妄谈大型网站技术架构
引
网络架构这个问题,我认为不是一个后台、架构师等等才需要考虑的问题,不管是前端也好,移动端也好,都应该多考虑考虑这个层面的问题,包括之后公司对你的要求也是这样的,不是说你会写业务会写功能就很ok,而是要求你有更大、更深的一些看法。
演化历程
先说一说每个做web的同学都应该了解一下的网站发展演化的历程。这个历程是怎么样的呢?
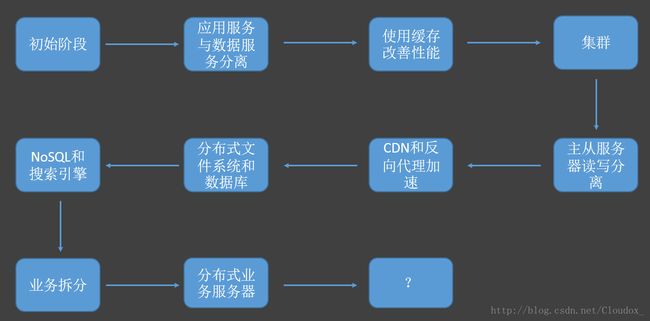
首先,在刀耕火种的原始时代,web是最简单的应用、数据库、文件全部都在一台服务器上,比如用php开发后台,用mysql做数据库,都在一个机器里面,这是最原始的阶段。
随着业务的发展,就会产生一些新的需求,比如性能的问题。最开始的一个解决手段是把服务和数据分离,直白地说就是分为应用服务器、文件服务器、数据库服务器之类的。你读的时候不同服务器之间是有数据的传输的。这时你的应用服务器可能CPU性能比较好,而数据库服务器可能IO比较快,它们就会有这个区别。
再往后就会使用缓存来改善性能,缓存分为本地缓存、分布式缓存等。然后是集群,解决高并发。还有主从数据库读写分离,如果你读操作比较多,可能会有很多从服务器提供给你去读,写的时候就保证只写一个主服务器,写之后有一个同步的策略,保证其他从服务器的数据一致性,这样读操作就可以分担给多个从服务器,主服务器压力就比较下。
然后是代理,CDN和反向代理,主要也是用来做缓存的。CDN叫内容分发网络,就是当你请求的时候从离你最近的服务器去请求,比如大公司可能部署了很多地区服务器,有的在武汉,有的在北京,我在武汉请求的时候,可能请求的是武汉的服务器,离它比较近,反应可能也比较快。反向代理是实现CDN的一种技术。
后来就开始使用NoSQL,比如MongoDB,之前也讲过,一种非结构化的数据库。
当你技术发展到一定程度之后,如果还是不能满足,那可以尝试把业务拆分,不要认为技术可以解决一切,有时候把业务拆分一下也可以解决你的问题。
误区
在考虑架构时有一些误区是我们要避免的。
一个是不要在一开始就盲目地追随大公司的技术方案,比如腾讯怎么做的呀,淘宝怎么做的呀。有时候小公司有小公司自身适合的方案,我们实验室也有一些适合实验室的,比如有一些框架大公司不用的但是因为比较快我们也会用,不要去老是想着大公司是怎么做的。
再就是不要为了技术而技术,当然对我们来说,很多时候就是想学习新技术,但在公司中真的有时候不一定最新的最火的就是最好的最适合你的,还是要根据需求来看。
最后,不要想着技术可以解决所有问题,有时候一个问题你要从技术层面来解决可能要费九牛二虎之力,但可能业务上稍微折中一点,换一种方式,也可以解决这个问题,而技术就可以省很大的力气,这样可能效果会更好。
指标
我们的标题是大型网站技术架构,那什么样的架构才是好的网站架构呢?我们从下面几个方面来考量它:
- 性能。性能是我们平常说的最多的,最直白的来说就是响应速度。
- 可用性。可用性是什么?比如说保证一周七天24小时都是可用的,我们经常听到一些大公司说他们的服务可用性达到几个9,比如五个9,就是99.999%的时间都是可用的,不会出现服务器挂了的情况。
- 伸缩性。当量变大的时候,你可能需要扩展服务器,这时候你可以在不影响原有服务,不暂停服务的情况下去加,这样伸缩性就比较好, 如果你要新加一个服务器还要把服务给停掉,这时候就说明你的伸缩性很差。
- 扩展性。扩展性就是在你需求增加了的时候,好不好扩展,如果代码设计的很差,那每次加了新需求要变动的就会很大。
- 安全性。安全性很好理解,网络安全嘛。
性能
先说性能这个指标,性能可以分前端的性能优化和后台的性能优化。
前端比如说减少HTTP请求的次数;使用浏览器缓存;启用压缩;CSS放在页面最上面,JS放在最下面;减少Cookie;使用CDN缓存加速;反向代理。
后台的话比如多线程、把操作做成异步的、资源复用、优化数据结构、垃圾回收机制等等。
我们完成一个功能以后,后面你再去看一下,有很多地方都是可以优化的,这个时候才是帮你更上一层楼的地方。第一步肯定是先从一个什么都不会的人到能把功能搭出来,第二步就是能不能把你自己做过的功能的性能再优化一下,这就是你更出彩的一个亮点。
高可用性
高可用性有哪些指标呢?我们一个一个看。
首先是数据,数据要持久,可以持久的保存在这里,对用户来说是长时间可访问的,如果做了主从读写分离,或者集群、分布式,那对每个数据库服务器之间的数据是要有策略来保持它一致的,不能说已经写了刷新了主服务器的数据了,读从服务器的时候还是原来的数据,那这时候其实读到的数据就是错误的。
