zookeeper的原理
1.zookeeper集群角色
2.leader选举源码分析
3.ZAB协议
4.ZAB崩溃恢复模式
5.watch模式源码分析
6.数据存储
7.参考
1.zookeeper集群角色
a)leader
leader是zookeeper集群的核心。
1.事务请求的唯一调度者和处理者,保证集群事务处理的顺序性
2.集群内部各个服务器的调度者
b)follower
1.处理客户端非事务请求,以及转发事务请求给leader服务器
2.参与事务请求提议(proposal)的投票(客户端的一个事务请求,需要半数服务器投票通过以后才能通知leader commit; leader会发起一个提案,要求follower投票)
3.参与leader选举的投票
c)observer
观察zookeeper集群中最新状态的变化并将这些状态同步到observer服务器上
增加observer不影响集群中事务处理能力,同时还能提升集群的非事务处理能力
2.leader选举源码分析
源码地址:https://github.com/apache/zookeeper.git
需要的条件: jdk 1.7以上 、ant 、idea
a)找入口
zookeeper启动的时候有个日志输出,可以根据日志输出来跟踪查看leader选举
b)分析
>QuorumPeer.startLeaderElection
-->createElectionAlgorithm(三种选举算法leaderElection/AuthFastLeaderElection/FastLeaderElection
-->currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());//初始化自己的投票信息
--->getCurrentEpoch>readLongFromFile 从/tmp/zookeeper 里面读取数据Epoch
--->QuorumCnxManager 初始化数据,管理选举中和其他server的网络交互,选举时监听在专门的electionAddr上
---->receiveConnection 监听到数据返回,判断sid,sid越大代表权重高,其他服务器需要与该sid服务器建立连接
--->FastLeaderElection 默认选举算法
---->Messenger(就是QuorumCnxManager )
----->WorkerSender>从QuorumCnxManager::recvQueue中获取网络包,并将其发到FastLeaderElection::recvqueue中
----->WorkerReceiver>从FastLeaderElection::sendqueue中获取网络包,并将其放QuorumCnxManager::queueSendMap中,并发送到网络上
----->lookForLeader>QuorumPeer主线程会调用lookForLeader函数,它从recvqueue中获取别人发给server的选举数据,并将发给其他server的投票放到sendqueue中
c)概念
serverid : 在配置server集群的时候,给定服务器的标识id(myid)
zxid : 服务器在运行时产生的数据ID, zxid的值越大,表示数据越新
Epoch: 选举的轮数
server的状态:Looking、 Following、Observering、Leading
参考:https://www.cnblogs.com/siodoon/articles/5438076.html
d)流程总结
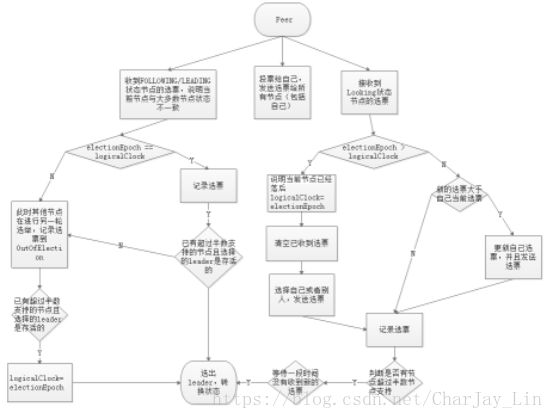
第一次初始化启动的时候server的状态: LOOKING
1.所有在集群中的server都会推荐自己为leader,然后把(myid、zxid、epoch)作为广播信息,广播给集群中的其他server, 然后等待其他服务器返回
2.每个服务器都会接收来自集群中的其他服务器的投票。集群中的每个服务器在接受到投票后,开始判断投票的有效性
a)判断逻辑时钟(Epoch) ,如果Epoch大于自己当前的Epoch,说明自己保存的Epoch是过期。更新Epoch,同时clear其他服务器发送过来的选举数据。判断是否需要更新当前自己的选举情况
b)如果Epoch小于目前的Epoch,说明对方的epoch过期了,也就意味着对方服务器的选举轮数是过期的。这个时候,只需要讲自己的信息发送给对方
c)如果Epoch==当前Epoch,则根据规则判断是否有规则获得leader(zxid最大的优先)
3.统计投票
3.ZAB协议
a)ZAB协议要求每个leader都要经历三个阶段,即发现,同步,广播。
(1)发现:即要求zookeeper集群必须选择出一个leader进程,同时leader会维护一个follower可用列表。将来客户端可以这follower中的节点进行通信。
(2)同步:leader要负责将本身的数据与follower完成同步,做到多副本存储。这样也是体现了CAP中高可用和分区容错。follower将队列中未处理完的请求消费完成后,写入本地事物日志中。
