文章目录
- pandas 读写文件
- pandas读取文件
- read_csv/read_table参数
- 导入
- 基本导入 read_csv
- 数据库导入
- 分隔符 sep
- 没有列名 header
- 自定义列名 name
- 某列设为索引 index_col
- 部分读取 nrows chunksize
- 导出
- 导出 to_csv
- 导出 to_json (read_json)
pandas 读写文件
pandas读取文件
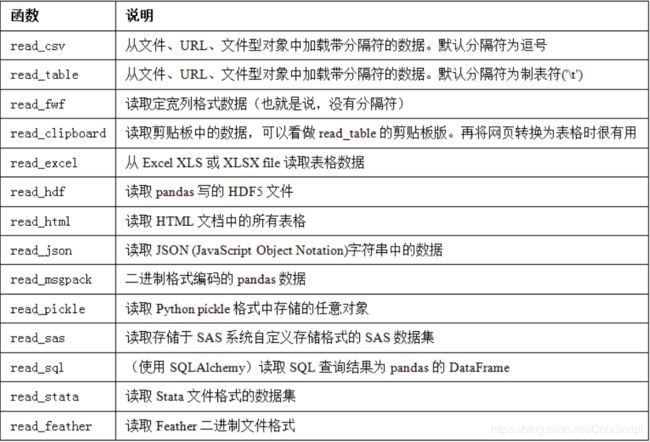
read_csv/read_table参数


导入
基本导入 read_csv
print(pd.read_csv('test.csv'))
print(pd.read_table('test.csv', sep=','))
数据库导入
# import sqlalchemy
# db = sqlalchemy.create_engine('sqlite:///mydata.sqlite')
# db = sqlalchemy.create_engine('mysql+pymysql://root:xxxxx@localhost/xxxx')
# pd.read_sql('select * from test', db)
分隔符 sep
# 正则分隔符
pd.read_table('examples/ex3.txt', sep='\s+')
没有列名 header
print(pd.read_csv('test_no_head.csv', header=None))
自定义列名 name
names = ['name', 'p_id', 'id', 'level']
print(pd.read_csv('tt.csv', names=names))
某列设为索引 index_col
print(pd.read_csv('tt.csv', names=names, index_col='id'))
层次化索引
print(pd.read_csv('tt.csv', names=names, index_col=['p_id', 'id']))
部分读取 nrows chunksize
# 只读取8行*
print(pd.read_csv(filename, nrows=8, header=None))*
# 逐块读取
pd.read_csv(filename, chunksize=100)
导出
导出 to_csv
# 导出数据
dd = pd.read_csv(filename, nrows=8, names=['name', 'pid', 'id', 'level'])
dd.index.name = 'id'
dd.to_csv('out.csv')
# 自定义导出的列
dd1.to_csv(sys.stdout, index=False, columns=['name', 'id'])
导出 to_json (read_json)
import json
res = json.loads(obj)
print(type(res), res)
res_json = json.dumps(res)
print(type(res_json), res_json)
data = pd.read_json('examples/example.json')
data.to_json('xxx.json')