【机器学习】使用Python中的局部敏感哈希(LSH)构建推荐引擎
学习如何使用LSH在Python中构建推荐引擎; 一种可以处理数十亿行的算法
你会学到:
在本教程结束时,读者可以学习如何:
- 通过创建带状疱疹来检查和准备LSH的数据
- 选择LSH的参数
- 为LSH创建Minhash
- 使用LSH Query推荐会议论文
- 使用LSH构建各种类型的推荐引擎
目录
你会学到:
局部敏感哈希(LSH)建议简介
带状疱疹
为何选择LSH?
商业用途
LSH技术概述
将文本转换为一组带状疱疹
带状疱疹的例子
MinHash签名
关于MinHash签名的LSH
查询建议书
LSH清单
在PYTHON中实现LSH
第1步:加载Python包
第2步:探索您的数据
第3步:预处理您的数据
第4步:选择参数
第5步:为查询创建Minhash Forest
第6步:评估查询
在NIPS会议论文上测试我们的推荐引擎
结论
局部敏感哈希(LSH)建议简介
本教程将提供构建建议引擎的分步指南。我们将根据标题和摘要推荐会议论文。推荐引擎有两种主要类型:基于内容和协同过滤引擎。
- 基于内容建议仅使用有关所推荐项目的信息。没有关于用户的信息。
- 协作过滤利用用户信息。一般而言,数据包含每个用户使用的每个项目的喜欢或不喜欢。喜欢和不喜欢可能是隐含的,例如用户观看整部电影或明显像用户给电影竖起大拇指或良好的星级评级。
通常,推荐引擎基本上是寻找具有相似性的项目。我们可以将相似性视为具有相对较大交叉点的发现集。我们可以收集文档,电影,网页等项目的任何集合,并收集一组称为“带状疱疹”的属性。
带状疱疹
带状疱疹是一个非常基本的广泛概念。对于文本,它们可以是字符,unigrams或bigrams。您可以使用一组类别作为带状疱疹。带状疱疹只是将我们的文档简化为元素集,以便我们可以计算集合之间的相似性。
对于我们的会议论文,我们将使用从论文标题和摘要中提取的unigrams。如果我们有关于一组用户喜欢哪些论文的数据,我们甚至可以将用户用作带状疱疹。通过这种方式,您可以执行基于项目的协作过滤,其中您搜索已由相同用户评价为肯定的项目的MinHash。
同样,您可以将这个想法放在头上,并使项目成为基于用户的协作过滤的带状疱疹。在这种情况下,您将找到与其他用户具有相似正评级的用户。
让我们拿两个纸质标题并将它们转换成一组unigram带状疱疹:
- 标题1 =“使用增强神经网络的强化学习”
带状疱疹=['reinforcement', 'learning', 'using', 'augmented', 'neural', 'networks'] - 标题2 =“使用深度强化学习玩Atari”
带状疱疹=['playing', 'atari', 'with', 'deep', 'reinforcement', 'learning']
现在,我们可以通过观察两组之间的带状疱疹交叉的视觉表示来找到这些标题之间的相似性。在这个例子中,带状疱疹的总数(联合)是10,而2是交叉的一部分。我们将相似度测量为2/10 = 1/5。
集合的交集,其中元素是学术论文标题中的单词
为何选择LSH?
