Machine_Learning_2019_SVM: An Introduction
浅谈 SVM 之分类(Classification)、回归(Regression)与排序(Ranking)问题
0 介绍
支持向量机(SVMs)在数据挖掘和机器学习领域得到了广泛的研究与应用,其通常用于学习分类、回归或排序函数,它们分别被称为分类(SVM)、支持向量回归(SVR)或排序支持向量机(RankSVM)。支持向量机的两个特性是:
- 通过margin maximization(间隔最大化)以提高其泛化能力;
- 通过kernel trick(核技巧)以支持非线性函数的有效学习。
SVM(Support Vector Machine, SVM)是一种二类分类模型。它的基本模型是定义在特征空间上的线性分类器,间隔最大使其有别于感知机;支持向量机还包括核技巧,这是其成为实质上的非线性分类器,其学习策略即间隔最大化。
SVM本身是一种线性分类和非线性分类都支持的二元分类算法,经过其演变之后,现在也支持Multi-class classification(多分类问题`),Regression(回归问题),同样也能应用到了Ranking(排序问题)。本文主要对Classification,Regression和Ranking三类问题进行综述,并对其基本原理和推导过程做简要说明。
1 SVM Classification
支持向量机(SVMs)最初是为[分类][1]而开发的,并已扩展到[回归][2]和[偏好(或排名)学习][3]。支持向量机的初始形式是二元分类器,其中学习函数的输出为正或负。采用pairwise coupling(成对耦合)的方法,将多个二元分类器组合在一起,可以实现[多分类问题][4]。作为二元分类器,SVM的两个关键特性,即margin maximization(间隔最大化)与kernel trick(核技巧)。
二元支持向量机是区分两类数据点的分类器。每个数据对象(或数据点)都由一个n维向量表示。这些数据点都只属于两个类中的一个。一个线性分类器用一个超平面来分离数据点。为了在这两个类之间实现最大程度的分离,SVM选取的超平面的largest margin(间隔最大)。margin(间隔)是两个类别的分离超平面到最近数据点的最短距离之和。这样的超平面具有更好的泛化能力,即超平面可以正确地对“未知”或测试数据点进行分类。
支持向量机将输入空间映射到特征空间,以支持非线性分类问题。kernel trick(核技巧)有助于解决这一问题,由于缺乏精确的映射函数表达式,可能会导致the curse of dimensionality(维数灾难)的问题。这使得新空间(或特征空间)中的线性分类等价于原空间(或输入空间)中的非线性分类。支持向量机通过将输入向量映射到高维空间来实现这些功能,以便构造最大分离超平面的特征空间。
1.1 SVM 硬间隔分类
在讲解SVM 硬间隔分类之前,首先需要介绍一下数据集的线性可分性、感知机模型,以便更好地理解线性支持向量机。
数据集的线性可分性
给定一个数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\} T={(x1,y1),(x2,y2),⋯,(xN,yN)}
其中,
x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N x_{i} \in \mathcal{X}=\mathbf{R}^{n}, \quad y_{i} \in \mathcal{Y}=\{+1,-1\}, \quad i=1,2, \cdots, N xi∈X=Rn,yi∈Y={+1,−1},i=1,2,⋯,N
如果存在某个超平面S
w ⋅ x + b = 0 w \cdot x+b=0 w⋅x+b=0
能够将数据集的正实例点和负实例点完全正确地划分到超平面的两侧,即对所有正实例i,有
w ⋅ x + b > 0 , w \cdot x+b>0, w⋅x+b>0,
对所有的负实例i,有
w ⋅ x + b < 0 , w \cdot x+b<0, w⋅x+b<0,
则称数据集T为线性可分数据集;否则,称数据集T线性不可分。
感知机模型
假设输入空间(特征空间)为:
X ⊆ R n \mathcal{X} \subseteq \mathbf{R}^{n} X⊆Rn
输出空间为:
Y = { + 1 , − 1 } \mathcal{Y}=\{+1,-1\} Y={+1,−1}
输入实例的特征向量对应于输入空间(特征空间)的点,其形式为:
x ∈ X x \in \mathcal{X} x∈X
输出实例的类别为:
y ∈ Y y \in \mathcal{Y} y∈Y
由输入空间到输出空间的函数表示为:
f ( x ) = sign ( w ⋅ x + b ) f(x)=\operatorname{sign}(w \cdot x+b) f(x)=sign(w⋅x+b)
该函数成为感知机,其中w和b为感知机模型参数。
权值或权值向量表示为:
w ∈ R n w \in \mathbf{R}^{n} w∈Rn
偏置表示为:
b ∈ R b \in \mathbf{R} b∈R
w和b的内积表示为:
w ⋅ x w \cdot x w⋅x
sign表示为符号函数,即:
sign ( x ) = { + 1 , x ⩾ 0 − 1 , x < 0 \operatorname{sign}(x)=\left\{\begin{array}{ll}{+1,} & {x \geqslant 0} \\ {-1,} & {x<0}\end{array}\right. sign(x)={+1,−1,x⩾0x<0
感知机学习策略
假设训练数据集是线性可分的,感知机学习的目标是求得一个能够将训练集正实例点和负实例点完全正确分开的分离超平面。为了找到这样的超平面,即确定感知机模型的参数w和b,主要确定一个学习策略,即定义损失函数并将损失函数最小化。
损失函数如何获取?
(1) 误分类点的总数;
(2) 误分类点到超平面的距离。
给定训练数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\} T={(x1,y1),(x2,y2),⋯,(xN,yN)}
其中,
x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N . x_{i} \in \mathcal{X}=\mathbf{R}^{n}, \quad y_{i} \in \mathcal{Y}=\{+1,-1\}, \quad i=1,2, \cdots, N. xi∈X=Rn,yi∈Y={+1,−1},i=1,2,⋯,N.
