Storm 核心概念及工作原理
Strom 简介
Apache Storm(http://storm.apache.org)是由Twitter 开源的分布式实时计算系统,Storm 可以非常容易并且可靠的处理无线的数据流,对比Hadoop的批处理,Storm是一个实时的、分布式的、具备高容错的计算系统。
Storm的核心代码使用clojure书写,实用程序使用python开发,使用java开发拓扑。
Storm 的使用场景非常广泛,比如实时分析、在线机器学习、分布式RPC、ETL等。Storm非常高效,在一个多节点集群每秒可以轻松处理上百万条的消息。Storm还具有良好的可扩展性和容错性以及保证数据可以至少被处理一次等特性。
下图中水龙头和后面水管组成的拓补图就是一个Storm应用(Topology),其中的水龙头是Spout,用来源源不断地读取消息并发送出去,水管的每一个接口就是Bolt,通过Storm的分组策略转发消息流
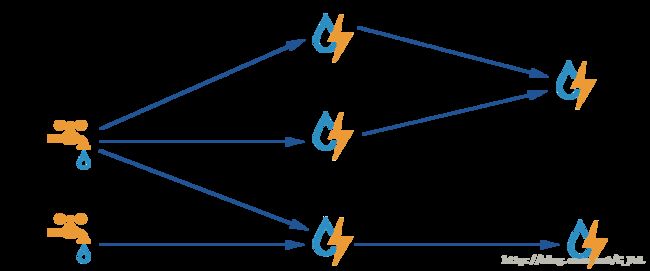
Storm 核心组件
Storm 的集群表面上看和Hadoop的非常像,但是在Hadoop上运行的是MapReduce的作业(job),而在Storm上运行的是是Topology,Storm和Hadoop一个非常关键的区别是Hadoop的MapReduce作业最终会结束,而Storm的Topology会一直运行(除非显示的杀掉它)
如果说批处理的Hadoop需要一桶一桶地搬走水,那么Storm 就好比自来水水管,只要预先接好水管,然后打开水龙头,水就源源不断地流出来了,即消息就会被实时地处理。
在Storm 集群中有两种节点:主节点(Master Node)Nimbus和工作节点(Worker Node)Supervisor。
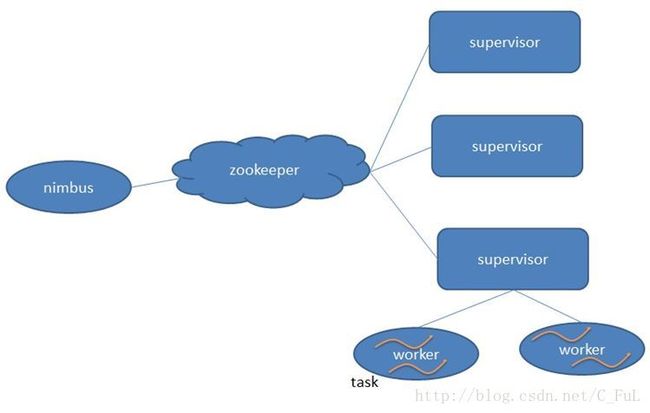
Nimbus:负责资源分配和任务调度。
Supervisor:负责接受Nimbus分配的任务,启动和停止属于自己管理的worker进程。通过配置文件设置当前supervisor上启动多少个worker。
Worker:运行具体处理组件逻辑的进程(执行任务的具体组件)。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task:每一个Spout/Bolt具体要做的工作,也是各个节点之间进行分组的单位。worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为Executor。
Zookeeper:保存任务分配的信息、心跳信息、元数据信息
Storm 编程模型
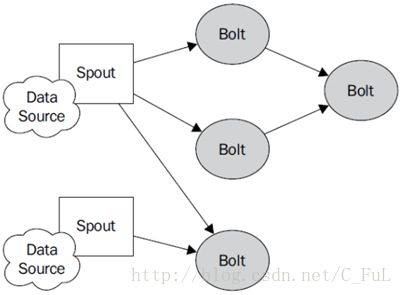
Topology:Storm中运行的一个实时应用程序的名称。(拓扑)
Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。参见Spout示意图
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。参见Bolt示意图
Tuple:消息发送的最下单元,是一个Tuple对象,对象有个List
Stream:源源不断地Tuple组成了Stream(表示数据的流向)
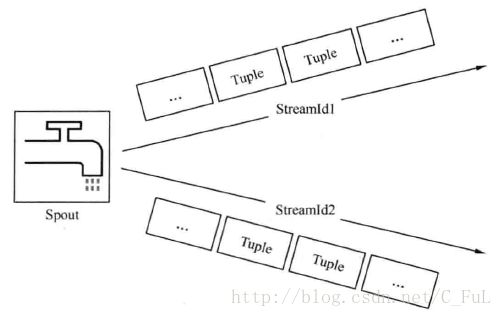
Spout 工作示意图
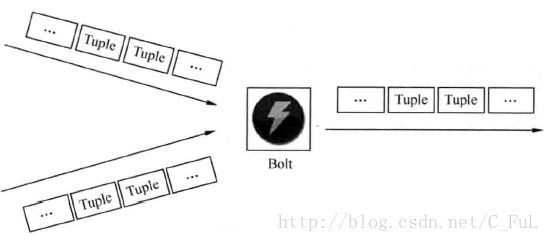
Storm中的核心组件Task中提到了分组一词,Task是各个节点之间进行分组的单位,那么什么是分组呐?在Storm中, 开发者可以为上游spout/bolt发射出的tuples指定下游bolt的哪个/哪些task(s)来处理该tuples。这种指定在storm中叫做对stream的分组,即stream grouping。
Storm分组方式
