Java-Collection集合和Map集合总结
本文欢迎转载,转载前请联系作者,经允许后方可转载。转载后请注明出处,谢谢! http://blog.csdn.net/colton_null 作者:喝酒不骑马 Colton_Null from CSDN
如果一个程序只有包含固定数量的且其生命周期都是已知的对象,那么这是一个非常简单的程序。
一、引言
我们在编程的时候,有时候在程序运行中需要根据当时的情况去创建对象,在此之前可能不知道对象的数量或者确切的类型。例如,我们在根据某些条件去查询数据库后,返回的条数不一定。那么这个时候,就需要用到一个东西(我们暂且称之为容器),用它来装载数量不固定的、类型不固定的对象。
数组的存在,可以解决其中一部分问题。数组是保存一组对象最有效的方式,如果你想保存一组基本数据类型,官方也是推荐使用这个方式去存储数据。但是数据的弊端是,它具有固定的大小。也就是说,在我们编写代码创建数组的时候,必须要给定数据的大小。给定后,这个数据的大小就不能被改变了。所以它麻烦在于我们有时候事先不知道需要存放都少对象(例如前面起到的查库,返回的条数不确定),而且一旦数组大小定小了,数组的存放个数还会受到限制。
于是,Java为我们提供了一套完整且好用的容器,来解决上述问题,我们称之为“集合”。
二、集合简介
集合类存放在java.util包中。主要的类型一共有四种:List(列表)、Set(集)、Queue(队列)、Map(映射)。其中主要有两大接口,分别是Collection和Map。其中List、Set、Queue实现了Collection接口。
偷一张图哈
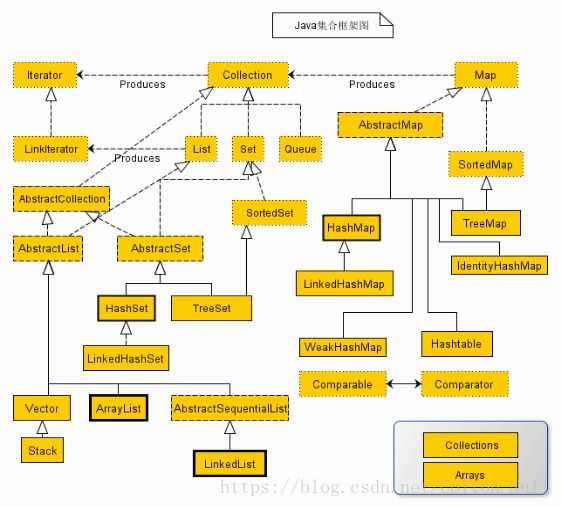
这张图可以说非常经典了。
Tips:实线边框的是实现类,折线边框的是抽象类,而点线边框的是接口。带有空心箭头的点线表示一个特定的类实现了一个接口,实心箭头表示某个类可以生成箭头所指向类的对象。比如,Collection可以生成Iterator。
图中标粗的类(HashSet、ArrayList、LinkedList、HashMap)是比较常用的集合。
那么这些集合(容器)都是干什么用的呢?他们各自又有什么特性呢?
三、集合基本概念
首先在搞清楚常用集合之前,先说说有关集合的基本概念。
前面我们说到,在程序运行过程中,对于不确定数量、不确定类型的对象的存储,我们可以用集合来解决。也就是说,我们可以通过用这些集合,来方便的存储我们想要的对象。当然了,集合对对象的存储,并不是真正把对象塞到容器里来,那是通过什么方式存储对象的呢?这个我们后面再谈。
根据两大集合接口Collection和Map,我们可以把集合也分为两种不同的概念来探讨。
1.Collection。
它是一个序列,可以想象学校里学生们站排这个场景。每个学生就是一个对象,这个排就是一个Collection集合。不同的实现类,对于它所存储的对象的规则要求也不同。List、Queue须按照插入的顺序存储元素,而Set则不能有重复元素。这里简单说一下Queue,它实际上是对队列这种数据结构的一种实现,典型特性就是先进先出(FIFO)。Queue接口提供了offer(Object e)、peek()、poll()等方法对有关队列概念的操作进行实现。
2.Map。
它是一组成对的“键值对”对象,可以通过键来查找值。这就像班级的座位表,任课老师来班级上课,通过座位表上“第三排第五座”就能找到对应的学生“马叨叨”。最神奇的是,我们不光可以用类似“第三排第五座”这样的文字(String)来寻找值,我们也可用通过对象来寻找值。也就是说,Map中的键值都可以是对象。我们称这种对应关系为“映射表”。
四、常用集合总结
1.List
a.ArrayList
它在随机访问元素,即用角标查找数据的时候比较快,但是在元素的插入和删除操作上速度慢一些。
b.LinkedList
而LinkedList在元素插入删除操作上速度较快,但是在随机访问的操作上相对较慢。
对此,我编写了一段程序来测试这个说法。测试思路:分别用插入十万条数据到ArrayList和LinkedList中,以及十万条数据的随机读取,计算每次任务执行的时间差。
public class ListDemo {
