基于VGG16预训练网络特征提取在小型训练集上的应用(kaggle - 猫狗分类)(《python深度学习》)
0 前言
在之前的例子中,我们采用一个从头开始训练的卷积神经网络在训练样本数共2000个的kaggle猫狗训练集上训练,哪怕采用了4组Conv2D和MaxPooling组合、随机图片变换、全连接输入层高达50%的dropout以及多达100次的循环最后通过绘图分析发现还是不可避免的较早的出现过拟合,最后在测试集上的正确率仅仅为75%。归根结底是因为样本数太少,即使通过图片的随机变换仍然只是在训练集上抓取特征,模型的泛化能力太低。因此在样本数量不能提高的情况下我们常采用预训练网络来行之有效的构造模型。本例采用的预训练模型架构是VGG16。
1 预训练网络——VGG16
VGG16是2014年开发的在ImageNet(多达140万张标记图像,1000种不同类别)训练好的大型卷积神经网络,因为ImageNet1000种分类包含猫狗的分类,因此可以认为基于此训练的VGG16能在本例上有良好的表现。
要想将VGG16应用到本例我们需要的是其已经训练好的卷积核,至于后面的全连接层丢弃不用,而卷积神经网络之所以能起到辨识的能力重点就在于全连接层之前的卷积核。全连接层分类器往往针对的是模型训练的类别,其中仅包括某个类别在整体中出现的概率。此外,密集连接层忽略了图像的位置信息,而这一信息是由卷积特征图描述的,如果位置对于问题很重要,那么密集连接层特征很大程度上是没用的。因此我们的任务就是将VGG16的卷积核移植到我们自行设计的全连接层上,移植的方法有两种:特征提取与微调模型,本例采用的是特征提取。
2 VGG16特征提取
2.1 特征提取简介
所谓的特征提取就是将要训练的数据输入到之前学习过的模型中,然后从中提取有用的特征,随后将这些特征输入到新的分类器进行训练。这里需要注意的是训练的仅仅是后面的分类模型也就是全连接层的参数,而卷积核的数据是不参与学习的,示意图如下:
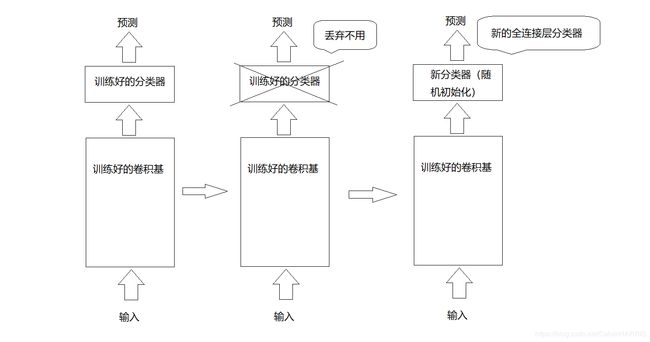
2.2 keras实例化
VGG16模型内置于Keras中输入如下代码导入:
from keras.applications import VGG16此外还要对输入类型等实例化:
conv_base = VGG16(
weights = 'imagenet',
include_top = False,
input_shape = (150,150,3))这里的参数含义为:
- weights 指定模型的初始化权重检查点。
- include_top True为连接密集连接层,本例设置为False。
- input_shape 指定输入数据类型。
查看一下实例化后卷积基模型:

可见最后一层的数据类型为(4,4,512),在本层后面添加一个全连接层的分类器。
3 全连接层分类器的添加与编译
3.1 添加方法综述
添加全连接层分类器有两种方法:
- 在数据集上独立先运行卷积基,将特征结果(4,4,512)以numpy数组的形式保存,随后再输入到全连接层。
- 在全连接层顶部添加VGG模型(模型数据锁住)。
两种方法各有利弊,总的来说,第一种方法的优点是速度快,计算代价小。因为i在卷积神经网络中最为费时的就是卷积计算的过程,没有一个好的GPU协同计算计算的时间将非常大。而第一种方法只过一遍卷积计算,随后的全连接层的计算就十分的快了。然而,正是因为只过了一遍的卷积计算没有经过数据加强,过拟合的风险就比较高。
相反的,第二种方法因为将模型添加在全连接层之前,这样就可以像普通的卷积神经网络一样,输入经过数据增强的图像数据,大大降低过拟合几率。由于每次数据输入都要运行卷积计算,那么运算的代价就变得十分的高。下面就分别采用两种方法进行实验。
3.2 无数据增强的快速特征提取
3.2.1 特征的提取
提取特征数据是在将数据先输入conv_base后得到的结果数据,然后再将其保存为numpy数组。这里获得输出结果用的是predict方法。具体实现如下:
def extract_features(directory,sample_count):
features = np.zeros(shape = (sample_count,4,4,512))
labels = np.zeros(shape = (sample_count))
generator = datagen.flow_from_directory(
directory,
target_size = (150,150),
batch_size = batch_size,
class_mode = 'binary')
i = 0
for input_batch,labels_batch in generator:
features_batch = conv_base.predict(input_batch)
features[i*batch_size : (i+1)*batch_size] = features_batch
labels[i*batch_size : (i+1)*batch_size] = labels_batch
i += 1
if i*batch_size >= sample_count:
break
return features,labels因为VGG16模型输出的数据是(4,4,512)结构的,所以先创建一个结构为(样本数,4,4,512)的全零矩阵和一个行数为样本数的标签矩阵。下面将每个批次的输出结果(通过conv_pridect())写到特征矩阵中等待接下来的输入全连接层处理。
3.2.2 全连接层的连接
