【转载】ILSVRC2016目标检测任务回顾:视频目标检测(VID)
【转载】ILSVRC2016目标检测任务回顾:视频目标检测(VID)
转载自: http://geek.csdn.net/news/detail/133792
图像目标检测任务在过去三年的时间取得了巨大的进展,检测性能得到明显提升。但在视频监控、车辆辅助驾驶等领域,基于视频的目标检测有着更为广泛的需求。由于视频中存在运动模糊,遮挡,形态变化多样性,光照变化多样性等问题,仅利用图像目标检测技术检测视频中的目标并不能得到很好的检测结果。如何利用视频中目标时序信息和上下文等信息成为提升视频目标检测性能的关键。
ILSVRC2015新增加了视频目标检测任务(Object detection from video, VID),这为研究者提供了良好的数据支持。ILSVRC2015的VID评价指标与图像目标检测评价指标相同——计算检测窗口的mAP。然而对于视频目标检测来说,一个好的检测器不仅要保证在每帧图像上检测准确,还要保证检测结果具有一致性/连续性(即对于一个特定目标,优秀的检测器应持续检测此目标并且不会将其与其他目标混淆)。ILSVRC2016针对这个问题在VID任务上新增加了一个子任务(详见第四部分——视频目标检测时序一致性介绍)。
在ILSVRC2016上,在不使用外部数据的VID两个子任务上,前三名由国内队伍包揽(见表1、表2)。本文主要结合NUIST,CUVideo,MCG-ICT-CAS以及ITLab-Inha四个队伍公布的相关资料对ILSVRC2016中的视频目标检测方法进行了总结。
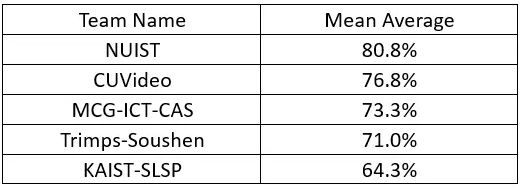
表1 ILSVRC2016 VID results(无外部数据)
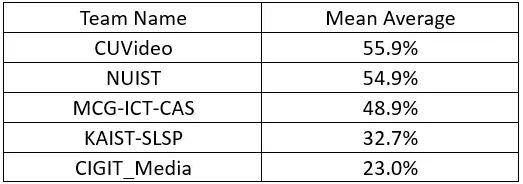
表2 ILSVRC2016 VID tracking result(无外部数据)
通过对参赛队伍的相关报告[2-5]进行学习了解,视频目标检测算法目前主要使用了如下的框架:
- 将视频帧视为独立的图像,利用图像目标检测算法获取检测结果;
- 利用视频的时序信息和上下文信息对检测结果进行修正;
- 基于高质量检测窗口的跟踪轨迹对检测结果进一步进行修正。
本文分为四部分,前三个部分介绍如何提升视频目标检测的精度,最后介绍如何保证视频目标检测的一致性。
1. 单帧图像目标检测
此阶段通常将视频拆分成相互独立的视频帧来处理,通过选取优秀的图像目标检测框架以及各种提高图像检测精度的技巧来获取较为鲁棒的单帧检测结果。《ILSVRC2016目标检测任务回顾(上)–图像目标检测》已对此进行详细总结,这里不再重复。
结合自己实验及各参赛队伍的相关文档,我们认为训练数据的选取以及网络结构的选择对提升目标检测性能有至关重要的作用。
训练数据选取
首先对ILSVRC2016 VID训练数据进行分析: VID数据库包含30个类别,训练集共有3862个视频片段,总帧数超过112万。单从数字上看,这么大的数据量训练30个类别的检测器似乎已经足够。然而,同一个视频片段背景单一,相邻多帧的图像差异较小。所以要训练现有目标检测模型,VID训练集存在大量数据冗余,并且数据多样性较差,有必要对其进行扩充。在比赛任务中,可以从ILSVRC DET和ILSVRC LOC数据中抽取包含VID类别的图片进行扩充。CUVideo、NUIST和MCG-ICT-CAS使用ILSVRC VID+DET作为训练集,ITLab-Inha使了ILSVRC VID+DET、COCO DET等作为训练集。需要注意的是在构建新的训练集的时候要注意平衡样本并去除冗余(CUVideo和MCG-ICT-CAS抽取部分VID训练集训练模型,ITLab-Inha在每个类别选择一定数量图像参与训练,NUIST使用在DET上训练的模型对VID数据进行筛选)。对于同样的网络,使用扩充后的数据集可以提高10%左右的检测精度。网络结构选取