// 列表长度定义
private static final int LIST_SIZE = 100000;
public static void main(String[] args) {
List arrayList = new ArrayList(LIST_SIZE);
List linkedList = new LinkedList();
// 测试arraylist增加数据时间
long timestart1 = System.currentTimeMillis();
System.out.println(timestart1 + ":arrayList开始插入数据");
for(int i = 0; i < LIST_SIZE; i++) {
// 每次都将随机数插入到列表的第0位
arrayList.add(0, Math.random());
}
long timeend1 = System.currentTimeMillis();
System.out.println(timeend1 + ":arrayList结束插入数据");
System.out.println("时间差(ms):" + (timeend1 - timestart1) + "\n");
// 测试linkedlist增加数据时间
long timestart2 = System.currentTimeMillis();
System.out.println(timestart2 + ":linkedlist开始插入数据");
for(int i = 0; i < LIST_SIZE; i++) {
// 每次都将随机数插入到列表的第0位
linkedList.add(0, Math.random());
}
long timeend2 = System.currentTimeMillis();
System.out.println(timeend2 + ":linkedlist结束插入数据");
System.out.println("时间差(ms):" + (timeend2 - timestart2) + "\n");
// 测试arrayList读取数据时间
long timestart3 = System.currentTimeMillis();
System.out.println(timestart3 + ":arraylist开始读取数据");
for(int i = 0; i < LIST_SIZE; i++) {
arrayList.get((int) Math.random() * LIST_SIZE);
}
long timeend3 = System.currentTimeMillis();
System.out.println(timeend3 + ":arraylist结束读取数据");
System.out.println("时间差(ms):" + (timeend3 - timestart3) + "\n");
// 测试linkedList读取数据时间
long timestart4 = System.currentTimeMillis();
System.out.println(timestart4 + ":linkedlist开始读取数据");
for(int i = 0; i < LIST_SIZE; i++) {
linkedList.get((int) Math.random() * LIST_SIZE);
}
long timeend4 = System.currentTimeMillis();
System.out.println(timeend4 + ":linkedlist结束读取数据");
System.out.println("时间差(ms):" + (timeend4 - timestart4) + "\n");
}
}最后的测试结果是如下图所示:
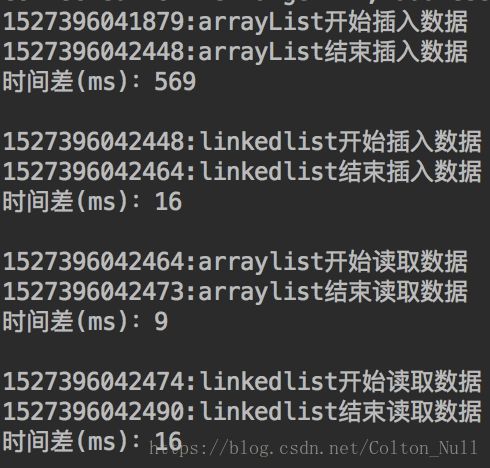
从图中我们可以看出,在元素插入的效率上,LinkedList要远快于ArrayList;在元素随机读取的效率上,ArrayList偏快一些。
那么为什么会这样呢?
