MapReduce
MapReduce的是一个编程模型,用于大规模数据集(大于1TB)的并行运算,它可以将单个计算作业分配给多台计算机执行。
MapReduce最早由谷歌在2004年在论文中提出,概念"Map(映射)"和"Reduce(归约)",是它们的主要思想。
MapReduce在大量节点组成的集群上运行,它的工作流程是:
单个作业被分成很多小份,输人数据也被切片分发到每个节点,各个节点只在本地数据上做运算,对应的运算代码称为mapper,这
个过程被称作map阶段。每个mapper的输出通过某种方式组合(一般还会做排序)。排序后的结果再被分成小份分发到各个节点
进行下一步处理工作。第二步的处理阶段被称为reduce阶段,对应的运行代码被称为reducer。reducer的输出就是程序的最终
执行结果。
MapReduce的优势在于,它使得程序以并行方式执行。如果集群由10个节点组成,而原先的作业需要10个小时来完成,那么应
用MapReuce,该作业将在一个多小时之后得到同样的结果。
reducer的数量并不是固定的。此外,在MapReduce的框架中还有其他一些灵活的配置选项。MapReuce的整个编配工作由主节
点(master node)控制。这些主节点控制整个MapReduce作业编配,包括每份数据存放的节点位置,以及map、sort和reduce
等阶段的时序控制等。此外,主节点还要包含容错机制。一般地,每份mapper的输入数据会同时分发到多个节点形成多份副
本,用于事务的失效处理。一个MapReduce集群的示意图如图所示。
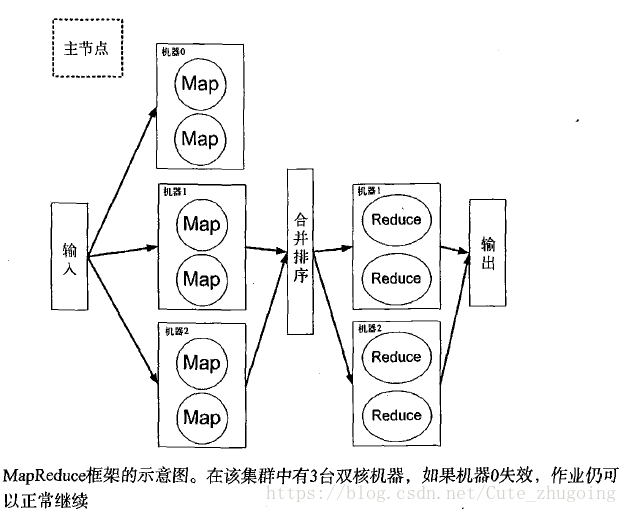
总结一下上面几个例子中关于MapReduce的学习要点:
□ 主节点控制MapReduce的作业流程;
□ MapReduce的作业可以分成map任务和reduce任务;
□ map任务之间不做数据交流,reduce任务也一样;
□ 在map和reduce阶段中间,有一个sort或combine阶段;
□数据被重复存放在不同的机器上,以防某个机器失效;
□ mapper和reducer传输的数据形式为key/value对。
Apache的Hadoop项目是MapReduce框架的一个实现。下一节将开始讨论Hadoop项目,并介绍如何在Python中使用它。
Hadoop是一个开源的Java项目,为运行MapReduce作业提供了大量所需的功能。除了分布式计算之外,Hadoop 自带分布式
文件系统。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,
并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些
有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming
access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供
了计算。