LSH可以被认为是降维的算法。当我们推荐大型数据集中的项目时出现的问题是,可能有太多项目来计算每对项目的相似性。此外,我们可能会为所有项目提供少量重叠数据。
为了解这种情况,我们可以考虑在存储所有会议论文时创建的词汇表矩阵。
传统上,为了提出建议,我们将为每个文档添加一列,并为每个遇到的单词添加一行。由于论文的文本内容差异很大,我们每列都会得到很多空行,因此稀疏性。为了提出建议,我们将通过查看哪些词是共同的来计算每一行之间的相似性。

这些问题激发了LSH技术。通过将行压缩为“签名”或整数序列,可以将此技术用作更复杂的建议引擎的基础,这样我们就可以比较论文而无需比较整个单词集。
与更传统的推荐引擎相比,LSH主要加快推荐流程。这些模型也可以更好地扩展。因此,定期在大型数据集上重新训练推荐引擎的计算密集程度远低于传统推荐引擎。在本教程中,我们将介绍推荐类似NIPS会议论文的示例。
商业用途
推荐引擎非常受欢迎。当您使用计算机,手机或平板电脑时,您很可能经常与推荐引擎进行交互。我们都在Netflix,亚马逊,Facebook,谷歌等网络应用程序上向我们推荐过推荐。以下是可能的用例的几个示例:
- 向客户推荐产品
- 预测客户对产品的评级
- 根据调查数据建立消费者群体
- 推荐工作流程中的后续步骤
- 推荐最佳实践作为工作流程步骤的一部分
- 检测抄袭
- 找到接近重复的网页和文章
LSH技术概述
LSH用于基于“相似性”的简单概念执行最近邻搜索。
我们说如果它们的集合的交集足够大,则两个项目是相似的。
这与集合的Jaccard相似性完全相同。回想一下上面相似的图片。我们对1/5相似性的最终衡量标准是Jaccard Similarity。
注: Jaccard相似度定义为两组的交集除以两组的并集。
注意,可以使用其他相似度量,但我们将严格使用Jaccard Similarity来完成本教程。LSH是一种基于邻域的方法,如k近邻(KNN)。正如您在下表中所看到的,与LSH相比,KNN等方法的规模较差。

n :项目数量:东西的个数
p :排列数
LSH的强大之处在于,随着物品数量的增长,它甚至可以使用Forest技术进行亚线性扩展。如前所述,目标是找到类似于查询集的集合。
一般方法是:
- 哈希项目使得类似项目很有可能进入同一个桶。
- 将相似性搜索限制为与查询项关联的存储桶。
将文本转换为一组带状疱疹
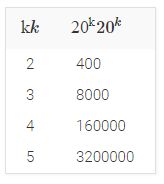
请记住,木瓦是一个单独的元素,可以像字符,单字符或双字母组合一样成为集合的一部分。在标准文献中,存在木瓦大小k的概念ķ,带状疱疹的数量等于20ķ20ķ。当你选择你的带状疱疹时,你会隐含地选择你的木瓦大小。
让我们使用字母表中的字母作为我们的带状疱疹的例子。你会有26个带状疱疹。对于我们的字母带状疱疹,k = 1,其中![]() 大约是经常使用的字母表中不同字符的数量。
大约是经常使用的字母表中不同字符的数量。
当将文件整理成unigrams时,我们会发现有很多可能的单词,即我们将使用大的k值k。下表给出了相对于木瓦大小k的带状疱疹数量的快速视图k。
在选择带状疱疹时,必须有足够的独特带状疱疹,以便在给定文件中出现木瓦的可能性很低。如果在所有集合中过于频繁地出现木瓦,则不会在集合之间提供显着区别。自然语言处理(NLP)中的经典示例是“the”。这太常见了。大多数NLP工作会删除正在考虑的所有文件中的“the”一词,因为它没有提供任何有用的信息。同样,您不希望使用将在每组中显示的带状疱疹。它降低了该方法的有效性。你也可以看到这个想法与TF-IDF一起使用。出现在太多文档中的术语会打折扣。
由于您希望任何单个木瓦出现在任何给定文档中的概率较低,我们甚至可能会看到包含双字母组,三元组或更大组的带状疱疹。如果两个文档共有大量的双字母组或三元组,则表明这些文档非常相似。
在寻找适当数量的带状疱疹时,请查看文档中出现的平均字符数或令牌数。确保选择足够的带状疱疹,使得带状疱疹明显多于文件中平均带状疱疹的数量。
带状疱疹的例子
对于本文,我们将推荐会议论文。因此,我们将通过一个会议论文标题的快速示例:
“关联数据库的自组织及其应用”
如果我们使用unigrams作为带状疱疹,我们可以删除所有标点,停用词和小写所有字符以获得以下内容:
['self', 'organization', 'associative', 'database', 'applications']
请注意,我们删除了常见的停用词,例如“of”,“and”和“its”,因为它们提供的价值很小。
MinHash签名
MinHash的目标是用一个较小的“签名”替换一个仍然保留底层相似性度量的大型集合。
为每个集创建一个MinHash签名:
- 随机地置换木瓦矩阵的行。例如,行12345 => 35421,所以如果“强化”在第1行,它现在将在第5行。
- 对于每一组(在我们的例子中为纸质标题),从顶部开始,找到出现在集合中的第一个木瓦的位置,即第一个木瓦在其单元格中有1。使用此木瓦编号表示集合。这是“签名”。
- 根据需要重复多次,每次将结果附加到集合的签名。
让我们通过一个具体的例子,我们已经提到了三个论文题目。我们已经把标题拼成了一组unigrams,所以我们可以把它们放到一个矩阵中并执行上面提到的所有步骤:
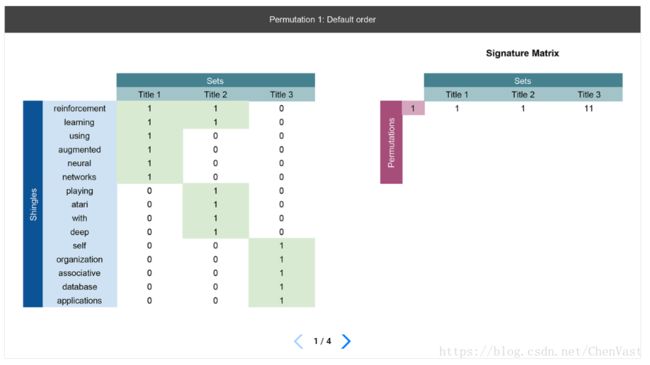
幻灯片1
在左侧,我们定义矩阵,列为列,行定义为三个标题中遇到的所有单词。如果标题中出现一个单词,我们会在该单词旁边放置一个单词。这将是我们的散列函数的输入矩阵。
请注意,我们在右边的签名矩阵中的第一条记录就是我们首先找到1的当前行号。有关更详细的说明,请参阅下一张幻灯片。

幻灯片2
我们执行第一个实行排列。请注意,单字组已经重新排序。同样,我们在右侧也有签名矩阵,我们将记录排列的结果。
在每个排列中,我们记录标题中出现的第一个单词的行号,即具有第一个单词的行。在此排列中,标题1和标题2的第一个单字组都在第1行中,因此记录1标题1和2下的签名矩阵的第1行。对于标题3,第一个单字组在第5行,因此在标题3的列下的签名矩阵的第一行中记录5。


幻灯片3-4
我们基本上执行与幻灯片2相同的操作,但我们在签名矩阵中为每个排列创建一个新行并将结果放在那里。
到目前为止,我们已经完成了三种排列,我们实际上可以使用签名矩阵来计算纸质标题之间的相似性。请注意我们如何将行列表中的15行压缩到签名矩阵中的3行。
在MinHash过程之后,每个会议论文将由MinHash签名表示,其中行数现在远小于原始木瓦矩阵中的行数。这是因为我们通过执行行排列来捕获签名。你应该比实际的带状疱疹需要更少的排列。
现在,如果我们考虑可能出现在所有纸质标题和摘要中的所有单词,我们可能有数百万行。通过行排列生成签名,我们可以有效地将行从数百万减少到数百,而不会丧失计算相似性得分的能力。
显然,您置换行的次数越多,签名就越长。这为我们提供了类似会议论文具有类似签名的最终目标。实际上,您可以观察以下内容:

为了更有效,在实践中使用随机散列函数而不是行的随机排列。
关于MinHash签名的LSH
上面的签名矩阵现在被分成bbr的乐队[R每个行,每个带分开散列。对于此示例,我们设置band b=2b=2,这意味着我们会考虑前两行相同的任何标题是相似的。我们制作的b越大,另一篇论文就越不可能匹配所有相同的排列。
例如,注意上面矩阵中的第一个频段,会议论文题目1和会议论文题目2将最终在同一个桶中,因为它们都具有相同的频段,而标题3完全不同。即使标题1和标志2的签名不同,它们仍然被拼凑在一起,并且被认为与我们的乐队大小相似。
最终,频带的大小控制具有给定Jaccard相似性的两个项目在同一桶中结束的概率。如果波段数量较大,则最终会得到更小的波段。例如,b=pb=p,其中p是排列的数量(即签名矩阵中的行)几乎肯定会导致只有一个项目的N个桶,因为在每个排列中只有一个项目完全相似。当我们选择带宽时,我们真正想要的是我们对误报的容忍度(没有类似的文档在同一个桶中结束)和漏报(类似的文档不会在同一个桶中结束)。
查询建议书
在进行新查询时,我们使用以下过程:
- 将查询文本转换为带状疱疹(标记)。
- 将MinHash和LSH应用于木瓦集,将其映射到特定存储桶。
- 在查询项和存储桶中的其他项之间进行相似性搜索。
通过实际使用LSH Forest算法进行有效搜索,可以实现效率。有关详细信息,请参阅M. Bawa,T。Condie和P. Ganesan,“LSH Forest:相似性搜索的自我调整指数。
LSH清单
作为执行LSH的最终清单,请确保完成以下步骤:
- 从您的可用数据集创建带状疱疹(例如,unigrams,bigrams,等级等)
- 建立一个m×n米×ñ 木瓦矩阵,其中出现在集合中的每个木瓦都标记为1,否则为0。
- 置换步骤2中的木瓦矩阵的行并构建新的p×np×ñ 签名矩阵,其中为集合出现的第一个瓦片的行的编号被记录用于签名矩阵的置换。
- 重复置换输入矩阵的行[ 数学处理错误]p时间和完全填充p×np×ñ 签名矩阵。
- 选择一个乐队大小bb 对于您将在LSH矩阵中的集合之间进行比较的行数。
在PYTHON中实现LSH
第1步:加载Python包
import numpy as np
import pandas as pd
import re
import time
from datasketch import MinHash,MinHashLSHForest第2步:探索您的数据
我们在本程中的目标是通过使用LSH快速查询所有已知的会议论文来对会议论文提出建议。作为一般规则,您应该始终检查您的数据。您需要彻底了解数据集,以便正确预处理数据并确定最佳参数。我们已经给出了一些选择参数的基本指南,它们都需要如上所述探索数据集。
出于本教程的目的,我们将使用简单的数据集。Kaggle有“神经信息处理系统(NIPS)会议论文。你可以在这里找到它们。
这些论文的初步数据探索可以在这里找到。
第3步:预处理您的数据
出于本文的目的,我们将仅使用粗略版本的unigrams作为我们的带状疱疹。我们使用以下步骤:
- 删除所有标点符号。
- 小写所有文字。
- 通过分隔任何空白区域来创建unigram带状疱疹(标记)。
为了获得更好的效果,您可以尝试使用自然语言处理库(如NLTK或spaCy)来生成unigrams和bigrams,删除停用词以及执行词形还原。
#预处理程序将根据空格将一串文本分割成单独的tokens/带状疱疹。
def preprocess(text):
text = re.sub(r'[^\w\s]','',text)
tokens = text.lower()
tokens = tokens.split()
return tokens您可以在下面看到预处理步骤的快速示例。
text = 'The devil went down to Georgia'
print('The shingles (tokens) are:', preprocess(text))The shingles (tokens) are: ['the', 'devil', 'went', 'down', 'to', 'georgia']
第4步:选择参数
为了开始我们的例子,我们将使用128的标准排列数。我们也将首先提出一个建议。
#排列
permutations = 128
#要返回的建议书数量
num_recommendations = 1
第5步:为查询创建Minhash Forest
为了创建Minhash Forest,我们将执行以下步骤:
- 使用要查询的每个字符串传入数据框。
- 使用上面的预处理步骤预处理一串文本。
- 设置MinHash中的排列数。
- MinHash字符串中所有带状疱疹的字符串。
- 存储字符串的MinHash。
- 对数据框中的所有字符串重复2-5。
- 构建所有MinHashed字符串的林。
- 索引您的森林以使其可搜索。
def get_forest(data, perms):
start_time = time.time()
minhash = []
for text in data['text']:
tokens = preprocess(text)
m = MinHash(num_perm=perms)
for s in tokens:
m.update(s.encode('utf8'))
minhash.append(m)
forest = MinHashLSHForest(num_perm=perms)
for i,m in enumerate(minhash):
forest.add(i,m)
forest.index()
print('It took %s seconds to build forest.' %(time.time()-start_time))
return forest
第6步:评估查询