最后我们得到的特征矩阵是一个(2000,4,4,512)的矩阵,将其flatten之后是一个(2000,4*4*512)的矩阵。将数据铺平:
train_features,train_labels = extract_features(train_dir,2000)
validations_features,validation_labels = extract_features(validation_dir,1000)
test_features,test_labels = extract_features(test_dir,1000)
train_features = np.reshape(train_features,(2000,4*4*512))
validations_features = np.reshape(validations_features,(1000,4*4*512))
test_features = np.reshape(test_features,(1000,4*4*512))
随后定义连接全连接层:
model = models.Sequential()
model.add(layers.Dense(256,activation = 'relu',input_shape = (4*4*512,)))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(optimizer = optimizers.RMSprop(lr = 2e-5),
loss = 'binary_crossentropy',
metrics = ['acc'])3.2.3 模型编译
下面将模型编译,与想象中一样编译的速度很快,数据也很快的进入了过拟合,在验证集上的正确率达到90%,代码与图像如下:
history = model.fit(train_features,train_labels,
epochs = 30,
batch_size = batch_size,
validation_data = (validations_features,validation_labels))
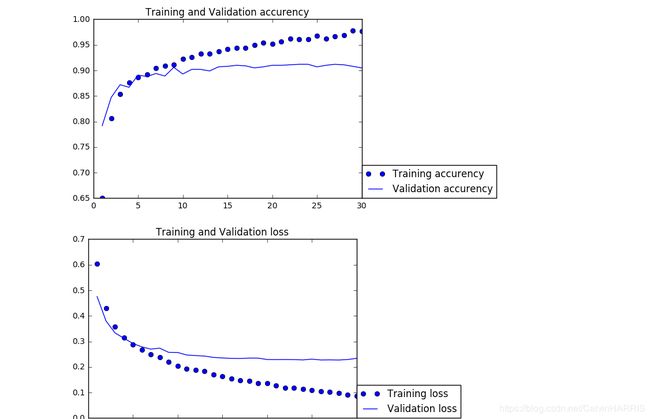
在测试样本上的正确率也有90%。

3.3 使用数据增强的特征提取
3.3.1 模型定义
本方法与常规的卷积神经网络类似,唯独在全连接层之前添加了例化好的VGG16模型,从而能将输入数据进行数据增强。在卷积基中必须锁住其数据,卷积核的参数不参与更新。其他的与普通卷积神经网络并无差异。模型代码如下:
conv_base = VGG16(
weights = 'imagenet',
include_top = False,
input_shape = (150,150,3))
conv_base.trainable = False
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
#model.add(layers.Dense(256,activation = 'relu'))
#model.add(layers.Dense(256,activation = 'relu'))
#model.add(layers.Dense(256,activation = 'relu'))
model.add(layers.Dense(256,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',
optimizer = optimizers.RMSprop(lr = 2e-5),
metrics = ['acc'])3.3.2 模型编译
代码与精度、损失图如下:
#数据预处理
train_datagen = ImageDataGenerator(
rescale = 1./255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode = 'nearest')
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
history = model.fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 30,
validation_data = validation_generator,
validation_steps = 50)
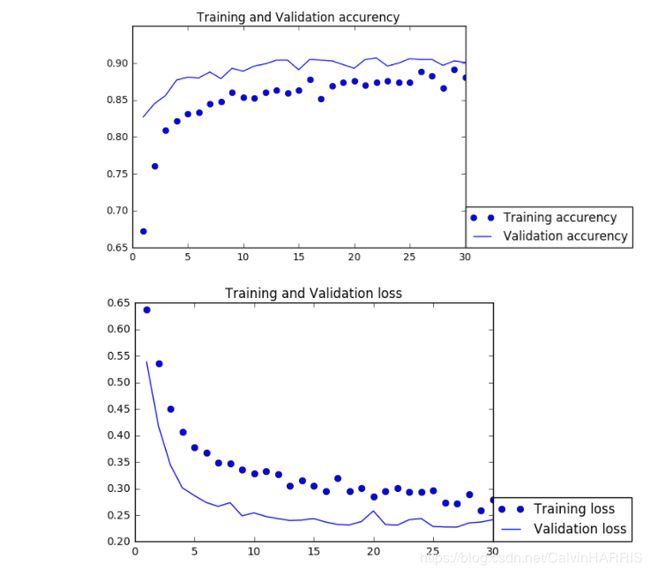
如图所示,经过30次的循环,由于输入数据经过了数据的增强自始至终都没有出现过拟合,在验证集上的精度要好于测试集验证集精度约为90%。然而与书上给出的参考正确率(96%)(p123)相比有较大的差距(模型结构完全一致)。因为没有过拟合,我将全连接层的隐藏层数增加到4层,发现正确率仍得不到显著增加(91%左右)且仍然未过拟合,在尝试了修改learningrate(增大)、修改优化器(采用Adam)精度始终在91%左右。未能达书上的结果。
4 随机图片验证
自行找了一些猫狗图片在模型上验证,在两个不同连接方式的模型上表现完全一致,如下图所示:



值得注意的是模型在预测最后一张图时均出错,将猫误认为狗,将图形局部放大后再给模型辨别:
辨别成功。推测可能是图上干扰因素太多导致模型认为图片不属于任意一类。因此假如输入一个不属于任意一类的图片进去:

如图,模型将人认为是狗,与上面出错的案例原因类似。
附整体代码:
#快速特征提取
from keras.applications import VGG16
