推荐系统-用户标签预测算法基础实践-决策树2
推荐系统-用户标签预测算法基础实践
1.泰坦尼克号获救人员识别实战
- 加强iris的代码实战(掌握)
- 代码版本一 : 未经过pca降温的X
#1.进行数据的读入---导入数据
from sklearn.datasets import load_iris
iris=load_iris()
#2.对数据进行简单的统计分析和图形化的展示
print(iris.keys())#['data', 'target', 'target_names', 'DESCR', 'feature_names']
print("iris data:",iris.data)
print("iris data:",type(iris.data))#iris data: - 代码版本二 : X经过PCA降维处理
#1.进行数据的读入---导入数据
from sklearn.datasets import load_iris
iris=load_iris()
#2.对数据进行简单的统计分析和图形化的展示
print(iris.keys())#['data', 'target', 'target_names', 'DESCR', 'feature_names']
print("iris data:",iris.data)
print("iris data:",type(iris.data))#iris data: - 泰坦尼克号的问题
- 加载数据–pandas和自身的数据
- 预处理
- 特征工程—类别型数据的处理
- 建立模型
- 模型预测
- 模型校验
代码
#1.读取数据
import pandas as pd
import os
datapath=os.path.join(".","tantanic.txt")
tantanic=pd.read_csv(datapath)
# 信息展示函数
def show_data_info():
print(tantanic.shape) # (1313, 11)
print(tantanic.info())
import seaborn as sns
import matplotlib.pyplot as plt
sns.catplot(x="sex", y="survived", hue="pclass", kind="bar", data=tantanic);
plt.show()
# 2.线性回归理论基础及算法详解
-
线性回归----监督学习的连续值预测问题
-
回归分为几类:
-
简单线性回归
- y=kx+b
- 目的:求解K和b
-
多元线性回归
- y=w0+w1x1+w2x2…
- 目的:求解w0,w1,w2
-
如何求解最优解参数?
- 利用平方损失(经验风险)求解参数
- 求解导数,令导数为0,求解驻点
- 利用梯度下降法结合导数进行学习
- X(k+1)=X(k)-alpha(学习率)*df(梯度算子)
-
3.线性回归房价预测实战
- 汽车销量预测
- 利用pandas读取和处理数据
- 特征工程
- 建立线性回归模型
- 预测
- 代码实现
import pandas as pd
cardata=pd.read_csv("./car.csv")
print(cardata)
# Miles Deliveries Travel Time
# 0 100 4 9.3
# 1 50 3 4.8
# 2 100 4 8.9
# 3 100 2 6.5
# 4 50 2 4.2
# 5 80 2 6.2
# 6 75 3 7.4
# 7 65 4 6.0
# 8 90 3 7.6
# 9 90 2 6.1
X=cardata.drop(labels="Travel_Time",axis=1)
y=cardata.Travel_Time
print(X)
print(type(X)) #- 房价预测
- 从sklearn中加载数据
- 读取数据集中关键信息
- X=boston.data和y=boston.target
- 切分数据
- 训练模型
- 模型预测
- 模型校验 : mae(平均绝对误差)、mse(均方误差)、r2
- Lasso回归:线性回归损失函数+L1正则
- Ridge回归:线性回归损失函数+L2正则
- Elasticnet回归:线性回归损失函数+L1正则+L2正则
代码展示 :
#读取数据
from sklearn.datasets import load_boston
bostan=load_boston()
print(bostan.keys())#dict_keys(['data', 'target', 'feature_names', 'DESCR'])
print(bostan.DESCR) #:Number of Instances: 506 -:Number of Attributes: 13 numeric/categorical predictive
print(bostan.data)
print(bostan.target)
print(bostan.feature_names)
# ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
# 'B' 'LSTAT']
#数据处理
X=bostan.data
y=bostan.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=22,test_size=0.2)
# print(X_train)
# print(y_train)
#GBDT模型建立
from sklearn.ensemble import GradientBoostingRegressor
lr=GradientBoostingRegressor()
#LR模型建立
# from sklearn.linear_model import LinearRegression
# lr=LinearRegression()
#DTR模型建立
# from sklearn.tree import DecisionTreeRegressor
# lr=DecisionTreeRegressor()
lr.fit(X_train,y_train)
#模型预测
y_pred=lr.predict(X_test)