为了查询构建的林,我们将按照以下步骤操作:
- 将文本预处理为带状疱疹。
- 为您的MinHash设置与用于构建林的相同数量的排列。
- 使用所有带状疱疹在文本上创建MinHash。
- 使用MinHash查询林并返回请求的推荐数。
- 提供推荐的每个会议论文的标题。
def predict(text, database, perms, num_results, forest):
start_time = time.time()
tokens = preprocess(text)
m = MinHash(num_perm=perms)
for s in tokens:
m.update(s.encode('utf8'))
idx_array = np.array(forest.query(m, num_results))
if len(idx_array) == 0:
return None # if your query is empty, return none
result = database.iloc[idx_array]['title']
print('It took %s seconds to query forest.' %(time.time()-start_time))
return result
在NIPS会议论文上测试我们的推荐引擎
我们将首先加载包含所有会议论文的CSV并创建一个将标题和摘要合并到一个字段中的新字段,这样我们就可以使用title和abstract来构建带状疱疹。
最后,我们可以查询任何文本字符串,例如标题或一般主题,以返回推荐列表。请注意,对于下面的示例,我们实际上选择了会议论文的标题。当然,我们将确切的论文作为我们的建议之一。
db = pd.read_csv('papers.csv')
db['text'] = db['title'] + ' ' + db['abstract']
forest = get_forest(db, permutations)
It took 12.728999853134155 seconds to build forest.num_recommendations = 5
title = 'Using a neural net to instantiate a deformable model'
result = predict(title, db, permutations, num_recommendations, forest)
print('\n Top Recommendation(s) is(are) \n', result)
It took 0.006001949310302734 seconds to query forest.
Top Recommendation(s) is(are)
995 Neural Network Weight Matrix Synthesis Using O...
5 Using a neural net to instantiate a deformable...
5191 A Self-Organizing Integrated Segmentation and ...
2069 Analytic Solutions to the Formation of Feature...
2457 Inferring Neural Firing Rates from Spike Train...
Name: title, dtype: object
结论
正如快速的最后一点,您可以使用此方法构建大量推荐引擎。您不必仅限于我们演示的基于内容的过滤。您还可以将这些技术用于Collaborative Filtered Recommendation Engines。
总而言之,本教程中概述的过程代表了Locality-Sensitive Hashing的介绍。这里的材料可以作为一般指导。如果您正在处理大量项目,并且您的相似度量是Jaccard相似度,则LSH提供了一种非常强大且可扩展的方式来提出建议。
原文:
https://www.learndatasci.com/tutorials/building-recommendation-engine-locality-sensitive-hashing-lsh-python/