感知机学习的损失函数定义为:
L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) L(w, b)=-\sum_{x_{i} \in M} y_{i}\left(w \cdot x_{i}+b\right) L(w,b)=−xi∈M∑yi(w⋅xi+b)
其中M为误分类点的集合,该损失函数即感知机学习的经验风险函数。
求损失函数极小化的解对应的参数w和b,形式为:
min w , b L ( w , b ) = − ∑ x i ∈ M y i ( w ⋅ x i + b ) \min _{w, b} L(w, b)=-\sum_{x_{i} \in M} y_{i}\left(w \cdot x_{i}+b\right) w,bminL(w,b)=−xi∈M∑yi(w⋅xi+b)
假设误分类点集合M是固定的,则损失函数的梯度由
∇ w L ( w , b ) = − ∑ x i ∈ M y i x i ∇ b L ( w , b ) = − ∑ x i ∈ M y i \begin{aligned} \nabla_{w} L(w, b)=&-\sum_{x_{i} \in M} y_{i} x_{i} \\ \nabla_{b} L(w, b) &=-\sum_{x_{i} \in M} y_{i} \end{aligned} ∇wL(w,b)=∇bL(w,b)−xi∈M∑yixi=−xi∈M∑yi
给出。
随机选取一个误分类点,表示为:
( x i , y i ) \left(x_{i}, y_{i}\right) (xi,yi)
同时对w和b进行更新:
w ← w + η y i x i b ← b + η y i \begin{array}{c}{w \leftarrow w+\eta y_{i} x_{i}} \\ {b \leftarrow b+\eta y_{i}}\end{array} w←w+ηyixib←b+ηyi
式中的步长为:
η ( 0 < η ⩽ 1 ) \eta(0<\eta \leqslant 1) η(0<η⩽1)
在机器学习中步长又被称为学习率。
训练数据线性可分——硬间隔最大化
在说明硬间隔最大化之前,需要先介绍函数间隔与几何间隔。
函数间隔
对于给定的训练数据集T和超平面(w, b),定义超平面(w, b)关于样本点
( x i , y i ) \left(x_{i}, y_{i}\right) (xi,yi)
的函数间隔为:
γ ^ i = y i ( w ⋅ x i + b ) \hat{\gamma}_{i}=y_{i}\left(w \cdot x_{i}+b\right) γ^i=yi(w⋅xi+b)
定义超平面(w, b) 关于训练数据集T 的函数间隔为超平面(w, b)关于T中所有样本点
( x i , y i ) \left(x_{i}, y_{i}\right) (xi,yi)
的函数间隔之最小值,即
γ ^ = min i = 1 , ⋯ , N γ ^ i \hat{\gamma}=\min _{i=1, \cdots, N} \hat{\gamma}_{i} γ^=i=1,⋯,Nminγ^i
几何间隔
对于给定的训练数据集T和超平面(w, b),定义超平面(w, b)关于样本点
( x i , y i ) \left(x_{i}, y_{i}\right) (xi,yi)
的几何间隔为:
γ i = y i ( w ∥ w ∥ ⋅ x i + b ∥ w ∥ ) \gamma_{i}=y_{i}\left(\frac{w}{\|w\|} \cdot x_{i}+\frac{b}{\|w\|}\right) γi=yi(∥w∥w⋅xi+∥w∥b)
定义超平面(w, b) 关于训练数据集T 的几何间隔为超平面(w, b)关于T中所有样本点
( x i , y i ) \left(x_{i}, y_{i}\right) (xi,yi)
的几何间隔之最小值,即:
γ = min i = 1 , ⋯ , N γ i \gamma=\min _{i=1, \cdots, N} \gamma_{i} γ=i=1,⋯,Nminγi
硬间隔最大化
支持向量机学习的基本思想:
即求解能够正确划分训练数据集并且几何间隔最大的分离超平面。对线性可分的训练数据集而言,线性可分分离超平面有无穷多个,但几何间隔最大的分离超平面是唯一的,该间隔最大化又称为硬间隔最大化。
间隔最大化的直观解释:
对训练数据集找到几何间隔最大的超平面即以充分大的确信度对训练数据进行分类。换言之,不仅将正负实例点分开,而且对最难分的实例点(离超平面最近的点)也有足够大的确信度将它们分开。这样的超平面应该对未知的新实例有很好地分类预测能力。
最大间隔分离超平面的存在唯一性
若训练数据集T线性可分,则可将训练数据集中的样本点完全正确分开的最大间隔分离超平面存在且唯一。
线性SVM学习的最优化问题
min w , b 1 2 ∥ w ∥ 2 s.t. y i ( w ⋅ x i + b ) − 1 ⩾ 0 , i = 1 , 2 , ⋯ , N \begin{array}{cl}{\min _{w, b}} & {\frac{1}{2}\|w\|^{2}} \\ {\text { s.t. }} & {y_{i}\left(w \cdot x_{i}+b\right)-1 \geqslant 0, \quad i=1,2, \cdots, N}\end{array} minw,b s.t. 21∥w∥2yi(w⋅xi+b)−1⩾0,i=1,2,⋯,N
这是一个凸二次优化问题——目标函数是二次的,约束条件是线性的,可以用现有的 QP (Quadratic Programming) 进行优化求解。一般来说,通过 Lagrange Duality 变换到对偶变量 (Dual Variable) 的优化问题之后,可以找到一种更加有效的方法来进行求解,而且通常情况下这种方法比直接使用通用的 QP 优化求解更加高效。
支持向量
在线性可分情况下,训练数据集的样本点中与分离超平面距离最近的样本点的实例称为支持向量,支持向量是使
等号成立的点,即
y i ( w ⋅ x i + b ) − 1 = 0 y_{i}\left(w \cdot x_{i}+b\right)-1=0 yi(w⋅xi+b)−1=0
间隔、间隔边界
在决定分离超平面时只有支持向量起作用,而其他实例点并不起作用。如果移动支持向量将改变所求的解;但是如果在边界以外移动其他实例点,或者去掉这些点,则解是不会改变的。由于支持向量在确定分离超平面中起决定性作用,所以讲这种分类模型称为支持向量机。支持向量的个数一般很少,因此支持向量机由很少的“重要点”训练样本确定。
x i ∈ X = R n , y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N . x_{i} \in \mathcal{X}=\mathbf{R}^{n}, \quad y_{i} \in \mathcal{Y}=\{+1,-1\}, \quad i=1,2, \cdots, N. xi∈X=Rn,yi∈Y={+1,−1},i=1,2,⋯,N.
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x m , y m ) } ( 1 ) D=\left\{\left(\mathbf{x}_{1}, y_{1}\right),\left(\mathbf{x}_{2}, y_{2}\right), \ldots,\left(\mathbf{x}_{m}, y_{m}\right)\right\} (1) D={(x1,y1),(x2,y2),…,(xm,ym)}(1)
F ( x ) = w ⋅ x − b . ( 2 ) F(\mathbf{x})=\mathbf{w} \cdot \mathbf{x}-b.(2) F(x)=w⋅x−b.(2)
y i ( w ⋅ x i − b ) > 0 , ∀ ( x i , y i ) ∈ D ( 3 ) y_{i}\left(\mathbf{w} \cdot \mathbf{x}_{i}-b\right)>0, \forall\left(\mathbf{x}_{i}, y_{i}\right) \in D(3) yi(w⋅xi−b)>0,∀(xi,yi)∈D(3)
y i ( w ⋅ x i − b ) ≥ 1 , ∀ ( x i , y i ) ∈ D ( 4 ) y_{i}\left(\mathbf{w} \cdot \mathbf{x}_{i}-b\right) \geq 1, \forall\left(\mathbf{x}_{i}, y_{i}\right) \in D(4) yi(w⋅xi−b)≥1,∀(xi,yi)∈D(4)
margin = 1 ∥ w ∥ ( 5 ) \operatorname{margin}=\frac{1}{\|\mathbf{w}\|}(5) margin=∥w∥1(5)
minimize: Q ( w ) = 1 2 ∥ w ∥ 2 ( 6 ) subject to: y i ( w ⋅ x i − b ) ≥ 1 , ∀ ( x i , y i ) ∈ D ( 7 ) \begin{array}{l}{\text { minimize: } Q(\mathbf{w})=\frac{1}{2}\|\mathbf{w}\|^{2}}(6) \\ {\text { subject to: } y_{i}\left(\mathbf{w} \cdot \mathbf{x}_{i}-b\right) \geq 1, \forall\left(\mathbf{x}_{i}, y_{i}\right) \in D(7)}\end{array} minimize: Q(w)=21∥w∥2(6) subject to: yi(w⋅xi−b)≥1,∀(xi,yi)∈D(7)