print(y_pred)
#模型校验
print("model in trains set score is:",lr.score(X_train,y_train))
print("model in tests set score is:",lr.score(X_test,y_test))
# model in trains set score is: 0.9782530327891484
# model in tests set score is: 0.8442713715157044
#mae\mse\r2
from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score
print("mae:",mean_absolute_error(y_test,y_pred))
print("mse",mean_squared_error(y_test,y_pred))
# mae: 3.4240698961589606
# mse 20.765767538052017
print("r2",r2_score(y_test,y_pred)) #r2 0.7658020514461032
4.Cart回归树(DecisionTreeRegressor)原理详解
- Cart树
- 特征选择
- Cart树特征选择依赖于Gini系数或平方误差最小化
- 决策树生成
- Cart树算法----二叉树
- 决策树剪枝===>Cart树剪枝方法是后剪枝
- 后剪枝
- 特征选择
- Cart树的回归树:采用平方误差最小化策略
- 回归树是二叉树
- 寻找二分节点的特征以及特征的取值—寻找切分点以及切分变量
- 算法步骤:
- 1.选择最优切分点和切分变量,使得j和s达到最优
- 2.使用选择的j和s划分区域,给出最终的输出值
- 3.递归调用上述的子区域中寻找最优切分点以及切分变量
- 4.将输入空间划分为M个区域,生成决策树
- 图解

- Cart树的分类树:采用Gini系数选取特征
5.Cart分类树(Classfication Tree)原理简介
- Cart树分类树:
- 分类树是二叉树,衡量指标是GINI系数
- Cart树思想:
- 首先选择最佳切分点以及最佳切分变量
- 其次,求解集合的Gini系数,在所有的特征以及取值中获取到Gini系数最小的特征以及特征值
- 其次,递归调用Cart树产生的方法,直到满足停止迭代的条件为止
- 最后得到分类树
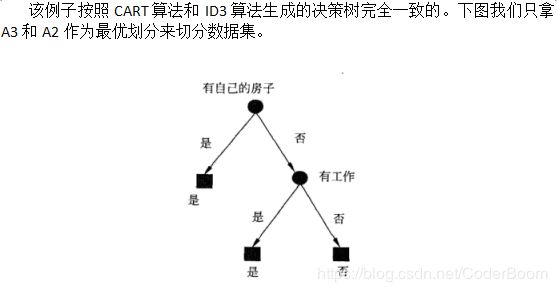
- Cart分类树例子:
- Cart树是分类和回归树
- 基于gini系数进行分类----计算集合的Gini系数
- 求解最小的Gini系数的值作为最优切分点和切分变量
- 如果仍然有样本点没有被分类,继续划分,寻找下一个划分点以及划分变量
- 步骤图解
数据集

6.基尼系数
- gini系数:
- Gini系数公式
- 通用 :
Gini=sum(pi(1-pi)) - 二分类情况 :
Gini=2pi(1-pi) Gini=1-sum(pi**2)===> pi为同一特征占类别标签的比例
- 通用 :
- 如下 : A特征的某一特征值的Gini系数
GINI(D,A)=|D1|/|D|*Gini(D1)+|D2|/|D|*Gini(D2)- Gini(D1)表示A特征下的Gini系数
- Gini系数公式
7.Cart树剪枝
- 树的剪枝–先剪枝和后剪枝
- Cart树采用的是后剪枝
- Cart树剪枝算法由两步组成 : 从下往上
- 1.首先从生成算法产生的决策树T0底端开始不断剪枝,直到T0的根节点,形成一个子树序列;
- 2.然后通过交叉验证法在独立的验证数据集上对子树序列进行测试,从中选择最优子树。
- 采用剪枝系数来确定如何剪枝?—得到最小的a值
- 图解



8.Cart树实战回归和分类问题
-
Cart树区别于ID3和C4.5区别
- 二叉树
- 分类树使用的是Gini系数
- 在回归树上无差别—mse和mae
-
Cart树总结 :
创建分类树递归过程中,CART每次都选择当前数据集中具有最小Gini信息增益的特征作为结点划分决策树。
ID3算法和C4.5算法虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支、规模较大,CART算法的二分法可以简化决策树的规模,提高生成决策树的效率。对于连续特征,CART也是采取和C4.5同样的方法处理。为了避免过拟合(Overfitting),CART决策树需要剪枝(后剪枝)。预测过程当然也就十分简单,根据产生的决策树模型,延伸匹配特征值到最后的叶子节点即得到预测的类别。 -
代码如下
# 网格搜索主要用来选择给定中的最优的超参数 , 并且可以将训练出来的超参数使用到模型中
from sklearn import tree, datasets
from sklearn.model_selection import GridSearchCV
iris = datasets.load_iris()
parameters = {'criterion':('gini', 'entropy'), 'splitter':["random", "best"],
'max_depth': [1,2,3,10,12],
'min_samples_split': (2,3),
'max_features': (1,2,3)}
dtc = tree.DecisionTreeClassifier()
# criterion="gini",
# splitter="best",
# max_depth=None,
# min_samples_split=2,
# min_samples_leaf=1,
# min_weight_fraction_leaf=0.,
# max_features=None,
# random_state=None,
# max_leaf_nodes=None,
# min_impurity_decrease=0.,
clf = GridSearchCV(dtc, parameters, cv=5)
clf.fit(iris.data, iris.target)
print(clf.best_params_)
