buyimg.com"/>
<link rel="dns-prefetch" href="//img10.360buyimg.com"/>
<link rel="dns-pre
"""2.亚马逊商品页面的爬取
https://www.amazon.cn/gp/product/B01M8L5Z3Y

用类似的代码去爬取,如下图所示:
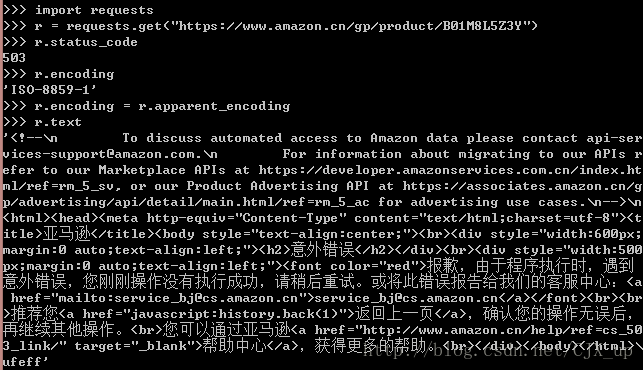
可以发现发生了错误,爬取失败,status_code 为503,爬取成功应该返回200。其实已经能够从服务器获得页面相关信息回来,表明爬取失败不是网络问题造成的。在网络爬虫引发的问题及限制这篇博客中,提到服务器可以通过来源审判来拒绝爬虫的访问。
我们知道 Requests 库的两个对象中,返回的 Response 对象包含了请求服务器资源的 Request 对象的所有信息。因此可以通过 Response 对象来查看我们发送请求的相关信息:
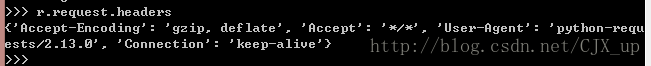
从 User-Agent 可以看出,我们发出的请求信息已经诚实地告诉服务器,这个请求来自一个 Requests 库的 python 程序。这个不在该服务器的接受范围内,因此爬取失败。
我们可以通过修改头部信息来解决这个问题:

可以看出,发送请求的头部信息已经更改,爬取成功。其中,’Mozilla/5.0’表明请求来自于某个浏览器(火狐等)。
完整代码如下:
url = "https://www.amazon.cn/gp/product/B01M8L5Z3Y"
try:
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url, headers = kv)
r.raise_for_status()
r.encodint = r.apparent_encoding
print(r.text[1000:2000])
except:
print("爬取失败")3.百度/360搜索关键字提交
如何利用程序自动向搜索引擎提交关键词并获得搜索结果呢?百度和360都提供了提交关键词的接口,如下图所示,我们只需要通过改变 keyword 来构造 url,便可以提交我们想搜索的关键词并获取相关信息了。

百度搜索代码:
import requests
try:
kv = {'wd':'Python'}
r = requests.get("http://www.baidu.com/s", params = kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
"""
结果:
wdir='C:/Users/ChenJX/Desktop/爬虫')
http://www.baidu.com/s?wd=Python
271918
"""360搜索代码:
import requests
try:
kv = {'q':'Python'}
r = requests.get("http://www.so.com/s", params = kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
"""
结果如下:
https://www.so.com/s?q=Python
302893
"""4.网络图片的爬取和存储
【网络图片链接的格式:http://www.example.com/picture.jpg】
用下面这个图片链接作为例子:
http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg

代码如下:
import requests, os
url="http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg"
root = "C:/Users/ChenJX/Desktop/爬虫"
# url.split('/')[-1]表示以符号'/'分割url字符串,并返回最后一个
# 分割后得到多个子字符串,返回最后一个即返回图片名称
path = root + '/' + url.split('/')[-1]
try:
# 如果此目录不存在,就创建一个
if not os.path.exists(root):
os.mkdir(root)
# 如果此路径不存在,即该目录下没有要保存的文件,则继续操作
if not os.path.exists(path):
r = requests.get(url)
# 打开该文件,'wb'表以'写二进制'的模式打开
# (可以进行写操作,写的是二进制形式)
with open(path, 'wb') as f:
# r.content 返回的是响应内容的二进制形式
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
"""
结果如下:
文件保存成功
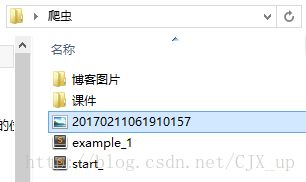
"""同时可以看到该图片已经保存在相应的目录下:
5.IP地址归属地的自动查询
下图是查询 IP 地址归属地的页面,我们只需要传入 ipaddress 这个参数、构造一个 url,就可以查询归属地。

代码如下:
import requests
url = "http://m.ip138.com/ip.asp?ip="
try:
r = requests.get(url + '202.204.80.112')
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
"""
结果如下:
value="查询" class="form-btn" />
form>
div>
<div class="query-hd">ip138.com IP查询(搜索IP地址的地理位置)div>
<h1 class="query">您查询的IP:202.204.80.112h1><p class="result">本站主数据:北京市海淀区 北京理工大学 教育网p><p class="result">参考数据一:北京市 北京理工大学p>
div>
div>
<div class="footer">
<a href="http://www.miitbeian.gov.cn/" rel="nofollow" target="_blank">沪ICP备10013467号-1a>
div>
div>
<script type="text/javascript" src="/script/common.js">script>body>
html>
"""