1.2 SVM 软间隔分类
训练数据集近似线性可分——软间隔最大化
对于线性可分问题,线性可分支持向量机的学习(硬间隔最大化)算法是完美的。但是,训练数据集线性可分是理想情形。在现实问题中,训练数据集往往是线性不可分的,即在样本中出现噪声或特异点。此时,需有更为一般的学习算法。
假设给定一个特征空间上的训练数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\} T={(x1,y1),(x2,y2),⋯,(xN,yN)}
其中,
第i个特征向量为:
x i ∈ X = R n , x_{i} \in \mathcal{X}=\mathbf{R}^{n}, xi∈X=Rn,
其对应的类标记为:
y i ∈ Y = { + 1 , − 1 } , i = 1 , 2 , ⋯ , N , y_{i} \in \mathcal{Y}=\{+1,-1\}, \quad i=1,2, \cdots, N, yi∈Y={+1,−1},i=1,2,⋯,N,
若假设训练数据集不是线性可分的,通常情况是,训练数据集中存在一些特异点(Outlier),将这些特异点除去后,剩下大部分的样本点组成的集合是线性可分的。因此,可以模仿训练数据集线性可分的情况,来考虑训练数据集线性不可分时的线性支持向量机的学习问题,对应于硬间隔最大化,其称为软间隔最大化。
线性不可分的线性支持向量机的学习问题可以转换为凸二次规划 (Convex Quadratic Programming)问题:
min w , b , ξ 1 2 ∥ w ∥ 2 + C ∑ i = 1 N ξ i ( 1.2.1 ) \min _{w, b, \xi} \frac{1}{2}\|w\|^{2}+C \sum_{i=1}^{N} \xi_{i}(1.2.1) w,b,ξmin21∥w∥2+Ci=1∑Nξi(1.2.1)
s t . y i ( w ⋅ x i + b ) ⩾ 1 − ξ i , i = 1 , 2 , ⋯ , N ( 1.2.2 ) st.\quad y_{i}\left(w \cdot x_{i}+b\right) \geqslant 1-\xi_{i}, \quad i=1,2, \cdots, N(1.2.2) st.yi(w⋅xi+b)⩾1−ξi,i=1,2,⋯,N(1.2.2)
ξ i ⩾ 0 , i = 1 , 2 , ⋯ , N ( 1.2.3 ) \xi_{i} \geqslant 0, \quad i=1,2, \cdots, N(1.2.3) ξi⩾0,i=1,2,⋯,N(1.2.3)
线性支持向量机
对于给定的线性不可分的训练数据集,通过求解凸二次规划问题,即软间隔最大化问题 (1.2.1) ~ (1.2.3),得到的分离超平面为:
w ∗ ⋅ x + b ∗ = 0 w^{*} \cdot x+b^{*}=0 w∗⋅x+b∗=0
以及相应的分类决策函数:
f ( x ) = sign ( w ∗ ⋅ x + b ∗ ) f(x)=\operatorname{sign}\left(w^{*} \cdot x+b^{*}\right) f(x)=sign(w∗⋅x+b∗)
称为线性支持向量机。
原始问题 (1.2.1) ~ (1.2.3) 的对偶问题是:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i ( 1.2.4 ) \min _{\alpha} \frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i} \cdot x_{j}\right)-\sum_{i=1}^{N} \alpha_{i}(1.2.4) αmin21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi(1.2.4)
s t . ∑ i = 1 N α i y i = 0 ( 1.2.5 ) st.\quad \sum_{i=1}^{N} \alpha_{i} y_{i}=0(1.2.5) st.i=1∑Nαiyi=0(1.2.5)
0 ⩽ α i ⩽ C , i = 1 , 2 , ⋯ , N ( 1.2.6 ) 0 \leqslant \alpha_{i} \leqslant C, \quad i=1,2, \cdots, N(1.2.6) 0⩽αi⩽C,i=1,2,⋯,N(1.2.6)
可以通过求解对偶问题而得到原始问题的解,进而确定分离超平面与决策函数:
max a ∑ i = 1 N a i − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i T ⋅ x j ) ( 1.2.7 ) \max _{a} \sum_{i=1}^{N} a_{i}-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j}\left(x_{i}^{T} \cdot x_{j}\right)(1.2.7) amaxi=1∑Nai−21i=1∑Nj=1∑Nαiαjyiyj(xiT⋅xj)(1.2.7)
s t . ∑ i = 1 N α i y i = 0 st.\quad \sum_{i=1}^{N} \alpha_{i} y_{i}=0 st.i=1∑Nαiyi=0
0 ⩽ α i ⩽ C , i = 1 , 2 , ⋯ , N 0 \leqslant \alpha_{i} \leqslant C, \quad i=1,2, \cdots, N 0⩽αi⩽C,i=1,2,⋯,N
根据对偶问题的解,我们可以进一步得到原始问题的解。其对应的分离超平面可以写成:
∑ i = 1 N α i ∗ y i ( x ⋅ x i ) + b ∗ = 0 \sum_{i=1}^{N} \alpha_{i}^{*} y_{i}\left(x \cdot x_{i}\right)+b^{*}=0 i=1∑Nαi∗yi(x⋅xi)+b∗=0
分类决策函数可以写成:
f ( x ) = sign ( ∑ i = 1 N α i ∗ y i ( x ⋅ x i ) + b ∗ ) f(x)=\operatorname{sign}\left(\sum_{i=1}^{N} \alpha_{i}^{*} y_{i}\left(x \cdot x_{i}\right)+b^{*}\right) f(x)=sign(i=1∑Nαi∗yi(x⋅xi)+b∗)
软间隔的支持向量
软间隔的支持向量:
x i x_{i} xi
或者在间隔边界上,或者在间隔边界与分离超平面之间,或者在分离超平面误分的一侧。
minimize: Q 1 ( w , b , ξ i ) = 1 2 ∥ w ∥ 2 + C ∑ i ξ i ( 23 ) subject to: y i ( w ⋅ x i − b ) ≥ 1 − ξ i , ∀ ( x i , y i ) ∈ D ( 24 ) ξ i ≥ 0 ( 25 ) \begin{array}{c}{\text { minimize: } Q_{1}\left(w, b, \xi_{i}\right)=\frac{1}{2}\|\mathbf{w}\|^{2}+C \sum_{i} \xi_{i}}(23) \\ {\text { subject to: } \quad y_{i}\left(\mathbf{w} \cdot \mathbf{x}_{i}-b\right) \geq 1-\xi_{i}, \quad \forall\left(\mathbf{x}_{i}, y_{i}\right) \in D}(24) \\ {\xi_{i} \geq 0}(25)\end{array} minimize: Q1(w,b,ξi)=21∥w∥2+C∑iξi(23) subject to: yi(w⋅xi−b)≥1−ξi,∀(xi,yi)∈D(24)ξi≥0(25)
1.3 核技巧的非线性分类
训练数据不可分——核技巧+软间隔最大化
如果训练数据不是线性可分的,那么就不存在一个超平面将类别分开。在这种情况下,为了学习非线性函数,必须将线性支持向量机推广到非线性支持向量机来解决非线性可分数据的分类问题。利用非线性支持向量机寻找分类函数的过程包括两个步骤。首先,将输入向量转化为高维特征向量,并对训练数据进行线性分离。然后,利用支持向量机在新的特征空间中寻找最大间隔的超平面。分离超平面在变换后的特征空间中成为一个线性函数,在原输入空间中成为一个非线性函数。
设x为n维输入空间向量,输入空间到高维特征空间的非线性映射函数为
φ ( ⋅ ) \varphi(\cdot) φ(⋅)
特征空间中表示决策边界的超平面定义如下:
w ⋅ φ ( x ) − b = 0 \mathbf{w} \cdot \varphi(\mathbf{x})-b=0 w⋅φ(x)−b=0
其中,w表示能够将高维特征空间中的训练数据映射到输出空间的权重向量,b表示偏差,结合映射函数,权重向量表示为:
w = ∑ α i y i φ ( x i ) \mathbf{w}=\sum \alpha_{i} y_{i} \varphi\left(\mathbf{x}_{i}\right) w=∑αiyiφ(xi)
决策函数表示为:
F ( x ) = ∑ i α i y i K ( x i , x ) − b F(\mathbf{x})=\sum_{i} \alpha_{i} y_{i} K\left(\mathbf{x}_{i}, \mathbf{x}\right)-b F(x)=i∑αiyiK(xi,x)−b