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras import layers
from keras import optimizers
import matplotlib.pyplot as plt
conv_base = VGG16(
weights = 'imagenet',
include_top = False,
input_shape = (150,150,3))
train_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\train'
validation_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\validation'
test_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\test'
datagen = ImageDataGenerator(rescale = 1./255)
batch_size = 20
def extract_features(directory,sample_count):
features = np.zeros(shape = (sample_count,4,4,512))
labels = np.zeros(shape = (sample_count))
generator = datagen.flow_from_directory(
directory,
target_size = (150,150),
batch_size = batch_size,
class_mode = 'binary')
i = 0
for input_batch,labels_batch in generator:
features_batch = conv_base.predict(input_batch)
features[i*batch_size : (i+1)*batch_size] = features_batch
labels[i*batch_size : (i+1)*batch_size] = labels_batch
i += 1
if i*batch_size >= sample_count:
break
return features,labels
train_features,train_labels = extract_features(train_dir,2000)
validations_features,validation_labels = extract_features(validation_dir,1000)
test_features,test_labels = extract_features(test_dir,1000)
train_features = np.reshape(train_features,(2000,4*4*512))
validations_features = np.reshape(validations_features,(1000,4*4*512))
test_features = np.reshape(test_features,(1000,4*4*512))
model = models.Sequential()
model.add(layers.Dense(256,activation = 'relu',input_shape = (4*4*512,)))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(optimizer = optimizers.RMSprop(lr = 2e-5),
loss = 'binary_crossentropy',
metrics = ['acc'])
model.summary()
history = model.fit(train_features,train_labels,
epochs = 30,
batch_size = batch_size,
validation_data = (validations_features,validation_labels))
score = model.evaluate(test_features,test_labels,batch_size = 20)
print('The score:',score[0])
print('The accuracy:',score[1])
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
#绘图
epchs = range(1,len(acc)+1)
plt.plot(epchs,acc,'bo',label = 'Training accurency')
plt.plot(epchs,val_acc,'b',label = 'Validation accurency')
plt.title('Training and Validation accurency')
plt.legend(bbox_to_anchor=(1,0),loc = 3,borderaxespad = 0)
plt.figure()
plt.plot(epchs,loss,'bo',label = 'Training loss')
plt.plot(epchs,val_loss,'b',label = 'Validation loss')
plt.title('Training and Validation loss')