(3)广播:leader可以接受客户端新的proposal请求,将新的proposal请求广播给所有的follower。
b)原因
拜占庭将军问题
paxos协议主要就是如何保证在分布式环网络环境下,各个服务器如何达成一致最终保证数据的一致性问题
ZAB协议,基于paxos协议的一个改进
zookeeper并没有完全采用paxos算法, 而是采用zab Zookeeper atomic broadcast
zab协议为分布式协调服务zookeeper专门设计的一种支持崩溃恢复的原子广播协议
c)在zookeeper 的主备模式下,通过zab协议来保证集群中各个副本数据的一致性
d)zookeeper使用的是单一的主进程来接收并处理所有的事务请求,并采用zab协议,把数据的状态变更以事务请求的形式广播到其他的节点
e)zab协议在主备模型架构中,保证了同一时刻只能有一个主进程来广播服务器的状态变更
f)所有的事务请求必须由全局唯一的服务器来协调处理,这个的服务器叫leader,其他的叫follower,leader节点主要负责把客户端的事务请求转化成一个request事务提议(proposal),并分发给集群中的所有follower节点,再等待所有follower节点的反馈ack。一旦超过半数服务器进行了正确的反馈,那么leader就会commit这条消息

g)ZAB协议中主要有两种模式,第一是消息广播模式(第5点);第二是崩溃恢复模式
h)zookeeper集群中为保证任何所有进程能够有序的顺序执行,只能是leader服务器接受写请求,即使是follower服务器接受到客户端的请求,也会转发到leader服务器进行处理
4.ZAB崩溃恢复模式
a)什么情况下zab协议会进入崩溃恢复模式
当服务器启动时
当leader服务器出现网络中断、崩溃或者重启的情况
集群中已经不存在过半的服务器与该leader保持正常通信
b)zab协议进入崩溃恢复模式会做什么
(1)当leader出现问题,zab协议进入崩溃恢复模式,并且选举出新的leader。当新的leader选举出来以后,如果集群中已经有过半机器完成了leader服务器的状态同步(数据同步),退出崩溃恢复,进入消息广播模式
(2)退出崩溃恢复的要求:
确保已经被leader提交的proposal必须最终被所有的follower服务器提交。
确保丢弃已经被leader出的但是没有被提交的proposal。
(3)新选举出来的leader不能包含未提交的proposal,即新选举的leader必须都是已经提交了的proposal的follower服务器节点。同时,新选举的leader节点中含有最高的ZXID。这样做的好处就是可以避免了leader服务器检查proposal的提交和丢弃工作。
(4)当新的机器加入到集群中的时候,如果已经存在leader服务器,那么新加入的服务器就会自觉进入数据恢复模式,找到leader进行数据同步
c)进入崩溃模式的场景
(1)leader在提出proposal时未提交之前崩溃,则经过崩溃恢复之后,新选举的leader一定不能是刚才的leader。因为这个leader存在未提交的proposal。
(2)leader在发送commit消息之后,崩溃。即消息已经发送到队列中。经过崩溃恢复之后,参与选举的follower服务器(刚才崩溃的leader有可能已经恢复运行,也属于follower节点范畴)中有的节点已经是消费了队列中所有的commit消息。即该follower节点将会被选举为最新的leader。剩下动作就是数据同步过程
c)数据同步
(1)在zookeeper集群中新的leader选举成功之后,leader会将自身的提交的最大proposal的事物ZXID发送给其他的follower节点。follower节点会根据leader的消息进行回退或者是数据同步操作。最终目的要保证集群中所有节点的数据副本保持一致。
(2)数据同步完之后,zookeeper集群如何保证新选举的leader分配的ZXID是全局唯一呢?这个就要从ZXID的设计谈起。
ZXID是一个长度64位的数字,其中低32位是按照数字递增,即每次客户端发起一个proposal,低32位的数字简单加1。高32位是leader周期的epoch编号,至于这个编号如何产生(我也没有搞明白),每当选举出一个新的leader时,新的leader就从本地事物日志中取出ZXID,然后解析出高32位的epoch编号,进行加1,再将低32位的全部设置为0。这样就保证了每次新选举的leader后,保证了ZXID的唯一性而且是保证递增的。

d)问题
(1)假设一个事务在leader服务器被提交了,并且已经有过半的follower返回了ack。 在leader节点把commit消息发送给folower机器之前leader服务器挂了怎么办
zab协议,一定需要保证已经被leader提交的事务也能够被所有follower提交
zab协议需要保证,在崩溃恢复过程中跳过哪些已经被丢弃的事务
(2)主从架构下,leader 崩溃,数据一致性怎么保证?