利用数据向量上的映射函数,重写soft-margin SVM 的对偶形式:
Q ( α ) = ∑ i α i − 1 2 ∑ i ∑ j α i α j y i y j φ ( x i ) ⋅ φ ( x j ) Q(\alpha)=\sum_{i} \alpha_{i}-\frac{1}{2} \sum_{i} \sum_{j} \alpha_{i} \alpha_{j} y_{i} y_{j} \varphi\left(\mathbf{x}_{i}\right) \cdot \varphi\left(\mathbf{x}_{j}\right) Q(α)=i∑αi−21i∑j∑αiαjyiyjφ(xi)⋅φ(xj)
在优化问题和分类函数中,特征映射函数常常以点积的形式出现,在变换后的特征空间中计算内积显得十分复杂,并受到维数问题的困扰。为了避免这个问题,使用了核技巧。核技巧将特征空间中的内积替换为原始输入空间中的内核函数K,形式表达如下:
K ( u , v ) = φ ( u ) ⋅ φ ( v ) K(\mathbf{u}, \mathbf{v})=\varphi(\mathbf{u}) \cdot \varphi(\mathbf{v}) K(u,v)=φ(u)⋅φ(v)
Mercer定理可以确保核函数的有效性:
∫ K ( u , v ) ψ ( u ) ψ ( v ) d x d y ≤ 0 where ∫ ψ ( x ) 2 d x ≤ 0 \begin{array}{l}{\int K(\mathbf{u}, \mathbf{v}) \psi(\mathbf{u}) \psi(\mathbf{v}) d x d y \leq 0} \\ {\text { where } \int \psi(x)^{2} d \mathbf{x} \leq 0}\end{array} ∫K(u,v)ψ(u)ψ(v)dxdy≤0 where ∫ψ(x)2dx≤0
在某些高维空间中,核函数始终可以表示为输入向量对之间的内积,因此可以使用核函数计算内积,其仅对原始空间中的输入向量使用核函数,而不将输入向量转化为高维特征向量。
对偶问题使用核函数定义如下所示:
Q 2 ( α ) = ∑ i α i − ∑ i ∑ j α i α j y i y j K ( x i , x j ) Q_{2}(\alpha)=\sum_{i} \alpha_{i}-\sum_{i} \sum_{j} \alpha_{i} \alpha_{j} y_{i} y_{j} K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) Q2(α)=i∑αi−i∑j∑αiαjyiyjK(xi,xj)
s . t . ∑ i α i y i = 0 C ≥ α ≥ 0 s.t. \begin{array}{l}{\sum_{i} \alpha_{i} y_{i}=0} \\ {C \geq \alpha \geq 0}\end{array} s.t.∑iαiyi=0C≥α≥0
分类函数表示为:
F ( x ) = ∑ i α i y i K ( x i , x ) − b F(\mathbf{x})=\sum_{i} \alpha_{i} y_{i} K\left(\mathbf{x}_{i}, \mathbf{x}\right)-b F(x)=i∑αiyiK(xi,x)−b
由于K(·)是在输入空间中计算的,所以实际上不会进行特征变换,也不会计算映射函数,因此在非线性支持向量机中也不会计算权重向量w。
常用的核函数多元核函数、径向基函数、Sigmoid核函数等,形式如下:
∙ Polynomial: K ( a , b ) = ( a ⋅ b + 1 ) d ∙ Radial Basis Function ( R B F ) : K ( a , b ) = ∣ exp ( − γ ∥ a − b ∥ 2 ) ∙ sigmoid: K ( a , b ) = tanh ( κ a ⋅ b + c ) ∣ \begin{array}{l}{\bullet \text { Polynomial: } K(a, b)=(a \cdot b+1)^{d}} \\ {\bullet \text { Radial Basis Function }(\mathrm{RBF}) : K(a, b)=| \exp \left(-\gamma\|a-b\|^{2}\right)} \\ {\bullet \text { sigmoid: } K(a, b)=\tanh (\kappa a \cdot b+c) |}\end{array} ∙ Polynomial: K(a,b)=(a⋅b+1)d∙ Radial Basis Function (RBF):K(a,b)=∣exp(−γ∥a−b∥2)∙ sigmoid: K(a,b)=tanh(κa⋅b+c)∣
核函数可以理解为两个向量之间的一种相似函数,即当两个向量等价时,函数输出最大化。正因为如此,只要我们能计算任意对数据对象之间的相似性函数,SVM即可从向量以外的任何shape(比如树和图模型)的数据中学习一个函数。
2 SVM Regression
支持向量机回归(SVM Regression, SVR)是一种基于训练数据估计从输入对象映射到实数函数的方法。与分类SVM相似,对于非线性映射,SVR具有间隔最大化和核技巧相同的性质。
F ( x ) ⟹ ∑ i ( α ^ i − α i ) K ( x i , x ) + b F(\mathbf{x}) \Longrightarrow \sum_{i}\left(\hat{\alpha}_{i}-\alpha_{i}\right) K\left(\mathbf{x}_{i}, \mathbf{x}\right)+b F(x)⟹i∑(α^i−αi)K(xi,x)+b
回归训练集如下所示:
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x m , y m ) } D=\left\{\left(\mathbf{x}_{1}, y_{1}\right),\left(\mathbf{x}_{2}, y_{2}\right), \ldots,\left(\mathbf{x}_{m}, y_{m}\right)\right\} D={(x1,y1),(x2,y2),…,(xm,ym)}
其中,xi是一个n维向量,y是对应于每个xi的实数。SVR函数F(xi)将输入向量xi映射到目标yi,并采用以下形式:
F ( x ) ⟹ w ⋅ x − b F(\mathbf{x}) \Longrightarrow \mathbf{w} \cdot \mathbf{x}-b F(x)⟹w⋅x−b
其中,w是权向量,b是偏置。目标是估计参数(w和b),并给出数据最佳拟合的函数。SVR函数F(x)近似所有数据对
( x i , y i ) , \left(\mathbf{x}_{i}, y_{i}\right), (xi,yi),
同时在
E \mathcal{E} E
精度下保持估计值与实值之间的差异,即对于D中的每个输入向量x:
∣ y i − w ⋅ x i − b ≤ ε w ⋅ x i + b − y i ≤ ε \left| \begin{array}{l}{y_{i}-\mathbf{w} \cdot \mathbf{x}_{\mathbf{i}}-b \leq \varepsilon} \\ {\mathbf{w} \cdot \mathbf{x}_{\mathbf{i}}+b-y_{i} \leq \varepsilon}\end{array}\right. ∣∣∣∣yi−w⋅xi−b≤εw⋅xi+b−yi≤ε
其中,
m a r g i n = 1 ∥ w ∥ margin=\frac{1}{\|\mathbf{w}\|} margin=∥w∥1
通过
m i n ∥ w ∥ 2 , min\|\mathbf{w}\|^{2}, min∥w∥2,
从而最大化间隔,SVR中的训练成为一个约束优化问题:
m i n i m i z e : L ( w ) = 1 2 ∥ w ∥ 2 minimize:L(\mathbf{w})=\frac{1}{2}\|\mathbf{w}\|^{2} minimize:L(w)=21∥w∥2
s.t. y i − w ⋅ x i − b ≤ ε w ⋅ x i + b − y i ≤ ε \begin{aligned} \text { s.t. } & y_{i}-\mathbf{w} \cdot \mathbf{x}_{\mathbf{i}}-b \leq \varepsilon \\ & \mathbf{w} \cdot \mathbf{x}_{\mathbf{i}}+b-y_{i} \leq \varepsilon \end{aligned} s.t. yi−w⋅xi−b≤εw⋅xi+b−yi≤ε
这个问题的解决不允许有任何误差。为了允许在训练数据中出现一些误差来处理噪声。SVR软间隔松弛变量
ξ , ξ ^ \xi, \hat{\xi}_{} ξ,ξ^
然后将优化问题修改为:
m i n i m i z e : L ( w , ξ ) = 1 2 ∥ w ∥ 2 + C ∑ i ( ξ i 2 , ξ ^ i 2 ) , C > 0 ( 2.1 ) minimize:L(\mathbf{w}, \xi)=\frac{1}{2}\|\mathbf{w}\|^{2}+C \sum_{i}\left(\xi_{i}^{2}, \hat{\xi}_{i}^{2}\right), C>0(2.1) minimize:L(w,ξ)=21∥w∥2+Ci∑(ξi2,ξ^i2),C>0(2.1)
