春招面试经验系列(三)商汤科技
商汤科技
java基本上问的都是多线程的问题
一、java中int存储字节数:
1、1字节(byte)= 8位(bit)
2、整型:short 2字节、int 4字节、long 8字节
3、浮点型:float 4字节、double 8字节
4、char类型:2字节
5、Boolean 1字节
二、java字符串编码:默认的是Unicode,当需要改变时,可以String.getBytes。
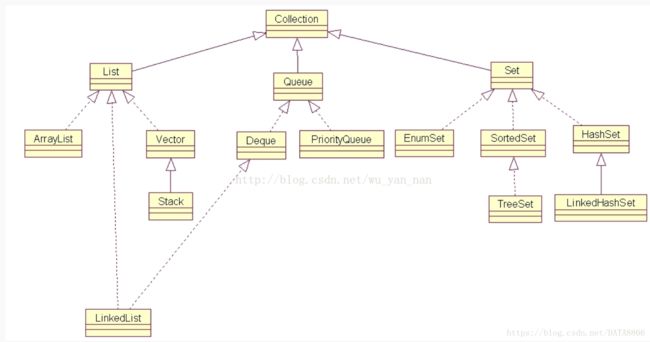
三、集合的关系
四、叙述垃圾回收的两种算法,叙述原理,并说明特点
1、标记清除算法:算法分为标记和清楚两个阶段:首先标记出所需要回收的对象,标记完成后统一回收。标记算法包括引用计数算法和可达性分析算法。特点:效率不高 2. 会产生大量不连续的内存和碎片
2、标记整理算法:和标记清除方法类似,不过在标记之后不是直接回收,而是让所有存活的对象都向一端移动。然后直接清理掉端边界以外的内存。
3、复制算法:将可用内存按容量划分为大小相等的两块,每次只是用一块,当这一块内存用完了,则将还存活的对象复制到另外一块,再把已使用过的内存空间一次清理掉。这样每次都是对整个半区进行内存回收 优点:效率提升,且不用考虑内存碎片问题。缺点,内存缩小了原来的一半
4、分代搜集算法:根据对象的存活周期的不同把内存划分为几块。一般把堆划分为新生代和老年代。然后根据不同代的特点进行收集。新生代采用复制算法,老年带采用标记清理和标记整理算法。
五、HashMap的底层实现,如果是你的话怎么实现。
(这个链接里的内容感觉很不错,可以参考一下)https://www.cnblogs.com/chengxiao/p/6059914.html
六、线程两种实现方式,以及之间的区别,为什么说实现runnable接口方式较好?
1、继承thread类。
这种方式通过自定义直接extend thread,并重写run()方法,就可以激动新线程并执行自己定义的run()方法。
2、实现Runnable接口。
步骤:(1)自定义类并实现Runnable接口。
(2)创建thread对象,用实现Runnable接口的对象作为参数实例化该thread对象。
(3)调用thread的start()方法。
总之:不管是通过继承thread类,还是通过使用Runnable接口来实现多线程的方法,最终还是通过thread的对象的API来控制线程的。
七、java对象序列化
1、Java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够帮助我们实现该功能
2、使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量
3、在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化
4、当某个字段被声明为transient后,默认序列化机制就会忽略该字段。此处将Person类中的age字段声明为transient
八、wait()和sleep()的区别?
wait()和sleep()都是使线程暂停执行一段时间的方法。
1、原理不同。sleep()方法是thread类的静态方法,它使自身暂停,把执行机会让给其他线程,等到计时时间一到就会自动苏醒。wait()方法是object类的方法。
2、对锁的处理机制不同。wait()方法进入等待状态时会释放同步锁,而sleep()方法不会释放同步锁。
3、使用区域不同。wait()必须放在同步控制方法或者同步语句块中,而sleep()方法则可以放在任何地方使用。
九、threadLocal和callable的区别?
ThreadLocal是一个关于创建线程局部变量的类
通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。而使用ThreadLocal创建的变量只能被当前线程访问,其他线程则无法访问和修改
Callable: Callable位于java.util.concurrent包下,它也是一个接口,在它里面也只声明了一个方法,只不过这个方法叫做call(),可以有返回值。
十、死锁和活锁的区别?