leader 崩溃之后,集群会选出新的 leader,然后就会进入恢复阶段,新的 leader 具有所有已经提交的提议,因此它会保证让 followers 同步已提交的提议,丢弃未提交的提议(以 leader 的记录为准),这就保证了整个集群的数据一致性。
(3)选举 leader 的时候,整个集群无法处理写请求的,如何快速进行 leader 选举?
这是通过 Fast Leader Election 实现的,leader 的选举只需要超过半数的节点投票即可,这样不需要等待所有节点的选票,能够尽早选出 leader
参考
https://blog.csdn.net/junchenbb0430/article/details/77583955
https://yq.aliyun.com/articles/304722
5.watch模式源码分析
可以通过zk.exists、zk.getData进行监听,监听一次就没了
找入口,第一遍找主干,第二遍再回顾
1)客户端注册监听
>getData(final String path, Watcher watcher, DataCallback cb, Object ctx)
->WatchRegistration(3种监听模式)
-->ExistsWatchRegistration
-->DataWatchRegistration
-->ChildWatchRegistration
->cnxn.queuePacket 注册事件
-->sendThread.getClientCnxnSocket().packetAdded()
--->sendThread类分析
2)服务器数据变化把客户端监听的事件通知给客户端
3)关键类
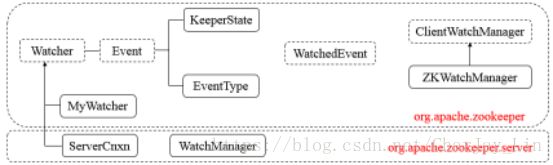
Watcher,接口类型,其定义了process方法,需子类实现。
Event,接口类型,Watcher的内部类,无任何方法。
KeeperState,枚举类型,Event的内部类,表示Zookeeper所处的状态。
EventType,枚举类型,Event的内部类,表示Zookeeper中发生的事件类型。
WatchedEvent,表示对ZooKeeper上发生变化后的反馈,包含了KeeperState和EventType。
ClientWatchManager,接口类型,表示客户端的Watcher管理者,其定义了materialized方法,需子类实现。
ZKWatchManager,Zookeeper的内部类,继承ClientWatchManager。
MyWatcher,ZooKeeperMain的内部类,继承Watcher。
ServerCnxn,接口类型,继承Watcher,表示客户端与服务端的一个连接。
WatchManager,管理Watcher。
4)总结
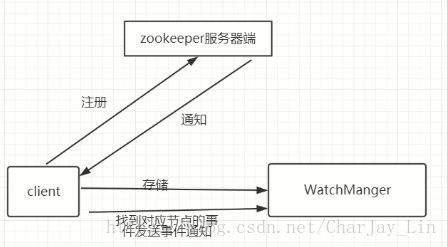
1.客户端先把事件存储在WatchManger
2.同时把事件注册到zookeeper服务器
3.服务器返回事件通知客户端
4.客户端去WatchManger找到对应节点的事件发送通知
参考:https://www.cnblogs.com/leesf456/p/6286827.html
6.数据存储
1)内存数据和磁盘数据
zookeeper会定时把数据存储在磁盘上。
配置里面的DataDir = 存储的是数据的快照
快照: 存储某一个时刻全量的内存数据内容
2)DataLogDir 存储事务日志
文件命名方式 log.zxid
![]()
查看事务日志的命令
java -cp :/data/program/zookeeper-3.4.10/lib/slf4j-api-1.6.1.jar:/data/program/zookeeper-3.4.10/zookeeper-3.4.10.jar org.apache.zookeeper.server.LogFormatter log.200000001
3)zookeeper 有三种日志
zookeeper.out //运行日志
快照 存储某一时刻的全量数据
事务日志 事务操作的日志记录
7.参考
http://blog.jobbole.com/104985/