s . t . y i − w ⋅ x i − b ≤ ε + ξ i , ∀ ( x i , y i ) ∈ D ( 2.2 ) w ⋅ x i + b − y i ≤ ε + ξ ^ i , ∀ ( x i , y i ) ∈ D ( 2.3 ) s.t. \begin{array}{ll}{y_{i}-\mathbf{w} \cdot \mathbf{x}_{\mathbf{i}}-b \leq \varepsilon+\xi_{i},} & {\forall\left(\mathbf{x}_{i}, y_{i}\right) \in D}(2.2) \\ {\mathbf{w} \cdot \mathbf{x}_{\mathbf{i}}+b-y_{i} \leq \varepsilon+\hat{\xi}_{i},} & {\forall\left(\mathbf{x}_{i}, y_{i}\right) \in D}\end{array}(2.3) s.t.yi−w⋅xi−b≤ε+ξi,w⋅xi+b−yi≤ε+ξ^i,∀(xi,yi)∈D(2.2)∀(xi,yi)∈D(2.3)
ξ , ξ ^ i ≥ 0 ( 2.4 ) \xi, \hat{\xi}_{i} \geq 0(2.4) ξ,ξ^i≥0(2.4)
常数 C > 0 是间隔大小与误差之间的权衡参数。松弛变量
ξ , ξ ^ \xi, \hat{\xi}_{} ξ,ξ^
是针对不可行性约束的优化问题,对大于
E \mathcal{E} E
的过度偏差进行惩罚。
为了求解 (2.1) 的优化问题,我们可以用拉格朗日乘子从目标函数中构造拉格朗日函数:
minimize: L = 1 2 ∥ w ∥ 2 + C ∑ i ( ξ i + ξ ^ i ) − ∑ i ( η i ξ i + η ^ i ξ ^ i ) − ∑ i α i ( ε + η i − y i + w ⋅ x i + b ) − ∑ i α ^ i ( ε + η ^ i + y i − w ⋅ x i − b ) ( 2.5 ) \begin{array}{c}{\text { minimize: } L=\frac{1}{2}\|\mathbf{w}\|^{2}+C \sum_{i}\left(\xi_{i}+\hat{\xi}_{i}\right)-\sum_{i}\left(\eta_{i} \xi_{i}+\hat{\eta}_{i} \hat{\xi}_{i}\right)} \\ {-\sum_{i} \alpha_{i}\left(\varepsilon+\eta_{i}-y_{i}+\mathbf{w} \cdot \mathbf{x}_{i}+b\right)} \\ {-\sum_{i} \hat{\alpha}_{i}\left(\varepsilon+\hat{\eta}_{i}+y_{i}-\mathbf{w} \cdot \mathbf{x}_{i}-b\right)}\end{array}(2.5) minimize: L=21∥w∥2+C∑i(ξi+ξ^i)−∑i(ηiξi+η^iξ^i)−∑iαi(ε+ηi−yi+w⋅xi+b)−∑iα^i(ε+η^i+yi−w⋅xi−b)(2.5)
s . t . η , η ^ i ≥ 0 ( 2.6 ) α , α ^ i ≥ 0 ( 2.7 ) s.t.\begin{array}{l}{\eta, \hat{\eta}_{i} \geq 0}(2.6) \\ {\alpha, \hat{\alpha}_{i} \geq 0}(2.7)\end{array} s.t.η,η^i≥0(2.6)α,α^i≥0(2.7)
其中,
η i , η ^ i , α , α ^ i \eta_{i}, \hat{\eta}_{i}, \alpha, \hat{\alpha}_{i} ηi,η^i,α,α^i
是满足正约束条件的拉格朗日乘子。然后用L对每个拉格朗日乘子的偏导数,求函数L的最小值,从而求得鞍点:
∂ L ∂ b = ∑ i ( α i − α ^ i ) = 0 ( 2.8 ) ∂ L ∂ w = w − Σ ( α i − α ^ i ) x i = 0 , w = ∑ i ( α i − α ^ i ) x i ( 2.9 ) ∂ L ∂ ξ ^ i = C − α ^ i − η ^ i = 0 , η ^ i = C − α ^ i ( 2.10 ) \begin{aligned} \frac{\partial L}{\partial b} &=\sum_{i}\left(\alpha_{i}-\hat{\alpha}_{i}\right)=0(2.8) \\ \frac{\partial L}{\partial \mathbf{w}} &=\mathbf{w}-\Sigma\left(\alpha_{i}-\hat{\alpha}_{i}\right) \mathbf{x}_{i}=0, \mathbf{w}=\sum_{i}\left(\alpha_{i}-\hat{\alpha}_{i}\right) \mathbf{x}_{i}(2.9) \\ \frac{\partial L}{\partial \hat{\xi}_{i}} &=C-\hat{\alpha}_{i}-\hat{\eta}_{i}=0, \hat{\eta}_{i}=C-\hat{\alpha}_{i}(2.10) \end{aligned} ∂b∂L∂w∂L∂ξ^i∂L=i∑(αi−α^i)=0(2.8)=w−Σ(αi−α^i)xi=0,w=i∑(αi−α^i)xi(2.9)=C−α^i−η^i=0,η^i=C−α^i(2.10)
将式 (2.8) ~ (2.10) 代入式 (2.5),将不等式约束下的优化问题转化为对偶优化问题:
maximize: L ( α ) = ∑ i y i ( α i − α ^ i ) − ε ∑ i ( α i + α ^ i ) ( 2.11 ) − 1 2 ∑ i ∑ j ( α i − α ^ i ) ( α i − α ^ i ) x i x j ( 2.12 ) \begin{array}{r}{\text { maximize: } L(\alpha)=\sum_{i} y_{i}\left(\alpha_{i}-\hat{\alpha}_{i}\right)-\varepsilon \sum_{i}\left(\alpha_{i}+\hat{\alpha}_{i}\right)}(2.11) \\ {-\frac{1}{2} \sum_{i} \sum_{j}\left(\alpha_{i}-\hat{\alpha}_{i}\right)\left(\alpha_{i}-\hat{\alpha}_{i}\right) \mathbf{x}_{i} \mathbf{x}_{j}}(2.12)\end{array} maximize: L(α)=∑iyi(αi−α^i)−ε∑i(αi+α^i)(2.11)−21∑i∑j(αi−α^i)(αi−α^i)xixj(2.12)
s . t . ∑ i ( α i − α ^ i ) = 0 ( 2.13 ) 0 ≤ α , α ^ ≤ C ( 2.14 ) s.t.\begin{array}{c}{\sum_{i}\left(\alpha_{i}-\hat{\alpha}_{i}\right)=0}(2.13) \\ {0 \leq \alpha, \hat{\alpha} \leq C}(2.14)\end{array} s.t.∑i(αi−α^i)=0(2.13)0≤α,α^≤C(2.14)
对偶变量
η , η ^ i \eta, \hat{\eta}_{i} η,η^i
将式 (2.5) 修改为式 (2.8), (2.11)过程中被剔除,式 (2.8) 可重写为:
w = ∑ i ( α i − α ^ i ) x i ( 2.15 ) η i = C − α i ( 2.16 ) η ^ i = C − α ^ i ( 2.17 ) \begin{aligned} w &=\sum_{i}\left(\alpha_{i}-\hat{\alpha}_{i}\right) \mathbf{x}_{i}(2.15) \\ \eta_{i} &=C-\alpha_{i}(2.16) \\ \hat{\eta}_{i} &=C-\hat{\alpha}_{i}(2.17) \end{aligned} wηiη^i=i∑(αi−α^i)xi(2.15)=C−αi(2.16)=C−α^i(2.17)
其中w由训练向量xi的线性组合表示。因此,SVR函数F(x)的形式将变为:
F ( x ) ⟹ ∑ i ( α i − α ^ i ) x i x + b ( 2.18 ) F(\mathbf{x}) \Longrightarrow \sum_{i}\left(\alpha_{i}-\hat{\alpha}_{i}\right) \mathbf{x}_{i} \mathbf{x}+b(2.18) F(x)⟹i∑(αi−α^i)xix+b(2.18)
在允许误差的情况下,式 (2.18) 可以将训练向量映射到目标实值,但不能处理非线性SVR情况。同样的核技巧也可以用核函数替换两个向量 xi,xj 的内积
K ( x i , x j ) . K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right). K(xi,xj).