不同的网络结构对于检测性能也有很大影响。我们在VID验证集上进行实验:同样的训练数据,基于ResNet101[6]的Faster R-CNN[7]模型的检测精度比基于VGG16[8]的Faster R-CNN模型的检测精度高12%左右。这也是MSRA在2015年ILSVRC和COCO比赛上的制胜关键。今年比赛前几名的队伍基本上也是使用ResNet/Inception的基础网络,CUVideo使用269层的GBD-Net[9]。
2. 改进分类损失
- MGP
单帧检测结果存在很多漏检目标,而相邻帧图像检测结果中可能包含这些漏检目标。所以我们可以借助光流信息将当前帧的检测结果前向后向传播,经过MGP处理可以提高目标的召回率。如图1所示将T时刻的检测窗口分别向前向后传播,可以很好地填补T-1和T+1时刻的漏检目标。
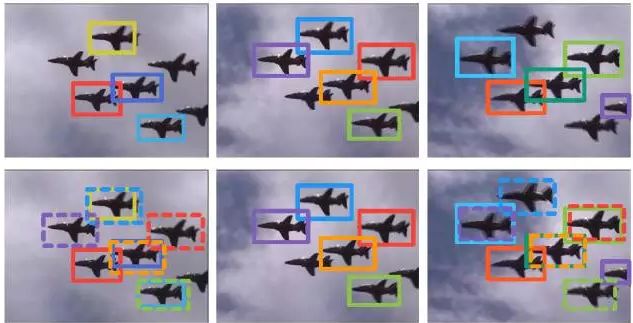
图1 MGP示意图[10]
- MCS
使用图像检测算法将视频帧当做独立的图像来处理并没有充分利用整个视频的上下文信息。虽然说视频中可能出现任意类别的目标,但对于单个视频片段,只会出现比较少的几个类别,而且这几个类别之间有共现关系(出现船只的视频段中可能会有鲸鱼,但基本不可能出现斑马)。所以,可以借助整个视频段上的检测结果进行统计分析:对所有检测窗口按得分排序,选出得分较高的类别,剩余那些得分较低的类别很可能是误检,需对其得分进行压制(如图2)。经过MCS处理后的检测结果中正确的类别靠前,错误的类别靠后,从而提升目标检测的精度。

图2 多上下文抑制示意图[10]
3. 利用跟踪信息修正
上文提到的MGP可以填补某些视频帧上漏检的目标,但对于多帧连续漏检的目标不是很有效,而目标跟踪可以很好地解决这个问题。CUVideo, NUIST, MCG-ICT-CAS以及ITLab-Inha四支参赛队伍都使用了跟踪算法进一步提高视频目标检测的召回率。使用跟踪算法获取目标序列基本流程如下:
- 使用图像目标检测算法获取较好的检测结果;
- 从中选取检测得分最高的目标作为跟踪的起始锚点;
- 基于选取的锚点向前向后在整个视频片段上进行跟踪,生成跟踪轨迹;
- 算法迭代执行,可以使用得分阈值作为终止条件。
得到的跟踪轨迹既可以用来提高目标召回率,也可以作为长序列上下文信息对结果进行修正。
4.网络选择与训练技巧
对于视频目标检测,除了要保证每帧图像的检测精度,还应该保证长时间稳定地跟踪每个目标。为此,ILSVRC2016新增一个VID子任务,此任务计算每个目标跟踪轨迹(tracklet)/管道(tubelet)的mAP来评测检测算法的时序一致性或者说跟踪连续性的性能。
那么如何保证视频检测中目标的时序一致性呢?本文认为可以从以下三个方面入手:(1)保证图像检测阶段每帧图像检测的结果尽量精准;(2)对高质量检测窗口进行跟踪并保证跟踪的质量(尽量降低跟踪中出现的漂移现象);(3)前面两步获取到的跟踪结果会存在重叠或者临接的情况,需针对性地进行后处理。
ITLab-Inha团队提出了基于变换点检测的多目标跟踪算法[11],该算法首先检测出目标,然后对其进行跟踪,并在跟踪过程中对跟踪轨迹点进行分析处理,可以较好地缓解跟踪时的漂移现象,并能在轨迹异常时及时终止跟踪。
针对视频目标检测的一致性问题,作者所在的MCG-ICT-CAS提出了基于检测和跟踪的目标管道生成方法。

图3 基于检测/跟踪/检测+跟踪管道示意图
图3-a表示使用跟踪算法获取到的目标管道(红色包围框),绿色包围框代表目标的Ground Truth。可以看到随着时间推移,跟踪窗口逐渐偏移目标,最后甚至可能丢失目标。MCG-ICT-CAS提出了基于检测的目标管道生成方法,如图3-b所示,基于检测的管道窗口(红色包围框)定位较为准确,但由于目标的运动模糊使检测器出现漏检。从上面分析可知:跟踪算法生成的目标管道召回率较高,但定位不准;而基于检测窗口生成的目标管道目标定位较为精准,但召回率相对前者较低。由于两者存在互补性,所以MCG-ICT-CAS进一步提出了管道融合算法,对检测管道和跟踪管道进行融合,融合重复出现的窗口并且拼接间断的管道。