实际上,ArrayList是实现了基于动态数组的数据结构,而LinkedList基于链表的数据结构。对于随机访问get和set,ArrayList用数组角标定位元素,而LinkedList则要移动指针才能定位元素。 前者的时间复杂度为O(1),后者为O(n)。
但对于插入和删除操作add和remove,LinkedList就占有一定的优势了,因为ArrayList要移动数据,而LinkedList修改指针指向就ok了。所以前者的增删操作时间复杂度为O(n),后者为O(1)。
所以,我们要根据不同的场景,选择合适的List来完成我们的需要。当我们需要频繁随机读取数据时,首选ArrayList。当我们需要在列表中间频繁插入、移除数据时,首选LinkedList。
另外,LinkedList还添加了可以使其用作栈、队列或双向队列的方法。比如getFirst()、element()、peek()等。这些方法在Java API中都有详细的介绍。
2.Set
Set具有和Collection完全一样的接口,不像List。Set和List最大的区别在于,Set是唯一的、无序的。“唯一的”表示Set不保存重复的原色,“无序的”表示Set中元素的存储是没有顺序的,不过如果真想要保持元素的顺序可以用TreeSet。所以对于Set,最常被使用的简单应用就是测试归属性,即判断某个元素是不是在Set集合里。
对于Set,一般最常使用的就是HashSet,它专门对快速查找操作进行了优化。因为它的底层数据结构为散列表(即哈希表),有关散列的内容,我会在另外一篇文章中详细介绍。
3.Queue
通常情况下,LinkedList可以被用作Queue的一种实现,因为它实现了Queue的接口。不过还有一个类,叫PriorityQueue,它是一个比较标准的队列实现类,但不是绝对标准。因为PriorityQueue保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序。因此当调用peek()、pull()方法来取出队列中的元素时,并不是取出最先进入队列的元素,而是取出队列中最小的元素。这其实违背了先进先出(FIFO)规则。
4.Map
最后,终于到大家都熟悉的Map了。
a.HashMap
HashMap是最为常见的Map了,一般初学者学习的时候都是从HashMap开始,然后有些人就一直使用HashMap不知道其它MapleStory了……HashMap的是根据键的HashCode值来存储数据,根据键可以直接获取它的值,访问速度极快,但数据的存储是无序的。其底层数据结构在Java 1.8后为数组+链表+红黑树(之前是数据+链表,1.8后对结构进行了优化,在链表数量大于8后,用红黑树存储数据,体现就是查询速度更快了,有关这块的内容我也会用单独的篇幅来跟大家一起探讨)。
HashMap允许key和value都为null。
在线程安全方面,HashMap是线程不安全的。如果需要线程安全的Map,可以使用ConcurrentHashMap。
b.LinkedHashMap
LinkedHashMap保存了元素插入Map时的顺序。通常情况下,LinkedHashMap的遍历要慢于HashMap。当然也有特殊情况,比如在HashMap容量巨大但是存储数据较少的时候,遍历会慢于LinkedHashMap。因为LinkedHashMap遍历只和数据数量有关,与容量无关;而HashMap的遍历和它的容量有关。
c.TreeMap
TreeMap实现了SortMap接口,所以它可以根据键进行排序。它默认的排序规则是升序排序,当然开发者也可以指定排序比较器,修改排序规则。
有人可能会提到HashTable。HashTable与HashMap类似,不过它现在已经过时了,变成了遗留类而已。要说它的区别就是,它不允许key和value为null。另外它是个线程安全的Map。不过现在如果想要HashMap线程安全的话,建议使用ConcurrentHashMap。因为HashTable已经被淘汰了,当数据增加到一定程度的时候,效率太低。
—————手动分割线—————
最后说一下前面丢出的一个问题。之前我们提到,集合对对象的存储,并不是把对象塞到容器中,那它是通过什么方式存储对象呢?实际上,集合中存放的是对象的引用,学过C语言同学可能会更好理解,这个引用可以理解为就是记录对象存放地址的指针。根据引用,我们就能找到对象在内存中的存放位置,从而获得对象。而并非在内存中把对象实际装载到某个容器中。
五、总结
- Map保存的是相关联的键值对,而Collection保存的是单一的元素。
- List和数组的区别在于,List能够自动扩充容量。
- 对于Collection集合,需要唯一性我们要想到Set,根据排序与否选择TreeSet和HashSet。如果不需要唯一性则要想要List,如果查询多则使用ArrayList,增删多聚选择LinkedList。
- 对于Queue、Stack等数据结构的实现,用LinkedList即可。
- 对于Map集合。一般使用HashMap,如果需要排序则使用TreeMap,如果需要保持元素插入顺序则使用LinkedHashMap,如果需要线程安全的Map则使用ConcurrentHashMap。
- 过时的类就不要使用了,比如HashTable、Vector、Stack等。
站在前人的肩膀上前行,感谢以下博客及文献的支持。
Java中ArrayList和LinkedList区别 时间复杂度 与空间复杂度
java集合之Set与List总结
Java中的集合Queue、LinkedList、PriorityQueue(四)
《Java编程思想(第四版) 机械工业出版社》