变换后的特征空间通常是高维的,该空间中的SVR函数在原输入空间中变为非线性。利用核函数K,可以快速计算变换后的特征空间内积,其计算速度与原输入空间内积 xi·xj 的计算速度相当。
一旦用核函数K代替原来的内积,剩下的求解优化问题的过程就与线性SVR的过程非常相似。利用核函数可以改变线性优化函数:
maximize: L ( α ) = ∑ i y i ( α i − α ^ i ) − ε ∑ i ( α i + α ^ i ) − 1 2 ∑ i ∑ j ( α i − α ^ i ) ( α i − α ^ i ) K ( x i , x j ) ( 2.19 ) \begin{array}{c}{\text { maximize: } L(\alpha)=\sum_{i} y_{i}\left(\alpha_{i}-\hat{\alpha}_{i}\right)-\varepsilon \sum_{i}\left(\alpha_{i}+\hat{\alpha}_{i}\right)} \\ {-\frac{1}{2} \sum_{i} \sum_{j}\left(\alpha_{i}-\hat{\alpha}_{i}\right)\left(\alpha_{i}-\hat{\alpha}_{i}\right) K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)}(2.19)\end{array} maximize: L(α)=∑iyi(αi−α^i)−ε∑i(αi+α^i)−21∑i∑j(αi−α^i)(αi−α^i)K(xi,xj)(2.19)
s . t . ∑ i ( α i − α ^ i ) = 0 ( 2.20 ) α ^ i ≥ 0 , α i ≥ 0 ( 2.21 ) 0 ≤ α , α ^ ≤ C ( 2.22 ) s.t.\sum_{i}\left(\alpha_{i}-\hat{\alpha}_{i}\right)=0(2.20) \\ \begin{array}{l}{\hat{\alpha}_{i} \geq 0, \alpha_{i} \geq 0}(2.21) \\ {0 \leq \alpha, \hat{\alpha} \leq C}(2.22)\end{array} s.t.i∑(αi−α^i)=0(2.20)α^i≥0,αi≥0(2.21)0≤α,α^≤C(2.22)
最后,使用核函数将SVR函数**F(x)**变成如下形式:
F ( x ) ⟹ ∑ i ( α ^ i − α i ) K ( x i , x ) + b ( 2.23 ) . F(\mathbf{x}) \Longrightarrow \sum_{i}\left(\hat{\alpha}_{i}-\alpha_{i}\right) K\left(\mathbf{x}_{i}, \mathbf{x}\right)+b(2.23). F(x)⟹i∑(α^i−αi)K(xi,x)+b(2.23).
3 SVM Ranking
Ranking SVM是一种学习排序(或偏好)的函数,在[信息检索][5]中产生了多种应用。学习排序函数的任务与学习分类函数的任务的区别如下:
- 分类中的训练集是一组数据对象及其类标签,而排序中的训练集是数据的排序。如果令 A 偏好于 B,则指定
′ ′ A > B ′ ′ , ^{\prime \prime}A>B^{\prime \prime}, ′′A>B′′,
将 Ranking SVM 训练集记为:
R = { ( x 1 , y i ) , … , ( x m , y m ) } R=\left\{\left(\mathbf{x}_{1}, y_{i}\right), \ldots,\left(\mathbf{x}_{m}, y_{m}\right)\right\} R={(x1,yi),…,(xm,ym)}
其中,yi 是 xi 的排序,即:
y i < y j if x i > x j . y_{i}<y_{j} \text { if } \mathbf{x}_{i}>\mathbf{x}_{j}. yi<yj if xi>xj.
- 不同于分类函数,即为数据对象输出不同的类别,排序函数为每个数据对象输出一个分数,并从中构造数据的全局排序。换言之,目标函数 F (xi) 输出一个分数,对于任何
x i > x j , \mathbf{x}_{i}>\mathbf{x}_{j}, xi>xj,
都有,
F ( x i ) > F ( x j ) F\left(\mathbf{x}_{i}\right)>F\left(\mathbf{x}_{j}\right) F(xi)>F(xj)
如果没有特别说明,R 认为是严格排序,这意味着所有的数据对xi和xj在一个数据集合D中,
x i > R x j 或 x i < R x j . \mathbf{x}_{i}>_{R} \mathbf{x}_{j} \text { 或 } \mathbf{x}_{i}<_{R} \mathbf{x}_{j}. xi>Rxj 或 xi<Rxj.
然而,它可以推广到弱排序。令数据的最优排序为
R ∗ , 其 中 数 据 按 照 用 户 的 偏 好 完 美 地 排 序 R^{*},其中数据按照用户的偏好完美地排序 R∗,其中数据按照用户的偏好完美地排序
其中数据按照用户的偏好完美地排序。排序函数F通常由它的排序与近似,即
排 序 R F 与近似 R ∗ 排序 R^{F} \text { 与近似 } R^{*} 排序RF 与近似 R∗
来评估。
利用SVMd的技术,可以从排序R中学习到全局排序函数F。假设F为线性排序函数:
∀ { ( x i , x j ) : y i < y j ∈ R } : F ( x i ) > F ( x j ) ⟺ w ⋅ x i > w ⋅ x j ( 3.1 ) \forall\left\{\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) : y_{i}<y_{j} \in R\right\} : F\left(\mathbf{x}_{i}\right)>F\left(\mathbf{x}_{j}\right) \Longleftrightarrow \mathbf{w} \cdot \mathbf{x}_{i}>\mathbf{w} \cdot \mathbf{x}_{j}(3.1) ∀{(xi,xj):yi<yj∈R}:F(xi)>F(xj)⟺w⋅xi>w⋅xj(3.1)
通过学习算法调整权重向量w。对所有的
{ ( x i , x j ) : y i < y j ∈ R } , \left\{\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) : y_{i}<y_{j} \in R\right\}, {(xi,xj):yi<yj∈R},
如果存在一个函数F(由权重向量w表示)满足等式 (3.1),那么排序R是线性可排序的。
我们的目标是学习与R顺序一致的F,并推广到R之外。换言之,即找到权重向量w,使得对于大多数数据对
{ ( x i , x j ) : y i < y j ∈ R } , \left\{\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) : y_{i}<y_{j} \in R\right\}, {(xi,xj):yi<yj∈R},
都有
w ⋅ x i > w ⋅ x j \mathbf{w} \cdot \mathbf{x}_{i}>\mathbf{w} \cdot \mathbf{x}_{j} w⋅xi>w⋅xj
虽然该问题公认为[NP-hard][],但可以通过引入(非负)松弛变量
ξ i j , \xi_{i j}, ξij,
和最小化上界
m i n i m i z e : ∑ ξ i j minimize:\sum \xi_{i j} minimize:∑ξij
利用SVM技术近似求解:
m i n i m i z e : L 1 ( w , ξ i j ) = 1 2 w ⋅ w + C Σ ξ i j ( 3.2 ) minimize:\quad L_{1}\left(\mathbf{w}, \xi_{i j}\right)=\frac{1}{2} \mathbf{w} \cdot \mathbf{w}+C \Sigma \xi_{i j}(3.2) minimize:L1(w,ξij)=21w⋅w+CΣξij(3.2)
s . t . ∀ { ( x i , x j ) : y i < y j ∈ R } : w ⋅ x i ≥ w ⋅ x j + 1 − ξ i j ( 3.3 ) ∀ ( i , j ) : ξ i j ≥ 0 ( 3.4 ) s.t.\begin{aligned} \forall\left\{\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) : y_{i}<y_{j} \in R\right\} & : \mathbf{w} \cdot \mathbf{x}_{i} \geq \mathbf{w} \cdot \mathbf{x}_{j}+1-\xi_{i j}(3.3) \\ & \forall(i, j) : \xi_{i j} \geq 0 (3.4)\end{aligned} s.t.∀{(xi,xj):yi<yj∈R}:w⋅xi≥w⋅xj+1−ξij(3.3)∀(i,j):ξij≥0(3.4)
上述优化问题以最小误差满足训练集R上的排序。通过最小化 w·w 或最大化间隔,其目的是最大化排序函数的泛化能力,下节我们将解释如何最大限度地提高排序的泛化程度。C 为软间隔参数,用于控制间隔大小与训练误差的平衡。
通过将约束 (3.3) 重新排列为:
w ( x i − x j ) ≥ 1 − ξ i j ( 3.5 ) \mathbf{w}\left(\mathbf{x}_{i}-\mathbf{x}_{j}\right) \geq 1-\xi_{i j}(3.5) w(xi−xj)≥1−ξij(3.5)
该优化问题等价于基于两两差分向量的SVM分类问题
( x i − x j ) . \left(\mathbf{x}_{i}-\mathbf{x}_{j}\right). (xi−xj).
