基于小型训练集的卷积神经网络(kaggle - 猫狗分类)(《python深度学习》)
1 数据集简介与预处理
kaggle猫狗分类数据集是kaggle在2013年末用作一项视觉竞赛的一部分。整个数据集包含12500张狗和12500张猫共计25000张图片,数据集大小为543MB(压缩后)。在本例中采用其中4000张图片,其中,每个类别选用1000个样本的训练集、每个类别各500个样本的验证集以及每个类别各500个样本的测试集。在模型设计搭建前应将以上的分类分门别类的放到文件夹中,可以手动复制,也可以使用python os与shutil 编程实现。分类好应如下图所示: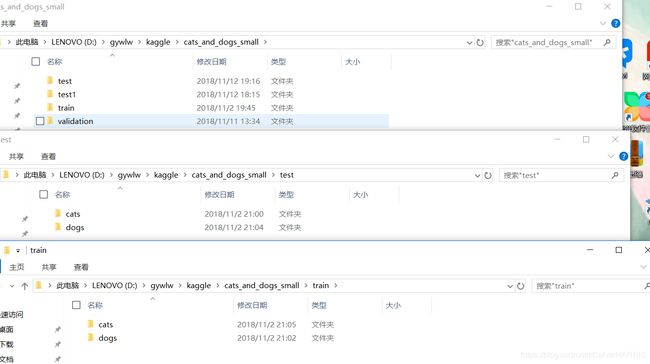
2构建网络
2.1模型构建
本例采用Conv2D(采用relu激活)和MaxPooling2D交替的卷积神经网络,考虑到图像的大小与复杂度等因素,相比于应用于MNIST数据集的简单卷积神经网络,应当适当的增加网络的容量。因此在本例中使用4组Conv2D和MaxPooling的组合,初始输入设定为150*150,在最后Flatten层之前得到的是一组7*7的特征图。后面全连接层包括一个节点数为512,激活函数为relu的隐藏层,以及激活函数为sigmoid的输出层,同时考虑到过拟合的问题,在输入层添加比例为50%的dropout。实现代码如下:
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',
input_shape = (150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))模型概览如下:

这里需要注意的是,减小的是特征图的尺寸(从150*150到7*7)然而特征图的深度应当逐渐增加(从32到128)在卷积神经网络连接到全连接层之前应当遵循这一宗旨。
2.2 编译模型
在优化器的选择上依然使用RMSprop优化器,同时考虑到二分类问题使用binary_crossentropy作为损失函数。代码如下:
model.compile(loss = 'binary_crossentropy',optimizer = optimizers.RMSprop(lr = 1e-4),
metrics = ['acc'])
2.3 输入数据的预处理
卷积神经网络接收的输入数据为浮点型的数据张量,而图片是以JPEG文件格式储存在硬盘中的,因此就需要将这些图片数据进行预处理。预处理要实现的目标有以下四点:
- 读取图像文件。
- 将JPEG文件转化为RGB像素网格。
- 将这些像素网格转化为浮点型张量。
- 将像素值缩放到0~1的区间范围。
在keras的preprocessing.image 中有一个图像处理的辅助模块ImageDataGenerator能够迅速的创建python生成器(关于python生成器的概念详见这里),将JPEG图像批量转化为符合卷积神经网络输入要求的浮点型张量。具体操作如下:
train_datagen = ImageDataGenerator(
rescale = 1./255, '''将所有数据缩放'''
rotation_range = 40, '''图像随机旋转范围'''
width_shift_range = 0.2,'''图像水平移动范围(总长的比例)'''
height_shift_range = 0.2, '''上下移动'''
shear_range = 0.2, '''随机错切变换角度'''
zoom_range = 0.2,'''随机缩放范围'''
horizontal_flip = True '''水平对称翻转''')
test_datagen = ImageDataGenerator(rescale = 1./255) #验证数据不要处理
train_generator = train_datagen.flow_from_directory(
train_dir, '''文件目录'''
target_size = (150,150),'''目标尺寸大小'''
batch_size = 32,
class_mode = 'binary') '''二分类(一个子文件夹一类)'''
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150,150),
batch_size = 32,
class_mode = 'binary')特别的,在本例中,考虑到样本的数量,在生成器中采用了随机旋转缩放等数据加强,因此,生成器能源源不断的生成符合输入要求且经过数据加强的数据张量。
3 拟合模型与绘图
3.1 拟合模型