如图4所示,相对于单独的检测或者跟踪生成的目标管道,融合后目标管道对应的检测窗口的召回率随着IoU阈值的增加一直保持较高的值,说明了融合后的窗口既能保持较高的窗口召回率,也有较为精准的定位。融合后的目标管道mAP在VID测试集上提升了12.1%。
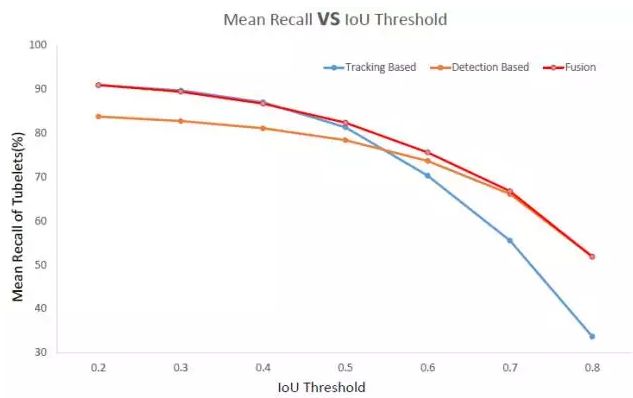
图4 不同方法生成目标管道的召回率
5.总结
本文主要结合ILSVRC2016 VID竞赛任务对视频目标检测算法进行介绍。相对于图像目标检测,当前的视频目标检测算法流程比较繁琐且视频自身包含的信息没有被充分挖掘。如何精简视频目标检测流程使其具有实时性,如何进一步挖掘视频包含的丰富信息使其具有更高的检测精度,以及如何保证视频目标检测的一致性或许是视频目标检测接下来要着重解决的问题。
[1]ILSVRC2016相关报告:
http://image-net.org/challenges/ilsvrc+coco2016
[2]CUVideo slide下载链接:
http://image-net.org/challenges/talks/2016/GBD-Net.pdf
[3]NUIST slide下载链接
http://image-net.org/challenges/talks/2016/Imagenet%202016%20VID.pptx
[4]MCG-ICT-CAS slide下载链接
http://image-net.org/challenges/talks/2016/MCG-ICT-CAS-ILSVRC2016-Talk-final.pdf
[5]ITLab-Inha slide 下载链接
http://image-net.org/challenges/talks/2016/ILSVRC2016_ITLab_for_pdf.pdf
[6]He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[J]. arXiv preprint arXiv:1512.03385, 2015.
[7]Ren S, He K, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015: 91-99.
[8]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[9]Zeng X, Ouyang W, Yang B, et al. Gated bi-directional cnn for object detection[C]//European Conference on Computer Vision. Springer International Publishing, 2016: 354-369.
[10]Kang K, Li H, Yan J, et al. T-cnn: Tubelets with convolutional neural networks for object detection from videos[J]. arXiv preprint arXiv:1604.02532, 2016.
[11]Lee B, Erdenee E, Jin S, et al. Multi-class Multi-object Tracking Using Changing Point Detection[C]//European Conference on Computer Vision. Springer International Publishing, 2016: 68-83.