因此,我们可以扩展现有的SVM实现来解决这个问题。
值得注意的是,支持向量是满足条件的数据对
( x i s , x j s ) , \left(\mathbf{x}_{i}^{s}, \mathbf{x}_{j}^{s}\right), (xis,xjs),
即使得约束 (3.5) 满足等式符号,比如,
w ( x i s − x j s ) = 1 − ξ i j . \mathbf{w}\left(\mathbf{x}_{i}^{s}-\mathbf{x}_{j}^{s}\right)=1-\xi_{i j}. w(xis−xjs)=1−ξij.
在边缘(margin)上的无界支持向量,比如,
松 弛 变 量 ξ i j = 0. 松弛变量\xi_{i j}=0. 松弛变量ξij=0.
边缘内的有界支持向量,比如,
1 > ξ i j > 0. 1>\xi_{i j}>0. 1>ξij>0.
或者误排序的支持向量,比如,
ξ i j > 1. \xi_{i j}>1. ξij>1.
与SVM分类一样,支持向量机排序中的函数F也仅由支持向量表示。
与分类支持向量机相似,利用拉格朗日乘子可以将分类支持向量机的原始排序问题转化为以下对偶问题:
L 2 ( α ) = ∑ i j α i j − ∑ i j ∑ i v α i j α n v K ( x i − x j , x u − x v ) ( 3.6 ) L_{2}(\alpha)=\sum_{i j} \alpha_{i j}-\sum_{i j} \sum_{i v} \alpha_{i j} \alpha_{n v} K\left(\mathbf{x}_{i}-\mathbf{x}_{j}, \mathbf{x}_{u}-\mathbf{x}_{v}\right)(3.6) L2(α)=ij∑αij−ij∑iv∑αijαnvK(xi−xj,xu−xv)(3.6)
C ≥ α ≥ 0 ( 3.7 ) C \geq \alpha \geq 0(3.7) C≥α≥0(3.7)
将核函数转化为对偶函数后,就可以利用核函数的核技巧来解决非线性排序函数。
一旦
α \alpha α
计算出之后,w可以写为成对的差向量及其系数的形式:
w = ∑ i j α i j ( x i − x j ) ( 3.8 ) \mathbf{w}=\sum_{i j} \alpha_{i j}\left(\mathbf{x}_{i}-\mathbf{x}_{j}\right)(3.8) w=ij∑αij(xi−xj)(3.8)
利用核函数替换点积操作,同时也可以计算新向量z上的排序函数F:
F ( z ) = w ⋅ z = ∑ i j α i j ( x i − x j ) ⋅ z = ∑ i j α i j K ( x i − x j , z ) ( 3.9 ) F(\mathbf{z})=\mathbf{w} \cdot \mathbf{z}=\sum_{i j} \alpha_{i j}\left(\mathbf{x}_{i}-\mathbf{x}_{j}\right) \cdot \mathbf{z}=\sum_{i j} \alpha_{i j} K\left(\mathbf{x}_{i}-\mathbf{x}_{j}, \mathbf{z}\right)(3.9) F(z)=w⋅z=ij∑αij(xi−xj)⋅z=ij∑αijK(xi−xj,z)(3.9)
3.1 Ranking SVM 间隔最大化
本节我们将解释Ranking SVM的间隔最大化,并探讨Ranking SVM如何生成高泛化能力的排序函数。首先,我们需要建立Ranking SVM的一些基本性质。为了便于解释,我们假设训练集R是线性排序的,因此我们使用硬间隔SVM,比如,在目标函数 (3.2) 以及约束条件 (3.3) 中,此时,令
∀ ( i , j ) : ξ i j = 0. \forall(i, j) : \xi_{i j} = 0. ∀(i,j):ξij=0.
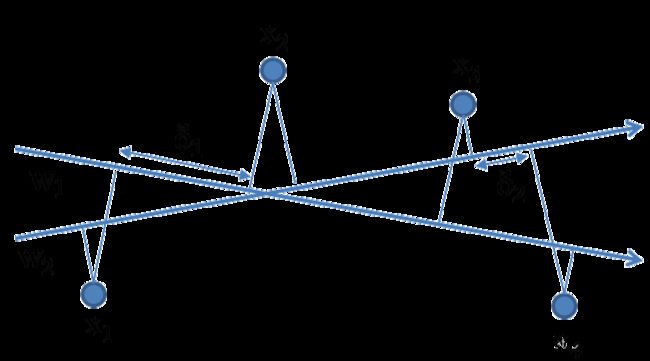
图一 四个数据点的线性投影
在等式 (3.1) 中,线性排序函数Fw将数据向量投影到权值向量w上。如上图所示,其说明了四个向量
{ x 1 , x 2 , x 3 , x 4 } \left\{\mathbf{x}_{1}, \mathbf{x}_{2}, \mathbf{x}_{3}, \mathbf{x}_{4}\right\} {x1,x2,x3,x4}
在二维空间分别投影到两个不同的权值向量 w1 和 w2 上。
F x 1 和 F x 2 F_{\mathbf{x}_{1}} \text { 和 } F_{\mathbf{x}_{2}} Fx1 和 Fx2
对这四个向量在 R 上都有相同的排序,即
x 1 > R x 2 > R x 3 > R x 4 . \mathbf{x}_{1}>_{R} \mathbf{x}_{2}>_{R} \mathbf{x}_{3}>_{R} \mathbf{x}_{4}. x1>Rx2>Rx3>Rx4.
两个向量 (xi,xj) 的排序的差异根据一个排序函数Fw,其用投影到w上的两个向量的几何距离表示,即
w ( x i − x j ) ∥ w ∥ . \frac{\mathbf{w}\left(\mathbf{x}_{i}-\mathbf{x}_{j}\right)}{\|\mathbf{w}\|}. ∥w∥w(xi−xj).