与单一数据的fit生成器类似,在处理批量数据的时候采用fit_generator方法拟合。它首先需要接受生成器的生成数据,因为生成器的生成数据是不断生成的,因此需要在参数steps_per_epoch指定一次抽取多少数据(generator在训练集上一次生成32个数据,全部抽完需要100次,下面验证集同),在epochs参数指定循环次数。具体代码如下:
history = model.fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 100,
validation_data = validation_generator,
validation_steps = 50)3.2 绘图
绘制测试集与验证集的精度与损失图如下(100次循环):
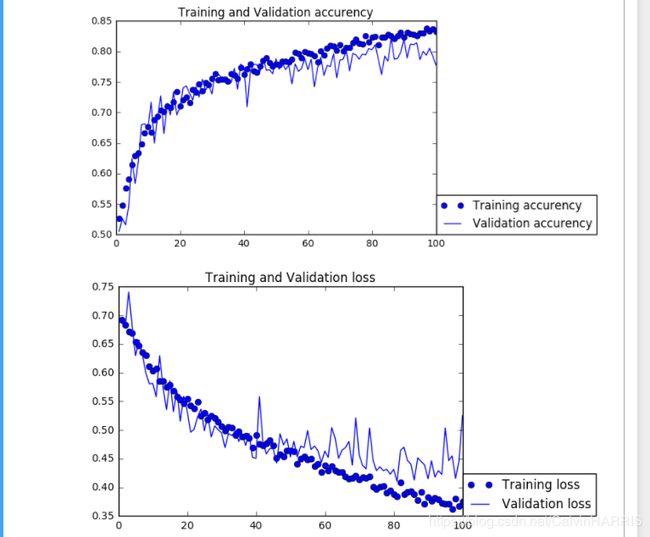
可见大约40次循环后进入过拟合,然而精度哪怕训练集经过100次循环仍然不够理想,虽然进行了样本随即处理但这与样本数量仍然不无关系。在测试集上验证精度如下:
可见有75%的正确率,效果不够理想。下例采用VGG16卷积核对网络进行优化。
附整体代码:
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
train_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\train'
validation_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\validation'
#数据预处理
train_datagen = ImageDataGenerator(
rescale = 1./255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,)
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size = (150,150),
batch_size = 32,
class_mode = 'binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150,150),
batch_size = 32,
class_mode = 'binary')
#build model
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',
input_shape = (150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',optimizer = optimizers.RMSprop(lr = 1e-4),
metrics = ['acc'])
#fit
history = model.fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 100,
validation_data = validation_generator,
validation_steps = 50)
test_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\test'
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
test_loss,test_acc = model.evaluate_generator(test_generator,steps = 50)
print("Test accurency:",test_acc)
print("Test loss:",test_loss)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epchs = range(1,len(acc)+1)
#绘图
plt.plot(epchs,acc,'bo',label = 'Training accurency')
plt.plot(epchs,val_acc,'b',label = 'Validation accurency')
plt.title('Training and Validation accurency')
plt.legend(bbox_to_anchor=(1,0),loc = 3,borderaxespad = 0)
plt.figure()
plt.plot(epchs,loss,'bo',label = 'Training loss')
plt.plot(epchs,val_loss,'b',label = 'Validation loss')
plt.title('Training and Validation loss')
plt.legend(bbox_to_anchor=(1,0),loc = 3,borderaxespad = 0)
plt.show()