- 死锁:当线程A持有互斥锁lock1,线程B当前持有互斥锁lock2.接下来,当线程A仍然持有lock1时,它试图获取lock2,因为线程B正持有lock2,因此线程A会阻塞等待线程B释放。如果此时线程B在持有lock2的时候,也在试图获取lock1,因为线程A正持有lock1,因此B会阻塞等待。二者都在等待对方持有锁的释放,而二者却又都没有释放自己持有的锁。这种情形称为死锁
十二、spring MVC注解问题:前端发一个请求,在后台如何实现?
在使用注解的spring MVC中,处理器Handler是基于@Controller和@RequestMapping这两个注解的,@Controller声明一个处理器类,@RequestMapping声明对应请求的映射关系。
十三、数组存的对象问题、数组排序问题。
十四、程序运行过程中报java.lang.OutOfMempryError:PermGen space是指的什么及其解决方法。
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域OutOfMemoryError: PermGen space从表面上看就是内存益出,也就是方法区,解决方法也一定是加大内存。
十五、解释一下final、finally、finalize三个修饰符。
final:用于声明属性、类、方法,表示属性不可变,类不可被继承,方法不可被覆盖。
finally:作为异常处理的一部分,只能在try/catch语句中,并且附带一个语句块,表示这段语句最终一定被执行。
finalize:它是object类的一个方法,在垃圾回收器执行时会调用被回收对象的finalize()方法。
十六、对象的创建。
当虚拟机检测到new指令时,将会去检测这个指令的参数是否能在常量池定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析、和初始化。如果没有,则去进行以上三步,如果完成了,则虚拟机将为新生对象分配内存空间。
十七、如何区分新生代和老年带?
新生代分为:Eden和survivor,数据会首先分配在Eden中,如果Eden空间不足,则会出发JVM进行GC请求,如果经过一次GC后仍然保留的数据将会从Eden中转移至survivor中,并将其年龄设为1,在survivor中的数据每经历一次GC其年龄就会加1,知道达到一定的年龄就会转移到老年带中(默认的是15)。
大数据相关的问题
一、spark cache和persist的区别。
cache表示把RDD缓存到内存中,采用的级别为:MEMORY_ONLY。
persist()可以手动设置缓存级别。
二、spark缓存机制的几种方法。
1、MEMORY_ONLY:将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,一些分区将不会被缓存,从而在每次需要这些分区时都需重新计算它们。这是系统默认的存储级别。
2、MEMORY_AND_DISK:将RDD作为非序列化的Java对象存储在jvm中。如果RDD不适合存在内存中,将这些不适合存在内存中的分区存储在磁盘中,每次需要时读出它们。
3、MEMORY_ONLY_SER:将RDD作为序列化的Java对象存储(每个分区一个byte数组)。这种方式比非序列化方式更节省空间,特别是用到快速的序列化工具时,但是会更耗费cpu资源—密集的读操作。
4、MEMORY_AND_DISK_SER:和MEMORY_ONLY_SER类似,但不是在每次需要时重复计算这些不适合存储到内存中的分区,而是将这些分区存储到磁盘中。
5、DISK_ONLY:仅仅将RDD分区存储到磁盘中
三、数据清洗的策略及实现方式。
要考虑到一下几个方面:
1、数据的完整性
2、数据的唯一性
3、数据的权威性
4、数据的合法性
5、数据的一致性
要做到让数据更适合做数据挖掘或展示:降维(主成分分析、随机森林)、去冗余(删除字段)、减少无关信息等。
四、yarn-client 和yarn-cluster的区别?
- yarn-cluster 和yarn-client 模式的区别就是application Master进程的区别
- Application Master,在Yarn中,每个Application 实例都有一个Application Master进程,它是Application启动的第一个容器,它负责和ResourceManager打交道,并请求资源,获取资源后告诉NodeManager为其启动container
- yarn-cluster模式下,driver运行在AM中,它负责向Yarn 申请资源,并监督作业的运行情况,当用户提交了作业可以关掉Client,作业会继续进行
- yarn-client ,dirver运行在client上,此时client需要调度exector,所以不能关闭client