软间隔SVM允许
ξ i j > 0 \xi_{i j}>0 ξij>0
的有界支持向量和
ξ i j = 0 \xi_{i j}=0 ξij=0
的无界支持向量,主要是为了处理噪声,并允许有小误差的R是不完全线性排序的。然而,在等式 (3.2) 的目标函数中也使得松弛变量和误差的数量最小化,同时支持向量在排序中也是近邻的数据对。因此,最大化间隔在排序中,产生了将相近数据对的差异最大化的效果。
理论证明,Ranking SVM能够通过最大化最小的排序差异来提高泛化性能。例如,在上图中,考虑两个线性排序函数Fw1和Fw2,虽然两个权值向量w1和w2的排序相同,但是直观上w1比w2更有一般性,因为w1上最近的向量之间的距离大于w2。SVM计算权重向量w,最大限度地提高排序中相近数据对之间的差异。Ranking SVM通过这种方法得到了一个高泛化的排序函数。
4 Ranking Vector Machine
本节我们将介绍另一种排序学习方法,Ranking Vector Machine (RVM),改进后的1-范数 ranking SVM 比标准ranking SVM 更适合于特征选择和较大规模数据集的扩展。
首先我们提出了一种基于1-范数目标函数的 ranking SVM,而标准 ranking SVM 是基于2-范数的目标函数。与标准SVM相比,1-范数 ranking SVM 学习的支持向量要少得多。因此,它的测试时间比2-范数支持向量机快得多,并提供了更好的特性选择属性。特征选择在排序中也很重要。排序函数是文档或数据检索中的关联函数或偏好函数。关键特性的识别增加了函数的可解释性。非线性核函数的特征选择也极具挑战性,一般来说,[支持向量的个数越少,特征选择的效率越高][]。
接下来,将对提出的 RVM 做进一步说明,它修正了1范数的 ranking SVM 其目的是为了快速训练。RVM 的训练速度比标准的支持向量机快得多,但当训练集相对较大时,RVM 的训练精度不会受到影响。RVM 的核心思想是用“排序向量”代替支持向量来表示排序函数。支持向量在 ranking SVM 中是最近邻对的两两差分向量,因此,训练需要将每个数据对作为潜在的支持向量候选项进行检验,数据对的数量与训练集的大小成二次关系。另一方面, RVM 的排序函数利用每个训练数据对象而不是数据对。因此,RVM 中用于优化的变量数量大大减少。
4.1 1-norm Ranking SVM
1-范数 ranking SVM 的目标与标准 ranking SVM 的目标相同,即学习满足等式 (3.1),对于大多数
{ ( x i , x j ) : y i < y j ∈ R } , \left\{\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right) : y_{i}<y_{j} \in R\right\}, {(xi,xj):yi<yj∈R},
并在训练集之外也有较好的泛化能力。在1-范数 ranking SVM 中,我们利用如下等式中的F表示:
F ( x u ) > F ( x v ) ⟹ ∑ i j P α i j ( x i − x j ) ⋅ x u > ∑ i j P α i j ( x i − x j ) ⋅ x v ( 4.1 ) F\left(\mathbf{x}_{u}\right)>F\left(\mathbf{x}_{v}\right) \Longrightarrow \sum_{i j}^{P} \alpha_{i j}\left(\mathbf{x}_{i}-\mathbf{x}_{j}\right) \cdot \mathbf{x}_{u}>\sum_{i j}^{P} \alpha_{i j}\left(\mathbf{x}_{i}-\mathbf{x}_{j}\right) \cdot \mathbf{x}_{v} (4.1) F(xu)>F(xv)⟹ij∑Pαij(xi−xj)⋅xu>ij∑Pαij(xi−xj)⋅xv(4.1)
⟹ ∑ i j P α i j ( x i − x j ) ⋅ ( x u − x v ) > 0 ( 4.2 ) \Longrightarrow \sum_{i j}^{P} \alpha_{i j}\left(\mathbf{x}_{i}-\mathbf{x}_{j}\right) \cdot\left(\mathbf{x}_{u}-\mathbf{x}_{v}\right)>0(4.2) ⟹ij∑Pαij(xi−xj)⋅(xu−xv)>0(4.2)
然后,用一个核函数替换内积,即1-范数排序 SVM 表示为:
minimize : L ( α , ξ ) = ∑ i j P α i j + C ∑ i j P ξ i j ( 4.3 ) \operatorname{minimize} : \quad L(\alpha, \xi)=\sum_{i j}^{P} \alpha_{i j}+C \sum_{i j}^{P} \xi_{i j}(4.3) minimize:L(α,ξ)=ij∑Pαij+Cij∑Pξij(4.3)
s . t . ∑ i j P α i j K ( x i − x j , x u − x v ) ≥ 1 − ξ u v , ∀ { ( u , v ) : y u < y v ∈ R } ( 4.4 ) s.t. \sum_{i j}^{P} \alpha_{i j} K\left(\mathbf{x}_{i}-\mathbf{x}_{j}, \mathbf{x}_{u}-\mathbf{x}_{v}\right) \geq 1-\xi_{u v}, \forall\left\{(u, v) : y_{u}<y_{v} \in R\right\}(4.4) s.t.ij∑PαijK(xi−xj,xu−xv)≥1−ξuv,∀{(u,v):yu<yv∈R}(4.4)
α ≥ 0 , ξ ≥ 0 ( 4.5 ) \alpha \geq 0, \xi \geq 0(4.5) α≥0,ξ≥0(4.5)
标准 ranking SVM 通过抑制权值w以提高泛化性能,而1-范数排序抑制目标函数中的
α \alpha α
由于权值由系数与两两排序差向量的和表示,所以抑制系数
α \alpha α
对应于抑制标准SVM中的权值向量w。C 是一个用户参数,控制间距大小和误差量之间的权衡,K是核函数。P是成对差分向量的个数。
实践表明,与标准的2-范数支持向量机相比,1-范数支持向量机使用的支持向量要少得多,即 1-范数支持向量机训练后的正系数的统计量明显小于标准2-范数支持向量机训练后的统计量。这是因为与标准的2-范数SVM不同,在1-范数中的支持向量在分类时不受边界的约束,或者在排序时不受最小排序差向量的约束。因此,测试涉及的核评估要少得多,而且当训练集包含有噪声特性时,测试的鲁棒性更强。
4.2 Ranking Vector Machine
虽然1-范数 ranking SVM 在测试效率和特征选择方面优于标准 ranking SVM,但其训练复杂度非常高 (关于数据点的数量)。Ranking Vector Machine (RVM) 改进了1-范数 ranking SVM,大大减少了训练时间。RVM 在不影响优化精度的前提下,显著减少了优化问题中的变量的数量。RVM 的核心思想是用“排序向量”代替支持向量来表示排序函数。Ranking SVM 的支持向量是从两两不同的向量中选取的,两两不同向量的个数与训练集的大小成二次关系。另一方面,从训练向量中选取排序向量,大大减少了待优化变量的数量。
与2-范数 SVM 不同,1-范数 SVM 可以用更少的支持向量来表示相似的边界函数。直接扩展自2-范数 SVM ,2-范数 ranking SVM 通过最大化其间隔对应的最接近的两两排序差来提高泛化能力。因此,2-范数ranking SVM 用最接近的两两差向量表示函数。然而,1-范数 ranking SVM 与 1-范数 SVM 一样,通过其对应的抑制系数来提高泛化能力。因此,1-范数 ranking SVM 中的支持向量不再是最接近的两两差分向量,同时,在1-范数 ranking SVM 中,用两两不同的向量来表示排序函数并不是有益的。
5 总结
本文基于 SVM 的理论基础,循序渐进地介绍了分类、回归和排序问题。通过类比推演的方式,我们可以进一步发现这三者存在一定的关联性,但也有本质的区别。
从概念上讲,排序问题定义为对一组样本(或实例)进行排序的派生,这些实例可以最大化整个列表的效用。排序问题在一定程度上类似于分类和回归问题,但其从根本上是不同的。分类或回归的目标是尽可能准确地预测每个实例的标签或实值,而排序的目标是对整个实例列表进行优化排序,以便最先显示相关度最高的实例。