CUDA(19)之PTX优化原理
摘要
本文主要讲述CUDA中的PTX的原理实现和分析。
1. 不作优化的代码实现
Nvidia GTX 1050, CUDA 8.0测试代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
__global__ void gpu(int *d_ptr, int length) {
int elemID = blockIdx.x * blockDim.x + threadIdx.x;
for (int innerloops = 0; innerloops < 100000; innerloops++) {
if (elemID < length) {
//unsigned int laneid;
d_ptr[elemID] = elemID % 32;
}
}
}
void valid(int *h_ptr, int length) {
for (int elemID = 0; elemID> >(d_ptr, N);
cudaGetLastError();
cudaDeviceSynchronize();
// Finish timing
cudaEventRecord(stop, 0);
cudaEventSynchronize(start);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time_elapsed, start, stop);
// Print
printf("Time Used on GPU:%f(ms)\n", time_elapsed);
// CPU (results for validate)
valid(h_ptr, N);
int *h_d_ptr;
cudaMallocHost(&h_d_ptr, N * sizeof(int));
cudaMemcpy(h_d_ptr, d_ptr, N * sizeof(int), cudaMemcpyDeviceToHost);
bool bValid = true;
for (int i = 0; i Nvidia GTX 1050, CUDA 8.0测试结果如下:
![]()
Nvidia 780Ti, CUDA 7.5测试代码如下:
#include
#include
#include
#include
#include
__global__ void gpu(int *d_ptr, int length){
int elemID = blockIdx.x * blockDim.x + threadIdx.x;
for(int innerloops = 0; innerloops < 100000; innerloops++){
if (elemID < length){
//unsigned int laneid;
d_ptr[elemID] = elemID % 32;
}
}
}
void valid(int *h_ptr, int length){
for (int elemID=0; elemID>>(d_ptr, N);
checkCudaErrors(cudaGetLastError());
checkCudaErrors(cudaDeviceSynchronize());
// Finish timing
cudaEventRecord(stop,0);
cudaEventSynchronize(start);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time_elapsed,start,stop);
// Print
printf("Time Used on GPU:%f(ms)\n",time_elapsed);
// CPU (results for validate)
valid(h_ptr, N);
int *h_d_ptr;
checkCudaErrors(cudaMallocHost(&h_d_ptr, N *sizeof(int)));
checkCudaErrors(cudaMemcpy(h_d_ptr, d_ptr, N *sizeof(int), cudaMemcpyDeviceToHost));
bool bValid = true;
for (int i=0; i Nvidia 780Ti, CUDA 7.5测试结果如下:
![]()
2. PTX
PTX主要特点是预计算的索引值放到L1缓存,实现内存操作的预取优化,达到本案例中性能的大幅提升。
Nvidia 780Ti, CUDA 7.5测试代码如下:
#include
#include
#include
#include
#include
__global__ void gpu_ptx(int *d_ptr, int length){
int elemID = blockIdx.x * blockDim.x + threadIdx.x;
for(int innerloops = 0; innerloops < 100000; innerloops++){
if (elemID < length){
unsigned int laneid;
asm("mov.u32 %0, %%laneid;" : "=r"(laneid)); // 索引缓存
d_ptr[elemID] = laneid;
}
}
}
void valid(int *h_ptr, int length){
for (int elemID=0; elemID>>(d_ptr, N);
checkCudaErrors(cudaGetLastError());
checkCudaErrors(cudaDeviceSynchronize());
// Finish timing
cudaEventRecord(stop,0);
cudaEventSynchronize(start);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time_elapsed,start,stop);
// Print
printf("Time Used on GPU:%f(ms)\n",time_elapsed);
// CPU (results for validate)
valid(h_ptr, N);
int *h_d_ptr;
checkCudaErrors(cudaMallocHost(&h_d_ptr, N *sizeof(int)));
checkCudaErrors(cudaMemcpy(h_d_ptr, d_ptr, N *sizeof(int), cudaMemcpyDeviceToHost));
bool bValid = true;
for (int i=0; i Nvidia 780Ti, CUDA 7.5测试结果如下:
![]()
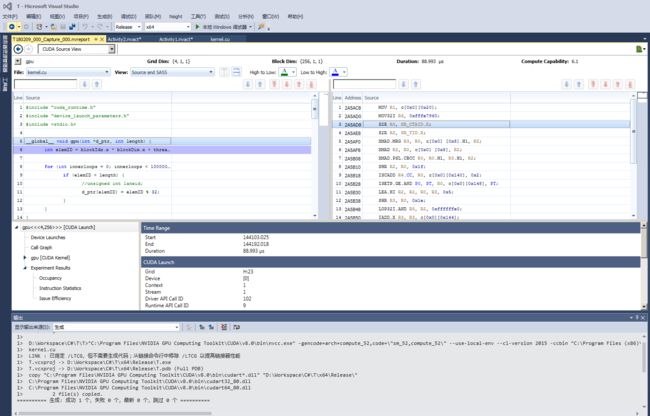
Nvidia GTX 1050, CUDA 8.0测试代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
__global__ void gpu_ptx(int *d_ptr, int length) {
int elemID = blockIdx.x * blockDim.x + threadIdx.x;
for (int innerloops = 0; innerloops < 100000; innerloops++) {
if (elemID < length) {
unsigned int laneid;
asm("mov.u32 %0, %%laneid;" : "=r"(laneid)); // 索引缓存
d_ptr[elemID] = laneid;
}
}
}
void valid(int *h_ptr, int length) {
for (int elemID = 0; elemID> >(d_ptr, N);
cudaGetLastError();
cudaDeviceSynchronize();
// Finish timing
cudaEventRecord(stop, 0);
cudaEventSynchronize(start);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time_elapsed, start, stop);
// Print
printf("Time Used on GPU:%f(ms)\n", time_elapsed);
// CPU (results for validate)
valid(h_ptr, N);
int *h_d_ptr;
cudaMallocHost(&h_d_ptr, N * sizeof(int));
cudaMemcpy(h_d_ptr, d_ptr, N * sizeof(int), cudaMemcpyDeviceToHost);
bool bValid = true;
for (int i = 0; i Nvidia GTX 1050, CUDA 8.0测试结果如下:
![]()