内存管理
虚拟内存
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块成为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不再物理内存的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
虚拟内存允许程序不用将地址空间的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得在有限的内存运行大程序成为可能。
分页系统地址映射
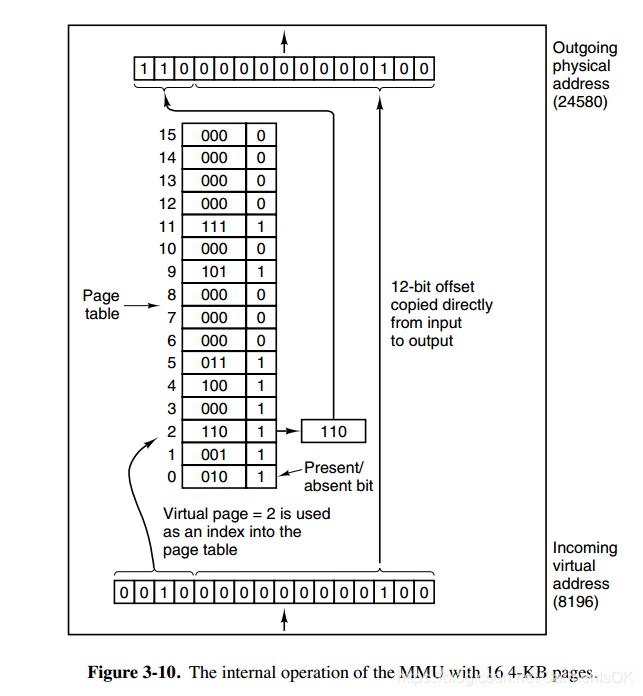
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)
一个虚拟地址分成两个部分:一个部分存储着页面号,一部分存储偏移量。
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法的主要目标是使得页面置换频率最低。
1、最佳(OPT)
说选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
【例子】
一个系统为某进程分配了3个物理块,并有如下页面引用序列:
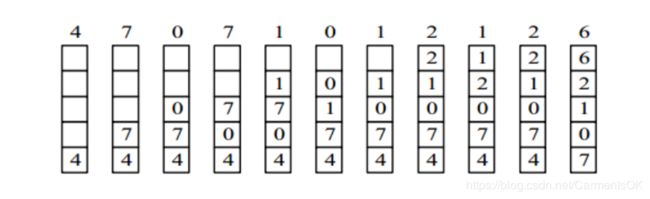
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
开始运行时,先将7,0,1三个页面装入内存。当进程要访问页面2时,产生缺页终端,会将页面7换出,因为页面7再次被访问的时间最长。
2、最近最久未使用(LRU,Least Recently Used)
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU将最近最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
Redis也是使用LRU作为缓存置换算法。
4,7,0,7,1,0,1,2,1,2,6
#include3、最近未使用(NRU,Not Recently Used)
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
- R=0,M=0
- R=0,M=1
- R=1,M=0
- R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4、先进先出(FIFO,First In First Out
选择换出的页面是最先进入的页面。
该算法会将那些经常被访问的页面也被换出,从而使缺页率升高。
5、第二次机会算法
FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。
6、时钟
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。
分段
虚拟内存采用的是分页技术,也就是将地址空间划分成固定大小的页,每一页再与内存进行映射。
下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。
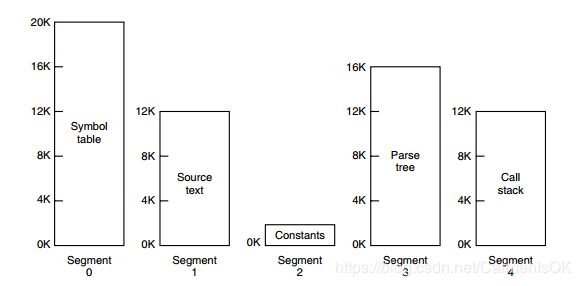
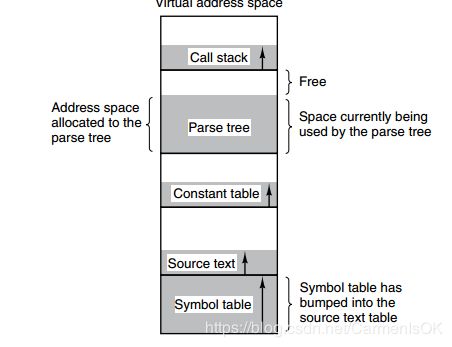 分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。
分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。
段页式
程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
分页与分段的比较
- 对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
- 地址空间的维度:分页是一维地址空间,分段是二维的
- 大小是否可以改变:页的大小不可变,段的大小可以动态改变。
- 出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。