【机器学习】网格搜索优化机器学习模型
机器学习中有两类参数:训练数据学习得到的参数、学习算法需要单独进行优化的参数(超参)
超参优化技巧:
网格搜索:通过寻找最优的超参值的组合以进一步提高模型的性能
通过指定不同的超参列表进行暴力穷举搜索,并计算得到评估每个组合对模型性能的影响,获得参数的最优组合。
实现网格搜索调优超参:
# 通过网格搜索优化超参数结合k折交叉验证
from sklearn.grid_search import GridSearchCV
from sklearn.svm import SVC
pipe_svc = Pipeline([('scl', StandardScaler()),
('clf', SVC(random_state=1))])
param_range = [0.0001, 0.001, 0.01, 0.1, 1.0, 10.0, 100.0, 1000.0]
param_grid = [{'clf__C': param_range,
'clf__kernel': ['linear']},
{'clf__C': param_range,
'clf__gamma': param_range,
'clf__kernel': ['rbf']}]
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=10,
n_jobs=-1)
gs = gs.fit(X_train, y_train)
print(gs.best_score_)
print(gs.best_params_)
初始化了一个GridSearchCV对象,用于对支持向量机流水线的训练与调优。
将GridSearchCV的param_grid参数以字典的方式定义为待调优参数。
# 使用独立的测试集通过模型进行性能评估:
clf = gs.best_estimator_
clf.fit(X_train, y_train)
print('Test accuracy: %.3f' % clf.score(X_test, y_test))
嵌套交叉验证:
使用嵌套交叉验证,估计的真实值误差与在测试集上得到的结果几乎没有差距
在嵌套交叉验证的外围循环中,将数据集划分为训练块和测试块。
内部循环中,基于外围训练块使用k折交叉验证。
完成模型后用测试块对模型进行评估。
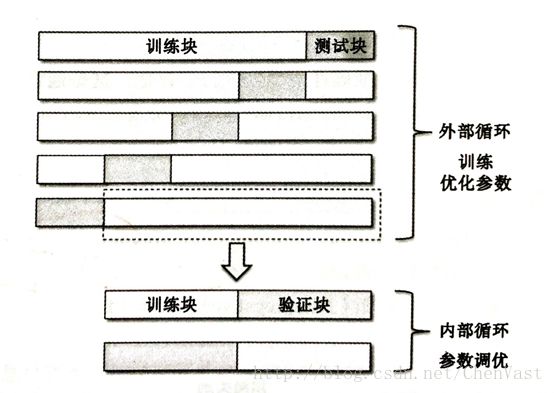
实现嵌套交叉验证:
gs = GridSearchCV(estimator=pipe_svc,
param_grid=param_grid,
scoring='accuracy',
cv=5)
scores = cross_val_score(gs, X_train, y_train, scoring='accuracy', cv=5)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))
![]()
使用嵌套交叉验证比较SVM模型和决策树分类器,只优化树的深度。
from sklearn.tree import DecisionTreeClassifier
gs = GridSearchCV(estimator=DecisionTreeClassifier(random_state=0),
param_grid=[{'max_depth': [1, 2, 3, 4, 5, 6, 7, None]}],
scoring='accuracy',
cv=5)
scores = cross_val_score(gs, X_train, y_train, scoring='accuracy', cv=5)
print('CV accuracy: %.3f +/- %.3f' % (np.mean(scores), np.std(scores)))