在Storm中有7中内置的分组方式,也可以通过实现CustomStreamGrouping接口来自定义分组。
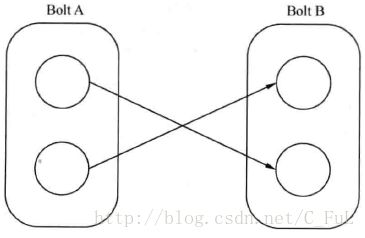
Shuffle 分组:
Task中的数据随机分配,可以保证同一级Bolt上的每个Task处理的Tuple数量一致
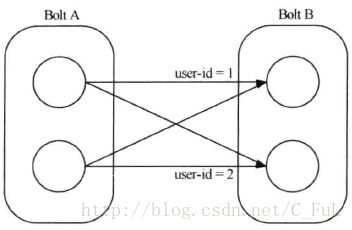
Fields 分组:
根据Tuple中的某一个Field或多个Field的值来划分。比如Stream根据user-id的值来分组,具有相同user-id值的Tuple会被分发到相同的Task中。如下图(具有不同user-id值的Tuple可能会被分发到其它Task中。比如user-id为1的Tuple都会分发给Task1,userid-2的Tuple可能在Task1上也可能在Task2上,但是同时只能在一个Task上)
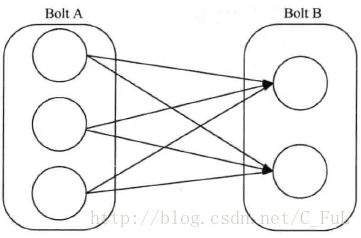
All分组:
所有的Tuple都会分发到所有的Task上
Global 分组:
整个Storm会选择一个Task作为分发的目的地,通常是具有最新ID的Task
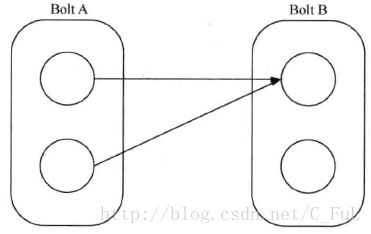
None 分组:
也就是你不关系如何在Task中做Stream的分发,目前等同于Shuffle分组
Direct 分组:
这是一种特殊的分组方式,也就是产生数据的Spout/Blot自己明确决定这个Tuple被Bolt的哪些Task所消费,如果使用Direct分组,需要使用OutputColletor的emitDirect方法来实现
Local or Shuffle 分组:
如果目标Bolt中的一个或多个Task和当前产生数据的Task在同一个Worker进程中,那么就走内部的线程通信,将Tuple直接发给当前Worker进程中的目的Task。否则,通Shuffle分组
Storm 总体架构图
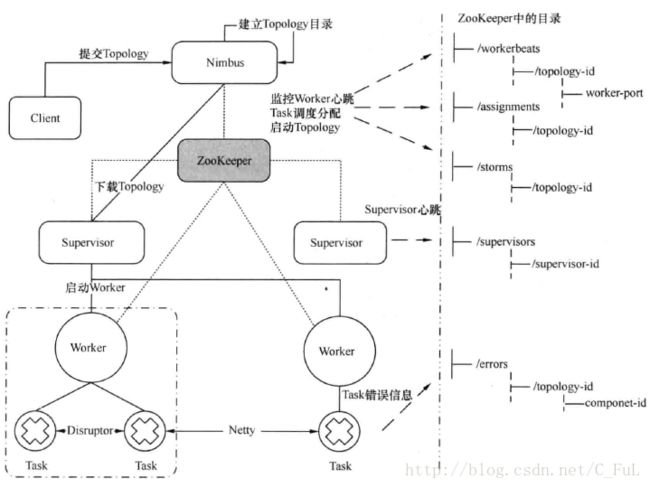
(1).客户端提交Topology到Nimbus
(2).Nimbus 针对该Topology建立本地目录
(3).Nimbus中的调度器根据Topology的配置计算Task,并把Task分配到不同的Worker上,调度的结果写入Zookeeper
(4).ZooKeeper上建立assignments节点,存储Task和Supervisor中Worker的对应关系。
(5).在ZooKeeper上创建workerbeats节点来监控Worker的心跳。
(6).Supervisor 去 ZooKeeper上获取分配的Task信息,启动一个或多个Worker执行。每个Worker上运行多个Task,Task由Executor来具体执行。
(7).Worker根据Topology信息初始化建立Task之间的连接,相同Worker内的Task通过DisrupterQueue来通信,不同Worker间默认采用Netty通信。
(8).然后整个Topology就运行起来了
Storm 的特性
(1).易用性:开发非常迅速,容易上手。只要遵循Topology、Spout和Bolt的编程规范即可开发出扩展性极好的应用。对于底层RPC、Worker之间冗余以及数据分流之类的操作,开发者完全不用考虑
(2).容错性:Storm的守护进程(Nimbus、Subervistor等)都是无状态的。状态保存在Zookeeper中,可以随意重启。当Worker失效或出现故障时,Storm自动分配新的Worker替换失效的Worker。
(3).扩展性:当某一级处理单元速度不够,可以直接配置并发数,即可线性地扩展性能。
(4).完整性:采用Acker机制,保证数据不会丢失;采用事务机制,保证数据准确性。由于Storm具有诸多优点,使用的业务领域和场景也越来越广泛。