当做分布式、集群的时候,我会有很多台服务器,那这时候某一台服务器断电、挂掉,总之这一台服务器跪了,根据负载均衡,你之前有些请求会被分到这一台服务器上,那你就需要一种检测方式来检测所有的服务器当前是不是运转良好的,比如用心跳检测。
要保障可用性很重要的一个点就是要做好测试,这个测试很多时候不是一批人在那点来点去,而是做成自动化测试,由机器来做这个事情。比如你做一轮测试操作,机器会自动生成对应的测试代码,那之后有新功能变化的时候,每一次都去跑一遍这个测试代码,它会自动去对你这个东西测试。
当我们发布新系统的时候,可以不直接就发布到正式服务器上去,而是先发布到一个验证服务器上去,在这个上面去看它运行有没有问题,跟我们用的测试库有点相似,如果出了问题就去处理,这就叫预发布验证。
还有一个叫做灰度发布的,灰度就是说,你在增加新的功能的时候,不是一下子给所有的用户都可以访问到这个新功能,而是先进行小范围用户的测试,只开放给部分的用户,但是对于用户来说是没有感知的,给哪部分用户是随机的,或者采用什么策略来挑选,而用户之间不知道你比我多一个功能,通过这一小部分用户就可以检查这个功能是不是有什么问题,当确定没问题之后就可以全部开放出去了。
使用git、svn来做代码控制,方便你出了问题进行回滚。
高伸缩性
伸缩性,我们刚刚说了,就是你加服务器时可以不用停服务,做到很方便的扩容。比如我有很多个服务器,那我肯定是要做一个负载均衡的,什么叫负载均衡呢?我加服务器时为了缓解并发量等问题,那我就要保证有一种策略让它可以各个服务器得到的访问量是比较均衡的,这就是负载均衡。
均衡有很多种策略,比如轮询、加权轮询(就是轮询的时候着重偏向于一些服务器,比如它们的性能好一些)、随机、最少连接(将请求给当前连接数最少的服务器)、源地址散列。
负载均衡可以在很多方面去做,比如HTTP重定向负载均衡、DNS域名解析负载均衡、反向代理负载均衡、IP负载均衡、数据链路层负载均衡等等。
对于数据库来说,要满足伸缩性可以做主从读写分离,上面也说过。还有分库、表分片。主要要保证数据的完整性和一致性。
可扩展性
可扩展性是当我们加需求的时候保证代码比较好“加”,那很重要的一点就是你的耦合性要低,每个层面做每个层面的事情,否则你要改点东西就会很怕影响到别的问题。
数据库用NoSQL也会更方便扩展。
此外,可以利用开放平台建设生态圈。这里就不单单是指业务上要实现新的需求,扩展性不一定是我们自己做的,可能是别人来做,让我们的服务扩散的更大。直白地说就是腾讯、微博、微信、豆瓣等等都在提供的开放API和接口,让你去使用它们的服务。这其实都是在帮他们扩展他们的生态圈,但其实也是帮我们更快的获得一些流量,互惠互利。
实例
讲了这么多,我们来看一个实例——新浪微博。
新浪微博有一个点比较有意思,想要分享一下。在以前,比如一个明星发了微博,可能他的关注量很大,那他的所有关注者都要接收这一条消息,那就可能要给大量的用户推送,怎么做呢?因为量很大,所以一定会有问题的。微博以前的做法是“同步推”,当有新微博后,立马推送到所有关注者的消息列表中,这样就会很慢,甚至超出服务器处理能力。
后来微博就改成了“异步推拉结合”的方式,首先发了微博后,这个任务给到任务处理的消息队列就返回,发的服务就不管了,消息队列就给所有正在刷微博的关注了的用户推这个消息,没有在线的用户先不管他。没有在线的用户后来上线后,会刷新消息列表,会去拉取新的微博,这时候才从最近的代理服务器获取这个新的消息,这样就可以大大的缓解它需要实时推送的量。
还有一些访问量很大的热门微博,如果你全部都在主服务器做访问,那压力肯定很大,所以,我们刷到的微博基本都不是新浪微博主服务器的内容,都是从缓存服务器上得到的,比如武汉有一个缓存服务器,我们就是从这里得到的,都不是说真正意义上最新的数据。
微博会建很多数据中心,让用户就近访问,也用来做容灾备份。此外微博也做了很多别的工作,我们就不细讲了。
问题探讨
这里提一组开放性的问题供大家探讨,是关于微信抢红包的。我们都知道抢红包的金额是随机的,那这个随机数额怎么分?此外,什么时候分?对于特殊时间的高并发抢红包需求,怎么处理这个高并发?抢红包的数据又怎么存储?
参考书目:《大型网站技术架构:核心原理与案例分析》
版权所有:http://blog.csdn.net/cloudox_