# {'criterion': 'gini', 'max_depth': 12, 'max_features': 3, 'min_samples_split': 3, 'splitter': 'best'}
# ...
# GridSearchCV(cv=5, error_score=...,
# estimator=SVC(C=1.0, cache_size=..., class_weight=..., coef0=...,
# decision_function_shape='ovr', degree=..., gamma=...,
# kernel='rbf', max_iter=-1, probability=False,
# random_state=None, shrinking=True, tol=...,
# verbose=False),
# fit_params=None, iid=..., n_jobs=None,
# param_grid=..., pre_dispatch=..., refit=..., return_train_score=...,
# scoring=..., verbose=...)
print(sorted(clf.cv_results_.keys()))
# ...
# ['mean_fit_time', 'mean_score_time', 'mean_test_score',...
# 'mean_train_score', 'param_C', 'param_kernel', 'params',...
# 'rank_test_score', 'split0_test_score',...
# 'split0_train_score', 'split1_test_score', 'split1_train_score',...
# 'split2_test_score', 'split2_train_score',...
# 'std_fit_time', 'std_score_time', 'std_test_score', 'std_train_score'...]
Cart回归树实战波士顿房价代码
# 1.导入数据
# 1.1 从sklearn.dataset导入波士顿房价数据读取器
from sklearn.datasets import load_boston
# 1.2 从读取器中读取房价数据存储在变量boston中
boston = load_boston()
# 1.3 输出数据描述等信息
print(boston.DESCR)
print(boston.keys())
print(boston.data)
print(boston.target)
print(boston.feature_names)
# ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
# 'B' 'LSTAT']
# 2. 从sklearn.model_selection中导入数据分割器
from sklearn.model_selection import train_test_split
# 2.1 导入numpy并重命名为np
import numpy as np
# 2.2 数据处理
X = boston.data
y=boston.target
# 2.3 随机采样20%的数据构建测试样本 , 其余作为训练样本
X_train,X_test,y_train,y_test = train_test_split(X, y, random_state=22, test_size=0.2)
# 2.4 分析回归目标值的差异
print("The max target value is : ",np.max(boston.target))
# The max target value is : 50.0
print("The min target value is : ",np.min(boston.target))
# The min target value is : 5.0
print("The average target value is : ",np.mean(boston.target))
# The average target value is : 22.532806324110677
# 3. 特征工程
from sklearn.linear_model import LinearRegression
# 从sklearn.preprocessing导入数据标准化模块
from sklearn.preprocessing import StandardScaler
# 3.1 分别初始化对特征和目标值的标准化器
ss_X = StandardScaler()
ss_y = StandardScaler()
# 3.2 分别对训练和测试数据的特征以及目标值进行标准化处理
X_train = ss_X.fit_transform(X_train)
X_test = ss_X.transform(X_test)
y_train = ss_y.fit_transform(y_train.reshape(-1, 1))
y_test = ss_y.transform(y_test.reshape(-1, 1))
# 4. 决策树分类器
# 4.1 从sklearn.tree中导入DecisionTreeRegressor
from sklearn.tree import DecisionTreeRegressor
# 4.2 使用默认配置初始化DecisionTreeRegressor
dtr = DecisionTreeRegressor()
# 4.3 用波士顿放假的训练数据构建回归树
dtr.fit(X_train,y_train)
# 4.4 使用默认配置的单一回归树对测试数据进行预测 , 并将预测值存储在变量dtr_y_pred中
dtr_y_pred = dtr.predict(X_test)
# 4.5 使用R-squard , MSE和MAE指标对三种配置的支持向量机(回归)模型在相同测试集上进行性能评估
from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error
print("R-squard value of DecisionTreeRegressor is : %.2f%%"%(dtr.score(X_test,y_test)*100))
# R-squard value of DecisionTreeRegressor is : 79.60%
print("The mean squard error value of DecisionTreeRegressor is : ",mean_squared_error(ss_y.inverse_transform(y_test),ss_y.inverse_transform(dtr_y_pred)))
# The mean squard error value of DecisionTreeRegressor is : 18.08392156862745
print("The mean absolute error value of DecisionTreeRegressor is : ",mean_absolute_error(ss_y.inverse_transform(y_test),ss_y.inverse_transform(dtr_y_pred)))
# The mean absolute error value of DecisionTreeRegressor is : 3.1490196078431376
9.随机森林(Random Forest Classifier)简介及集成学习基础
- 随机森林
- 随机:构建森林需要多样化的----如何随机?怎么随机?
- 森林:由大于等于2颗树组成的森林
- 集成学习算法
- 并行学习
- 随机森林 ---- 举手表决???
- Bagging算法
- 串行学习
- Boosting
- Adaboost算法
- GBDT算法
- XGBoost算法
- 并行学习
10.随机森林算法详解
- 随机森林在以决策树为基学习器构建**Bagging集成(样本的随机选取[行])的基础上,进一步在决策树的训练过程中引入随机属性[列]**选择。
- 随机森林算法(random-forest)
- 算法思想:根据样本有放回的抽样,N次抽样得到N个样本,组成数据子集,在根据特征或属性的抽样得到不同的列特征,进而组合为新的数据子集,通过gini系数或entropy等参数确定每棵决策树,从而根据随机森林表决得到最终结果
- 算法步骤:
- 1.将所有的样本有放回抽样,得到抽样后的样本子集
- 2.在继续对特征或属性列进行抽样,log2d特征,组成数据子集
- 3.将不同的数据子集结合机器学习算法构建不同的机器学习模型,构建随机森林模型
- 4.通过随机森林中每棵决策树得到预测结果,根据少数服从多数的原则进而对数据进行分类。
- 算法改进:
- XGBoost中结合并行学习和串行学习的方式,特别是借鉴了随机森林对行or列进行随机的特征
- 随机森林随机性体现在哪里?
- 1.样本的随机性 ------ Bagging算法中提到
- 2.属性随机性 -------- log2d、sqrt(d)
- 随机森林简单、容易实现、计算开销小 ; 随机森林随着学习器数目的增加,随机森林通常会收敛到更低的泛化误差。
- 随机森林的优点 :
- (1)分类结果更加准确
- (2)可以处理高维度的属性,并且不用做特征选择
- (3)即使有很大部分数据遗失,仍可以维持高准确度
- (4)学习过程快速
- (5)在训练完成后,能够给出哪些属性比较重要
- (6)容易实现并行化计算
- (7)在训练过程中,能够检测到属性之间的相互影响
- 随机森林API : https://scikit-learn.org/0.17/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier
11.随机森林算法分类及回归实战
-
skleran的随机森林
- 分类—RandomForestClassifier----gini
- 代码实战
#1.进行数据的读入---导入数据 from sklearn.datasets import load_iris iris=load_iris() #2.对数据进行简单的统计分析和图形化的展示 print(iris.keys())#['data', 'target', 'target_names', 'DESCR', 'feature_names'] print("iris data:",iris.data) print("iris data:",type(iris.data))#iris data:print("iris target:",iris.target) print("iris targetname:",iris.target_names) print("iris DESCR:",iris.DESCR) print("iris features_names:",iris.feature_names) #['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] # import pandas as pd # df=pd.DataFrame(iris) # print(df) #2.1绘制图形 import seaborn as sns import matplotlib.pyplot as plt # sns.pairplot(iris, hue="sepal length (cm)") # plt.show() #3.确定特征和标签-X和y X=iris.data y=iris.target #4.1降维---pca from sklearn.decomposition import PCA pca=PCA(n_components=2) X=pca.fit_transform(X)#Fit the model with X. print(":"*1000) print(X) print(":"*1000) # print(pca.explained_variance_)#[0.24301994 0.03386828 0.01034326 0.00170887] from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=22) #4.特征处理-特征工程 from sklearn.preprocessing import StandardScaler,MinMaxScaler sc=MinMaxScaler() #feature_range : tuple (min, max), default=(0, 1) #"""Standardize features by removing the mean and scaling to unit variance X_train_std=sc.fit_transform(X_train) # """Fit to data, then transform it. X_test_std=sc.transform(X_test) # """Perform standardization by centering and scaling #5.建立机器学习模型 from sklearn.ensemble import RandomForestClassifier dtc=RandomForestClassifier() dtc.fit(X_train_std,y_train) #6.利用模型进行预测 y_pred=dtc.predict(X_test_std) print(y_pred) #7.校验模型 print("model in trainset score is:",dtc.score(X_train_std,y_train)) print("model in testset score is:",dtc.score(X_test_std,y_test)) # model in trainset score is: 1.0 # model in testset score is: 1.0 # #7.保存模型 # from sklearn.externals import joblib # joblib.dump(dtc,"dtctree.pkl") # #8.模型可视化 # from sklearn.tree import export_graphviz # export_graphviz(dtc,filled=True) - 回归—RandomForestRegressor----mse
- 代码实战
#读取数据 from sklearn.datasets import load_boston bostan=load_boston() print(bostan.keys())#dict_keys(['data', 'target', 'feature_names', 'DESCR']) print(bostan.DESCR) #:Number of Instances: 506 -:Number of Attributes: 13 numeric/categorical predictive print(bostan.data) print(bostan.target) print(bostan.feature_names) # ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO' # 'B' 'LSTAT'] #数据处理 X=bostan.data y=bostan.target from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=22,test_size=0.2) # print(X_train) # print(y_train) #模型建立 from sklearn.ensemble import RandomForestRegressor lr=RandomForestRegressor() lr.fit(X_train,y_train) #模型预测 y_pred=lr.predict(X_test) print(y_pred) #模型校验 print("model in trains set score is:",lr.score(X_train,y_train)) print("model in tests set score is:",lr.score(X_test,y_test)) # model in trains set score is: 0.977707567959114 # model in tests set score is: 0.8214221038623839 #mae\mse\r2 from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score print("mae:",mean_absolute_error(y_test,y_pred)) print("mse",mean_squared_error(y_test,y_pred)) # mae: 3.4240698961589606 # mse 20.765767538052017 print("r2",r2_score(y_test,y_pred)) #r2 0.7658020514461032
12.集成学习算法注意事项
- 集成学习中并行学习方式需要进行投票表决
- 三种方式
- 结果一致
- 多数为主
- 相对多数为主
- 三种方式
- 集成学习结果并不一定会提高样本的学习的结果
- 集成学习提升性能
- 集成学习不起作用
- 集成学习起负作用
13.Bagging算法原理
- 基于Boostrip抽样----自助采样
- 结果:63.2%比例被抽样,36.8%比例不被抽样
- Boostrip采用的是行采样
- Bagging算法:
- 算法思想:首先采用基于bootstrip的样本的抽样得到T个数据的子集,由每一个数据的子集训练得到模型,通过模型得到多个预测结果,通过少数服从多数的原则进行最终分类。
- 算法原理:
- 1.基于Bootstrip抽样进行样本抽样,得到抽样的T个集合
- 2.将T个数据子集通过不同的机器学习算法形成机器学习模型
- 3.通过机器学习模型得到预测结果,对预测结果进行统计得到出现次数最多的分类结果
- 算法改进:
- 随机森林(增加属性抽样)
- Bagging算法性能
- (1)Bagging是一个很高效的集成学习算法
- (2)Bagging与下面讲的AdaBoost只适用于二分类不同,它能不经修改地用于多分类、回归任务。
- (3)自助bootstrap采样过程还给Bagging带来了另一个优点:由于每个基学习器只使用了初始训练集中约63.2%的样本,剩下的约36.8%样本可用作验证集来泛化性能进行“包外样本评估(即:不同于训练数据的样本)”。
- (4)从偏差-方差分解角度看,Bagging主要关注降低方差,因此他在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更为明显。
- Bagging算法总结 : Bagging算法首先采用M轮自助采样法,获得M个包含N个训练样本的采样集。然后,基于这些采样集训练出一个基学习器。最后将这M个基学习器进行组合。组合策略为:
- (1)分类任务采用简单投票法:即每个基学习器一票
- (2)回归问题使用简单平均法:即每个基学习器的预测值取平均值。
14.Bagging算法实战
- Bagging算法参数
- estimator参数指定学习器–KNN , 默认的是决策树
- bootstrip抽样 ===> 样本(行)抽样
- bootstrip_features抽样 ===> 特征(列)抽样
- estimator参数指定学习器–KNN , 默认的是决策树
- Bagging分类和回归
- BaggingClassifier
- 分类代码实战
#1.进行数据的读入---导入数据
from sklearn.datasets import load_iris
iris=load_iris()
#2.对数据进行简单的统计分析和图形化的展示
print(iris.keys())#['data', 'target', 'target_names', 'DESCR', 'feature_names']
print("iris data:",iris.data)
print("iris data:",type(iris.data))#iris data: - BaggingRegressor
- 回归代码实战
# 读取数据
from sklearn.datasets import load_boston
bostan = load_boston()
print(bostan.keys()) # dict_keys(['data', 'target', 'feature_names', 'DESCR'])
print(bostan.DESCR) #:Number of Instances: 506 -:Number of Attributes: 13 numeric/categorical predictive
print(bostan.data)
print(bostan.target)
print(bostan.feature_names)
# ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
# 'B' 'LSTAT']
# 数据处理
X = bostan.data
y = bostan.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=22, test_size=0.2)
# print(X_train)
# print(y_train)
# 模型建立
from sklearn.ensemble import BaggingRegressor
lr = BaggingRegressor()
lr.fit(X_train, y_train)
# 模型预测
y_pred = lr.predict(X_test)
print(y_pred)
# 模型校验
print("model in trains set score is:", lr.score(X_train, y_train))
print("model in tests set score is:", lr.score(X_test, y_test))
# model in trains set score is: 0.9732165103639384
# model in tests set score is: 0.7859351887744748
# mae\mse\r2
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print("mae:", mean_absolute_error(y_test, y_pred))
print("mse", mean_squared_error(y_test, y_pred))
# mae: 3.4240698961589606
# mse 20.765767538052017
print("r2", r2_score(y_test, y_pred)) # r2 0.7658020514461032
**总结:**对于单棵决策树很容易产生过拟合,Bagging就可以有它的优势。Bagging是一种降低模型方差的一种有效方法,但是对于降低模型得偏差效果不大,这也是我们选择未剪枝决策树等低偏差分类器作为集成算法成员分类器的原因。
Q : Bagging如何降低模型方差 ?
模型过拟合出现的时候就是方差的出现 , 相当于对过拟合的优化
模型欠拟合出现的时候就是偏差的出现
15.Boosting算法原理
-
Boosting—串行学习方法 , 可将弱学习器升为强学习器的算法
-
Boosting框架:
- 1.训练基学习器
- 2.根据第一个基学习器对分对或分错的样本进行加权
- 3.根据各个分类器效果对不同的学习器进行加权,学习器的加权
-
Boosting算法机制
- (1)先从初始训练集训练出一个基学习器
- (2)在根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续得到最大的关注。
- (3)然后基于调整后的样本分布来训练下一个基学习器;
- (4)如此重复进行,直至基学习器数目达到实现指定的值T为止。
- (5)再将这T个基学习器进行加权结合得到集成学习器。
-
Boosting算法,存在两个问题
- 1.在每一轮中如何调整训练集,使训练的弱分类器得以进行;(调整样本权值)
- 2.如何将各个弱分类器联合起来形成强分类器。(调整模型权值)
-
如果每一步的弱预测模型生成都是依据损失函数的梯度方向,则称之为梯度提升(GradientBoosting)
-
补充 :
均方误差的目标函数最优值(取定值)是均值绝对误差的目标函数的最优解是中位数
16.Adaboost算法原理
-
Adaboost算法----自适应增强算法
-
Adaboost:**"关注"被错分的样本,“器重”**性能好的弱分类器
- 样本权重调整
- 分类器权重调整
(1)不同的训练集—>调整样本权重
(2)“关注”—>增加错分样本权重
(3)“器重”—>好的分类器权重大
(4) 样本权重间接影响分类器权重
-
Adaboost算法步骤:
- 1.对数据集中N个样本进行权值的初始化,初始化为1/N
- 2.训练基分类器对于分错的样本增加他的权重,分对的样本降低它的权重
- 3.调整分类器的权重,得到最终的分类器
-
AdaBoost算法的两个核心步骤:
- 权值调整:AdaBoost算法提高那些被前一轮基分类器错误分类样本的权值,而降低那些被正确分类样本的权值。从而使得那些没有得到正确分类的样本,由于权值的加大而受到后一轮基分类器的更大关注。
- 基分类器组合:AdaBoost采用
加权多数表决的方法- 加大分类误差率较小的弱分类器的权值,使得它在表决中起到较大的作用
- 减小分类误差率较大的弱分类器的权值,使得它在表决中起较小的作用
-
Adaboost使用的是整个数据 ; Bagging使用的是数据的子集 -
Adaboost特点 : 把多个不同的弱分类算法,用一种非随机的方式组合起来 , 实现性能的提高
- 1.可以使用各种方法构建子分类器,Adaboost算法提供的是框架;
- 2.子分类器容易构造;
- 3.速度快,且基本不用调参数;
- 4.泛化错误率低。
-
Adaboost数学原理实战:
-
首先Adaboost算法是解决二分类问题
-
{-1,+1}两个类别
-
对样本进行初始化权值 ===> 1/N
-
定义了hm(x)模型本身 ---- KNN\DT
-
定义em分类误差率(计算hm(x)在训练数据集上的分类误差率)----sum(w*I(hm(xi)!=yi)) (不相等返回1,相等返回0)
-
注 :

-
定义am学习器的权值(计算hm(x)的相关系数)----am=1/2*log({1-em}/em)
-

-
更新训练数据集的权值分布----w(k+1)=w(k)*exp(-am*yi*hm(x))/zm
-

-
构建基本分类器的线性组合:f(x)=sum(am*hm(x))
-

-
二分类输出(最终分类器):F(x)=sign(f(x))
-

-
错误率的由来
-

-
由于
0em>=1/2是不对的 ; 因为增加减少权重是整体的分配的 , 因此不会出现小于0 -

-
Adaboost的损失函数是指数函数 : 为了方便计算
-

-
17.Adaboost算法实战
- Adaboost算法损失函数—指数损失函数
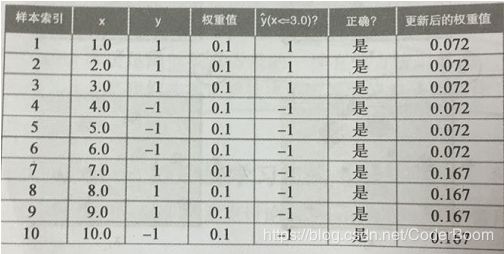
- Adaboost算法案例(掌握)
- 实战图解 :
- 数据2


- Adaboost算法的多分类问题求解-----MVM()
- ovr(one vs rest) ---- 将一个N分类问题转化为n个二分类问题
- ovo(one vs one) ---- 将一个N分类问题转化为n*(n-1)/2个二分类问题
- mvm(many vs many) ---- 将多个N分类问题转化为N个二分类问题
- Adaboost实战
- Adaboost参数信息
- 1.学习器
- 2.学习率
- 3.多少个串行学习器
- Adaboost参数信息
- 分类代码实战
#1.进行数据的读入---导入数据
from sklearn.datasets import load_iris
iris=load_iris()
#2.对数据进行简单的统计分析和图形化的展示
print(iris.keys())#['data', 'target', 'target_names', 'DESCR', 'feature_names']
print("iris data:",iris.data)
print("iris data:",type(iris.data))#iris data: - 回归代码实战
# 读取数据
from sklearn.datasets import load_boston
bostan = load_boston()
print(bostan.keys()) # dict_keys(['data', 'target', 'feature_names', 'DESCR'])
print(bostan.DESCR) #:Number of Instances: 506 -:Number of Attributes: 13 numeric/categorical predictive
print(bostan.data)
print(bostan.target)
print(bostan.feature_names)
# ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
# 'B' 'LSTAT']
# 数据处理
X = bostan.data
y = bostan.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=22, test_size=0.2)
# print(X_train)
# print(y_train)
# 模型建立
from sklearn.ensemble import AdaBoostRegressor
lr = AdaBoostRegressor()
lr.fit(X_train, y_train)
# 模型预测
y_pred = lr.predict(X_test)
print(y_pred)
# 模型校验
print("model in trains set score is:", lr.score(X_train, y_train))
print("model in tests set score is:", lr.score(X_test, y_test))
# model in trains set score is: 0.9024524541824029
# model in tests set score is: 0.8109792865749363
# mae\mse\r2
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print("mae:", mean_absolute_error(y_test, y_pred))
print("mse", mean_squared_error(y_test, y_pred))
# mae: 3.4240698961589606
# mse 20.765767538052017
print("r2", r2_score(y_test, y_pred)) # r2 0.7658020514461032
Adaboost官网 : 分类 和 回归
18.Adaboost实战葡萄酒数据
- 对于数据的处理,需要增加列明子–wine_names取
- 训练模型和前面部分一致的
- 代码实战
import pandas as pd
df_wine=pd.read_csv("wine.data",sep=",")
df_wine.columns=["Class_label","Alcohol","Malic acid","Ash",
"Alcalinity of ash","Magnesium","Total phenols",
"Flavanoids","Nonflavanoid phenols","Proanthocyanins",
"Color intensity","Hue","OD280/OD315 of diluted wines","Proline "]
print(df_wine)
print(df_wine.info())
print(df_wine.shape)
print(df_wine.columns)
# (177, 14)
# Index(['Class_label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash',
# 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols',
# 'Proanthocyanins', 'Color intensity', 'Hue',
# 'OD280/OD315 of diluted wines', 'Proline '],
# dtype='object')
df_wine=df_wine[df_wine["Class_label"]!=1]
X=df_wine[["Alcohol","Hue"]].values
print(type(df_wine[["Alcohol","Hue"]])) #**总结:**AdaBosst预测准确了所有的训练集类标,与单层决策树相比,它在测试机上表现稍微好一些。单决策树对于训练数据过拟合的程度更加严重一些。总之,我们可以发现Adaboost分类器能够些许提高分类器性能,并且与bagging分类器的准确率接近.
19.GBDT算法详解
- GBDT模型
- GBDT(GradientBoostingDescitionTree) , 梯度提升决策树(分类和回归树)。
- 提升树的原理
- 提升方法采用加法模型(即基函数的线性组合)与前向分布算法 , 以决策树为基函数的提升方法称为提升树。 Boosting tree,对分类问题,决策树是二叉决策树;对回归问题,决策树是二叉回归树。
- 加法模型 : 最终的结果依赖于每一个模型
- 前向分布算法 : 通过该算法求解和迭代模型的参数
- GBDT在提升树的原理基础上利用梯度的方法进行最优解参数的求解
- 在提升树的基础上,利用梯度下降法,求解目标函数或者损失函数最优解的情况,就称之为梯度提升算法。
- 提升树原理图解

- 梯度提升树算法,在回归问题中,这称之为梯度提升回归树GBRT,在分类问题中,称之为梯度提升决策树GBDT。
20.GBDT算法改进的XGBoost算法
-
GBDT
- 加法模型
- 前向分布算法
- 梯度提升算法
-
XGBoost
- 泰勒二阶展开
- L1和L2正则 ---- 叶子节点个数和权重
- 不需要对确实数据进行处理
- level-wise
-
LightGBM
- leaf-wise
- 不需要对类别型变量进行处理
-
XGBoost模型选择 : 决策树集合
-
L1正则控制的是叶子节点的个数 ; L2正则控制的是w权重
-
模型的复杂度越高 , 越容易导致方差大 ; 模型越简单 , 越容易导致偏差大
21.XGBoost与传统的GBDT的区别
- 1.分类器的区别
- 传统GBDT以Cart树作为分类器
- XGBoost还支持线性分类器,这个时候XGBoost相当于带有L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)
- 2.优化
- 传统GBDT在优化时只用到一阶导数信息
- xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导
- 3.正则项的控制
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff(偏差-方差 权衡)角度来讲,正则项降低了模型的variance(方差),使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- 4.Shrinkage(缩减)
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 5.列(特征)抽样
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 6.缺失值问题
- 对缺失值的处理,对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- 7.并行
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 8.可并行的近似直方图算法
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
22.扩展 — GBDT&XGBoost&LightGBM
23.集成模型回归分析波斯顿房价实战
- 房价预测—回归问题
- 决策树的预测分析DescitionTree
- 随机森林预测分析RandomForestRegressor
- Bagging算法预测分析:BaggingRegressor
- Adaboost算法预测分析:AdaboostRegressor
- GBDT算法预测分析:GradientBoostingRegressor
#读取数据
from sklearn.datasets import load_boston
bostan=load_boston()
def data_info():
print(bostan.keys()) # dict_keys(['data', 'target', 'feature_names', 'DESCR'])
print(bostan.DESCR) #:Number of Instances: 506 -:Number of Attributes: 13 numeric/categorical predictive
print(bostan.data)
print(bostan.target)
print(bostan.feature_names)
data_info()
# ['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
# 'B' 'LSTAT']
#数据处理
X=bostan.data
y=bostan.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=22,test_size=0.2)
# print(X_train)
# print(y_train)
#模型建立
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import BaggingRegressor
from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score
def method_reg(method):
dtr = DecisionTreeRegressor()
dtr.fit(X_train, y_train)
# 模型预测
y_pred = dtr.predict(X_test)
# print(y_pred)
# 模型校验
print("model in trains set score is:", dtr.score(X_train, y_train))
print("model in tests set score is:", dtr.score(X_test, y_test))
# model in trains set score is: 0.9782530327891484
# model in tests set score is: 0.8442713715157044
# mae\mse\r2
print("mae:", mean_absolute_error(y_test, y_pred))
print("mse", mean_squared_error(y_test, y_pred))
# mae: 3.4240698961589606
# mse 20.765767538052017
print("r2", r2_score(y_test, y_pred)) # r2 0.7658020514461032
print("*"*100)
print("This is GBDT : ")
gbdt = GradientBoostingRegressor()
method_reg(gbdt)
print("*"*100)
print("This is DTR : ")
dtr = DecisionTreeRegressor()
method_reg(dtr)
print("*"*100)
print("This is ADBR : ")
adbr = AdaBoostRegressor()
method_reg(adbr)
print("*"*100)
print("This is RFR : ")
rfr = RandomForestRegressor()
method_reg(rfr)
print("*"*100)
print("This is BR : ")
br = BaggingRegressor()
method_reg(br)
24.集成学习如何保证多样性?
- 数据样本的多样性
- 特征或属性的多样性
- 算法参数的多样性
25.总结
- 集成学习
- 串行---- Boosting框架 ---- Adaboost
- 并行---- Bagging框架 ---- RandomForest
- Stacking组合方式