plt.legend(bbox_to_anchor=(1,0),loc = 3,borderaxespad = 0)
plt.show()
#自找图像辨识
from keras.preprocessing import image
predict_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\test1'
fnames = [os.path.join(predict_dir,fname) for fname in os.listdir(predict_dir)]
img_input = []
img_array = []
for i in range(len(fnames)):
img1 = image.load_img(fnames[i],target_size = (150,150))
img_array.append(img1)
img = image.img_to_array(img1)
img = img.reshape((1,) + img.shape)
img_input1 = conv_base.predict(img)
img_input.append(np.reshape(img_input1,(1,4*4*512)))
prediction = model.predict(img_input[i])
plt.imshow(img_array[i])
plt.show()
#print (prediction)
if prediction[0][0] == 1:
print("It's a dog!\n")
else:
print("It's a cat!\n")
#数据增强提取
from keras.applications import VGG16
import os
from keras.preprocessing.image import ImageDataGenerator
from keras import models
from keras import layers
from keras import optimizers
import matplotlib.pyplot as plt
conv_base = VGG16(
weights = 'imagenet',
include_top = False,
input_shape = (150,150,3))
conv_base.trainable = False
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256,activation = 'relu'))
model.add(layers.Dense(256,activation = 'relu'))
model.add(layers.Dense(256,activation = 'relu'))
model.add(layers.Dense(256,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',
optimizer = optimizers.RMSprop(lr = 2e-5),
metrics = ['acc'])
model.summary()
train_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\train'
validation_dir = 'D:\\gywlw\\kaggle\\cats_and_dogs_small\\validation'
#数据预处理
train_datagen = ImageDataGenerator(
rescale = 1./255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode = 'nearest')
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary')
history = model.fit_generator(
train_generator,
steps_per_epoch = 100,
epochs = 30,
validation_data = validation_generator,
validation_steps = 50)
#绘图
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epchs = range(1,len(acc)+1)
plt.plot(epchs,acc,'bo',label = 'Training accurency')
plt.plot(epchs,val_acc,'b',label = 'Validation accurency')
plt.title('Training and Validation accurency')
plt.legend(bbox_to_anchor=(1,0),loc = 3,borderaxespad = 0)
plt.figure()
plt.plot(epchs,loss,'bo',label = 'Training loss')
plt.plot(epchs,val_loss,'b',label = 'Validation loss')
plt.title('Training and Validation loss')
plt.legend(bbox_to_anchor=(1,0),loc = 3,borderaxespad = 0)
plt.show()