图灵机器人之Python实现
学python也有一段时间了,最初也是被python简洁的理念所吸引入了这坑。所以每次用python写程序都是以解决问题为目标,不怎么喜欢做封装,感觉解决一件小事,十分钟的事非要花半小时封装个类反而违背了python的理念。今天闲来无事调用图灵机器人写了个聊天机器人,主要两个function,一个是getHtml(),爬取html页面;一个是handleHtml,解析出聊天部分内容,然后一个while 循环进行人机交互。下面贴上代码:
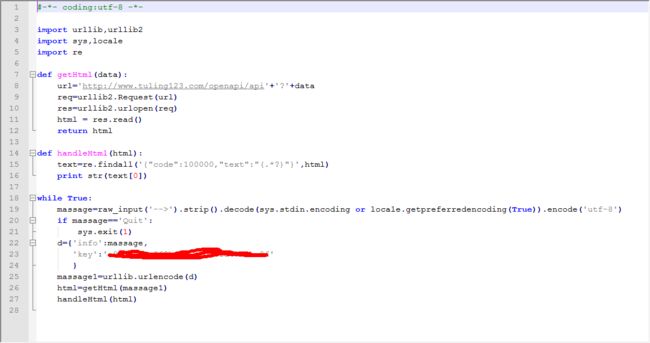
其实在爬虫中,常常遇到的问题大概就是编码问题了。特别是URL中传递的参数包含中文。
python2.7输入的字符串编码默认为assic,我们需要先将其转化为Unicode,然后encode成utf-8,因为urlencode接收的参数必须经过encode(编码)。编码操作主要就是encode(编码)和decode(解码),Unicode是一个字符集,就像一个很全字典,对应每个字符,Unicode字符串经过encode编码变成str字符串,相反,str字符串经过decode解码变成unicode。编码的操作核心就是要统一,在编码不统一时,我们建议都将编码转换成Unicode,然后在进行转换。
运行结果:
