图像修复.python实现
下面是我当时在复现这篇论文是时的过程,不想看的可以直接去我的Github上看代码。
https://github.com/CoderAnn/GLCI
有问题可以留言,一定会尽全力解答。
实验过程简介:
首先,我是基于Context Encoders:Feature Learning by Impainting(2016)复现SATOSHI IIZUKA等人在2017年发表的Globally and Locally Consistent Image Completion。2016年的这篇论文我没咋细看,大概是说把上下文编码器的思想和GAN的思想结合去做图像补全,上下文编码器就是先把图像进行编码之后再进行解码,从而学的图像的特征并生成图像待修补区域对应的预测图。GAN用来判别图像是否是虚假的。
现在先复习一下GAN的训练过程:首先对z和x采样一个批次,获得他们的数据分布,然后通过随机梯度下降的方法先对D做k次更新,之后对G做一次更新,这样做的主要目的是保证D一直有足够的能力去分辨真假。实际在代码中我们可能会多更新几次G只更新一次D,不然D学习的太好,会导致训练前期发生梯度消失的问题。
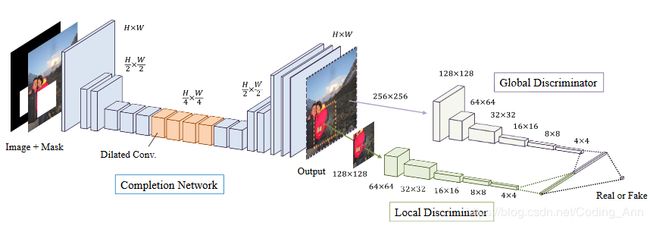
而我要复现的论文其实就是在这篇论文的基础上,修改了鉴别网络,把之前的单个鉴别器扩充到两个鉴别器,一个用来查看全局内容的一致性,另一个用来看局部内容的一致性。最后鉴别器的输出是将二者全连接后再Sigmoid成概率。另外这篇论文还将重构损失修改为MSE+GAN损失,这一点是为了防止GAN的不稳定性。
具体的训练过程是先用MSE损失更新Tc次补全网络,之后再进行Td次鉴别器的更新,最后两个一起更新。先要更新补全网络是因为最开始的时候,补全网络很差,补全的效果非常明显,鉴别器很容易就能看出这是虚假图片,此时鉴别器的损失很小,几乎为0,也就是此时的鉴别器并没有发挥作用。
网络架构如下图所示:
训练过程:

实验经过:
整个的训练过程基本实现:首先读入数据x,之后通过生成随机点来确定mask,将(x*mask)作为补全网络的输入,该输入是缺失部分区域的图片,之后通过降低MSE损失来使补全网络生成图片,待MSE损失降低后,开始训练鉴别器(这里单独训练鉴别器可能是为了让鉴别器明白什么样的图片是真实的,什么样的图片是虚假的??先单独训练生成器的原因是由于最开始补全网络效果很差,如果直接让鉴别器去判断会一眼看出是假的,必须训练到让鉴别器不太清楚真假的时候让两者进行对抗),最后一起训练生成器和鉴别器。但是在具体的数据集当中发现鉴别器的损失非常小,这一点还得继续训练完善。
目前训练出现的问题:鉴别器的损失不下降为定值(学习率:2e-3,数据集:500张人脸图片),下次训练学习率设置为0.5(无效,非学习率问题!)

考虑鉴别器代码本身有误。鉴别器代码确实有误,在全连接之前少了一步reshape。
另外,发现鉴别器最后的输出按理说应该是一个打分,也就是需要用sigmoid激活,但是参考的代码统统没有激活,直接将全连接的输出作为鉴别器的输出。这一点还需查资料。(训练GAN的技巧中说明如果最后一层不用sigmoid会让网络更加稳定)
仔细看过代码后发现,其实最后用的全连接层是将数据全连接成一个数字了,也就是numsout=1,如果最后全连接的输出是一个数字的话,就可以不用sigmoid函数去激活成(0,1)的数字了。重点不是因为这个,而是因为sigmoid会忽视掉负值的含义,容易让梯度消失,所以最后一层用了batch_norm先归一化然后再用leaky_rule去激活。
为什么在全连接之前卷积之后需要对图像进行reshape呢?
因为卷积之后的图像仍是一个矩阵,但是全连接层的输入是一个向量,因此需要一步reshape.
鉴别器是如何判断图像是虚假的呢?
在GAN中,鉴别器是通过构建多层感知机来进行分类的。在Encoder-Decoder当中,鉴别器是通过卷积神经网络进行分类,具体的说是先卷积降低分辨率最后交给全连接层,这里的全连接层充当一个分类器的作用。why???原因还不太明白。。。
目前实验进展:生成器没问题,训练过程应该也没问题,重要的是鉴别器的结构有误,之前没有在全连接之前reshape图像,师兄的代码中最后的全连接层加了一个tf.squeeze(x,-1)函数,这个函数目前我不理解,删除-1维度的所有值为1的维度???为什么要这样呢。。。
目前修改过鉴别器(没有采用师兄的代码,相比之前的代码就是在鉴别器里的全连接层之前加入了reshape,学习率1e-3,数据量500张数据集)后对模型进行训练,发现以下几点变化:
- 最开始的优化mse损失的表现没有之前的稳定(按理来说不应该发生改变)
- 鉴别器中判断为真实图片的损失很小几乎为0,也就是G_LOSS_GAN和D_LOSS几乎相等
- 拿最后的效果对比来看,鉴别器的损失应该对于图像的补全是有效果的
- 最后在迭代8000次的时候鉴别器的损失为0了,从对应的图片来看效果不是非常完美,但是确实有了很大的改进。


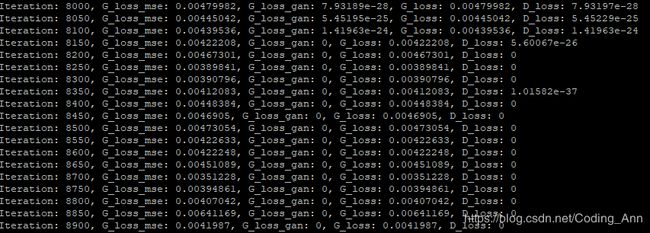
初次修复效果对比图(最开始以为成功了其实并没有Orz...):
 100次
100次
 200次
200次
 2000次
2000次
 3500
3500
 7000
7000
 8500
8500
注:3000次之前是用MSE更新补全网络,3000-3500是单独训练鉴别器
3500-9000鉴别器和补全网络一起训练
下次实验更改的地方:将鉴别器中的全连接层归一化并激活看看会不会有效果。


这次实验看起来损失比之前的能好看一点,但是大佬说这次的模型仍旧是一个失败的模型,虽然图形的训练结果虽然最后看起来还行,但是仅仅只是mse损失降低了所以看起来不错,也就是说鉴别器是没有参与到模型的训练中的???原因:明显看出来g_loss_gan减小时D_loss也会减小,这根本就没有形成对抗,对抗是一个让他变大一个让他变小,因此这确实是一个失败的模型。现在呢继续更改代码,通过阅读别人的代码发现,他们呢的鉴别器和补全网络采取的是不同的卷积函数,同时发现之前的代码G_loss_gan计算错误,而且对于训练过程理解的也不是很对,最后一次训练,是只单独训练G_loss_all并步训练D(师兄不是这么训练的)。因此这次更改了鉴别器中的卷积函数以及激活函数,调用了tf自带的函数来进行操作,并且修改了训练过程,以及修正了g_loss_gan。大佬还说我的代码运行速度太慢,这一点还有待修改。卷积函数的不同对于结果的影响非常微弱,这并不是主要原因。
修正了错误但是鉴别器还是不起作用,按正常道理来说鉴别器应该和生成器产生对抗,也就是优化G_loss_all时D_loss一定会有变化才对,但是目前我优化G_loss_all对于对抗损失无任何影响。。。所以两个没有产生对抗。
之后修改了模型训练中鉴别器数据读取模式(之前是先把图片取出来然后再进行切割即切出蒙版区域),利用tf.image.crop_to_bounding_box(self.inputs[k],y1,x1,64,64)这个函数直接在模型中获取蒙版区域。并且发现之前的优化参数有问题,修改过后发现确实生成器和鉴别器存在对抗,但是!可能是由于参数设置有误或者鉴别器训练太好导致两者的对抗属于力量严重失衡状态,即生成器处于被吊打阶段。。。这可能也是由于初次训练GAN(GAN本身就很不稳定)没啥经验导致的。发现一片好文戳这里鸭!按其中说的优化了GAN,坐等训练结果~!
原始GAN不稳定的原因:判别器训练得太好,生成器梯度消失,生成器loss降不下去;判别器训练得不好,生成器梯度不准,四处乱跑。只有判别器训练得不好不坏才行,但是这个火候又很难把握,甚至在同一轮训练的前后不同阶段这个火候都可能不一样,所以GAN才那么难训练。
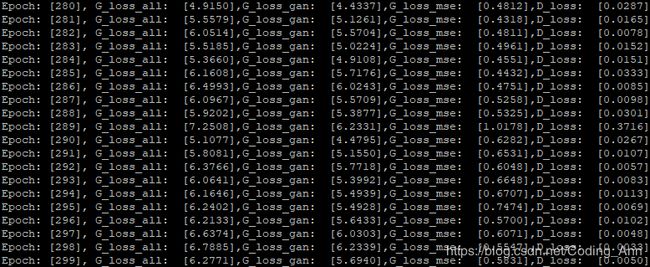
超参数a=1,g_learn=d_learn=0.002:失败!之后还尝试了超参数a=0.05 g_learn=0.001,d_learn=0.0001失败!
正确的损失变化趋势:
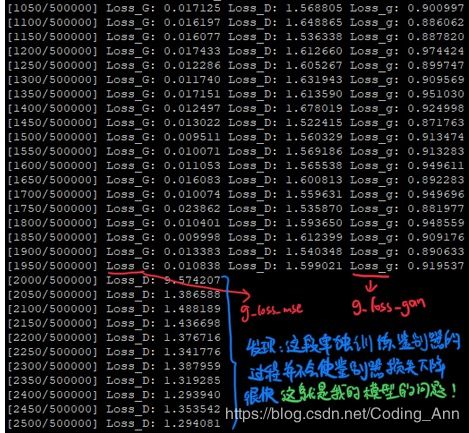
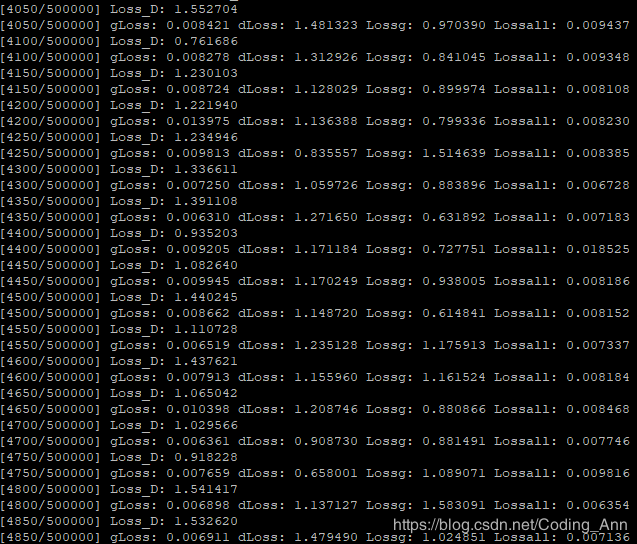
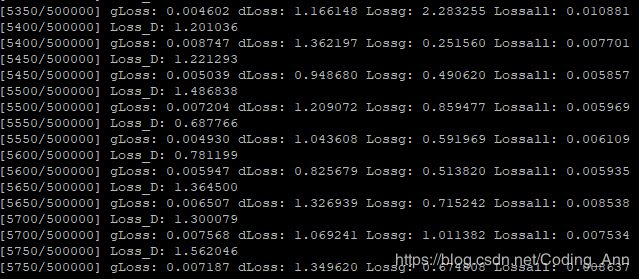
正确的损失变化趋势。发现:我写的鉴别器在最开始的时候下降的就非常快,收敛速度太快???,导致在和生成器对抗时损失以及很低了。
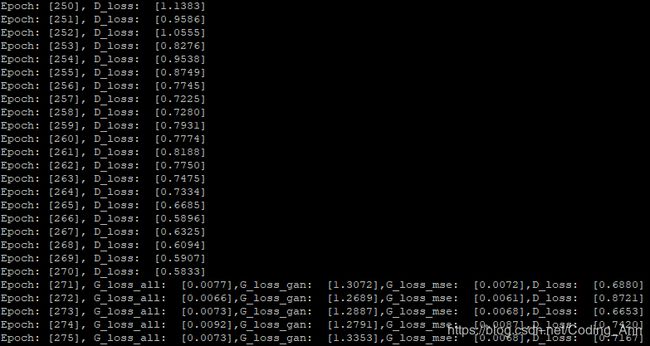
a=0.0004,d_learn=0.0001失败!
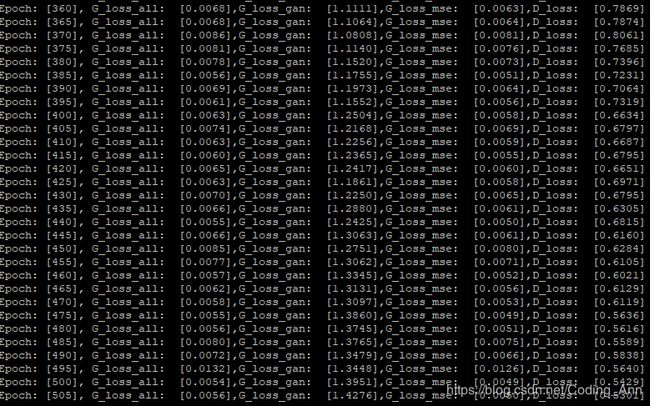
a=0.0004,d_learn=0.00001失败!
a=0.0004,d_learn=0.000001 失败!
但是学习率这么低其实没有毛用,鉴别器还是不行。
经过向师兄请教后发现原来生成器一直都有问题,生成的结果一直都很差导致了鉴别器很快就收敛了,从输入到输出全部替换一边比对之后发现问题出在生成器生成的图像上,下图中左图是正常的生成器经过1000次的生成图像,但是我的就是连眼睛嘴巴都完全糊掉的样子,这里应该就是模型一直以来的问题。
 正确的结果
正确的结果
 我的结果
我的结果
 我的结果
我的结果
之前imitation结果不好的原因应该是训练的次数不到位,训练次数太少了的原因,后来延长训练次数后发现图片除了补全区域很差外其余地方均和目标图像差不太多。所以是同样的网络为什么会导致图片的补全效果差这么多呢??
网络完全一样输入的图片完全一样训练次数完全一样,补全效果千差万别???(修改了数据读取的方式后效果非常好)
将数据的读入方式修改成了队列的方法,并且生成器和鉴别器的卷积操作均使用slim库中的函数,修改后果然生成效果非常好。修复效果如下:
 2000_22000_15000
2000_22000_15000
所以现在有了一个非常大的疑惑,slim库中的卷积函数和tensorflow中的卷积函数有什么不同?队列读取数据的方式和之前的一批次读取队列的方式为什么差这么大?
slim库中的卷积函数和tensorflow中的卷积函数有什么不同?答案请戳这里~!
下一步实验计划:
接下来将会把生成器和鉴别器的网络换成之前的模型,即只控制数据的输入方式为队列形式,看训练的结果如何。
Result:更换之后的结果鉴别器再次不起作用,也许之前写的鉴别器确实有问题。
接下来将把鉴别器更换成师兄的鉴别器网络,观察是否能起作用,如果不行继续就再师兄的鉴别器的基础上更改,打算先把所有的卷积函数替换成tf.nn.conv2d()看有没有变化。
Result:换成师兄的鉴别器后补全效果不错
打算进行一次6000张图片的训练,如果训练效果好就完善一下把保存节点也写好。并且同时在小的训练集上进行测试,修改自己的鉴别器,探寻为什么师兄的鉴别器就可以。
Result:可能因为拿6000张图片去训练时参数没设置好导致训练效果一般。第二个实验把slim.conv2d()换成了tf.nn.conv2d(),发现结果差别不大
准备把归一化函数也进行更换,观察结果。
Results:发现确实是归一化的函数不同导致了结果不对,正确的模型使用的是tf.contrib.slim.batch_norm()函数进行归一化的而把该函数替换成其他的tensorflow中封装的函数则发现不能对抗。But why?
tf.contrib.slim.batch_norm()中的scale和center默认为False,但是slim.batch_norm()中均默认为True,这可能是原因但具体的还得细看。
不过总之也算是找到根本原因了!基本大功告成!!撒花~~~~
实验中函数汇总:
tf.transpose(input, [dimension_1, dimenaion_2,..,dimension_n]):
这个函数主要适用于交换输入张量的不同维度用的,如果输入张量是二维,就相当是转置。dimension_n是整数,如果张量是三维,就是用0,1,2来表示。这个列表里的每个数对应相应的维度。如果是[2,1,0],就把输入张量的第三维度和第一维度交换。
tf.reshape(tensor,shape,name=None):
这个函数是对tensor的shape重新定义为新的shape,如果参数中有-1则表示我们不用亲自去指定这一维的大小,函数会自动进行计算,但是列表中只能存在一个-1。(如果存在多个-1,就是一个存在多解的方程)
tensorflow.squeeze(input, squeeze_dims=None, name=None):
删除input中所有大小是squeeze_dims 的维度。squeeze_dims = None -->默认None是删除input中所有大小是1的维度,若指定位置则删除所指定位置大小是1的维度。此处要注意指定的维度必须确保其是1,否则会报错。
zeros(shape, dtype=float, order='C'):
返回来一个给定形状和类型的用0填充的数组;参数:shape:形状。dtype:数据类型,可选参数,默认numpy.float64
tf.clip_by_value(A, min, max):
输入一个张量A,把A中的每一个元素的值都压缩在min和max之间。小于min的让它等于min,大于max的元素的值等于max
实验中命令汇总:
nvidia-smi:用来查看当前显卡的使用情况
CUDA_VISIBLE_DEVICES=id python XXXX.py: 用id号显卡来运行代码
unzip;ls;cd;cd..;rm;rm-r...: 字面理解就好。
mv:移动文件
disown -h %1 :让程序在后台运行关掉终端也不影响(前提程序已经在后台了(bg %1))
df -h:显示分区的内存占比
dh -sh:显示当前文件夹的大小
dh -sh *:显示当前文件夹下每个文件夹的大小
# ./pso > pso.file 2>&1 & :将程序放入后台执行,关闭终端也依旧执行的命令
ipconfig/all :查看整个电脑的详细的IP配置信息
linux命令戳这里!