mysql 异常情况下的事务安全 -- 详解 mysql redolog
1. 引言
上一篇文章中,我们介绍了 mysql 的二进制日志 binlog,他为数据的同步、恢复和回滚提供了非常便利的支持。
怎么避免从删库到跑路 – 详解 mysql binlog 的配置与使用
无论我们使用的是什么存储引擎,只要通过配置开启,mysql 都会记录 binlog。
在工程存储项目中,有一个重要的概念,那就是 crash safe,即当服务器突然断电或宕机,需要保证已提交的数据或修改不会丢失,未提交的数据能够自动回滚,这就是 mysql ACID 特性中的一个十分重要的特性 – Atomicity 原子性。
根据我们上一篇文章中的讲解,依靠 binlog 是无法保证 crash safe 的,因为 binlog 是事务提交时写入的,如果在 binlog 缓存中的数据持久化到硬盘之前宕机或断电。
在服务器恢复工作后,由于 binlog 缺失一部分已提交的操作数据,而主数据库中实际上这部分操作已经存在,从数据库因此无法同步这部分操作,从而造成主从数据库数据不一致,这是很严重的。
但实际上,innodb 存储引擎是拥有 crash safe 能力的,那么他是用什么机制来实现呢?本文我们就来详细说明。

2. mysql 的执行过程
无论使用任何存储引擎,只要开启相应配置,mysql 都会记录 binlog。
但 MyISAM 引擎并没有提供 crash safe 能力,而 InnoDB 则提供了灾后恢复能力,这是为什么呢?
这和 mysql 整体的分层有关,我们需要首先了解一下一条 sql 语句是如何执行的。

mysql 主要分为两层,与客户端直接交互的是 server 层,包括连接的简历和管理、词法分析、语法分析、执行计划与具体 sql 的选择都是在 server 层中进行的,binlog 就是在 server 层中由 mysql server 实现的。
而 innodb 作为具体的一个存储引擎,他通过 redolog 实现了 crash safe 的支持。
3. redolog 的写入
mysql 有一个基本的技术理念,那就是 WAL,即 Write-Ahead Logging,先写日志,再写磁盘,从而保证每一次操作都有据可查,这里所说的“先写日志”中的日志就包括 innodb 的 redolog。
redolog 与持续向后添加的 binlog 不同,他只占用预先分配的一块固定大小的磁盘空间,在这片空间中,redolog 采用循环写入的方式写入新的数据。
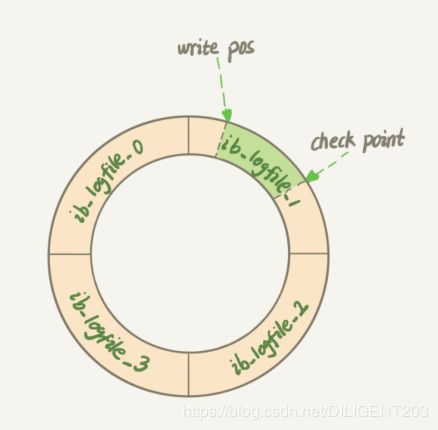
同时,binlog 是以每条操作语句为单位进行记录的,而 redolog 则是以数据页来进行记录的,他记录了每个页上的修改,所以一个事务中可能分多次多条写入 redolog。
4. crash safe 与两阶段提交
每条 redolog 都有两个状态 – prepare 与 commit 状态。
例如对于一张 mysql 表(CREATE TABLE A (ID int(10) unsigned NOT NULL AUTO_INCREMENT, C int(10) NOT NULL DEFAULT 0, PRIMARY KEY (ID)) ENGINE=InnoDB),我们执行一条 SQL 语句:
UPDATE A set C=C+1 WHERE ID=2
实际上,mysql 数据库会进行以下操作(下图中深色的是 mysql server 层所做的操作,浅色部分则是 innodb 存储引擎进行的操作)::
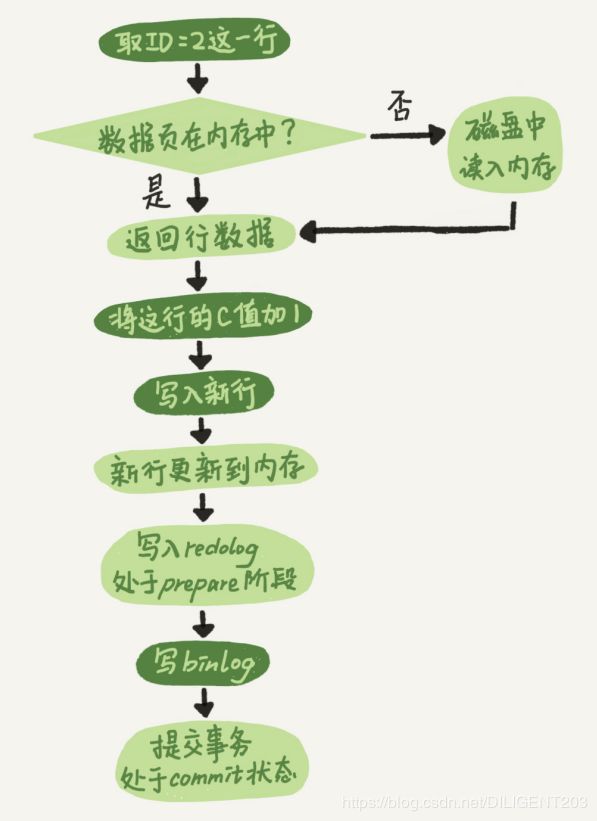
可以看到,在写入 binlog 及事务提交前,innodb 先记录了 redolog,并标记为 prepare 状态,在事务提交后,innodb 会将 redolog 更新为 commit 状态,这样在异常发生时,就可以按照下面两条策略来处理:
- 当异常情况发生时,如果第一次写入 redolog 成功,写入 binlog 失败,MySQL 会当做事务失败直接回滚,保证了后续 redolog 和 binlog 的准确性
- 如果第一次写入 redolog 成功,binlog 也写入成功,当第二次写入 redolog 时候失败了,那数据恢复的过程中,MySQL 判断 redolog 状态为 prepare,且存在对应的 binlog 记录,则会重放事务提交,数据库中会进行相应的修改操作
整个过程是一个典型的两阶段提交过程,由 binlog 充当了协调者的角色,针对每一次日志写入,innodb 都会随之记录一个 8 字节序列号 – LSN(日志逻辑序列号 log sequence number),他会随着日志写入不断单调递增。
binlog、DB 中的数据、redolog 三者就是通过 LSN 关联到一起的,因为数据页上记录了 LSN、日志开始与结束均记录了 LSN、刷盘节点 checkpoint 也记录了 LSN,因此 LSN 成为了整套系统中的全局版本信息。
当异常发生并重新启动后,innodb 会根据出在 prepare 状态的 redo log 记录去查找相同 LSN 的 binlog、数据记录,从而实现异常后的恢复。
5. redo log 的组织
redo log 是以“块”为单位进行存储的,称之为“redo log block”,每个块的大小是 512 字节。
以块为单位存储的原因是他和磁盘扇区的大小是相同的,从而保证在异常情况发生时不会出现部分写入成功产生的脏数据。
6. 相关配置
6.1. innodb_log_file_size
redo log 磁盘空间大小,默认为 5M。
6.2. innodb_log_buffer_size
redo log 缓存大小,默认为 8M。
6.3. innodb_flush_log_at_trx_commit
此前我们曾经介绍过,操作系统为了减少了磁盘的读写次数,提升系统的 IO 性能,会在内存空间中分配一个缓冲区,这就是页面高速缓冲,虽然高速缓冲让 IO 性能得以大幅提升,但在宕机等异常发生时,这部分在高速缓冲区中的数据就会丢失,因此 unix 提供了系统调用 fsync。
来让我们手动执行高速缓冲到磁盘的刷新工作。
对于 redolog 来说,由于他的存在就是为了避免异常情况造成的已提交事务的丢失,所以高速缓冲引起的未刷盘数据丢失是不能容忍的,innodb_flush_log_at_trx_commit 配置项就是指定具体的刷盘策略的。
他有以下值可以选择:
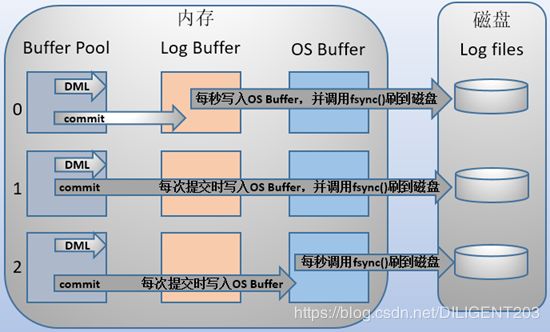
- 0 – 以固定间隔将缓存中的数据写入系统高速缓存并调用一次 fsync 强制刷新高速缓冲,系统崩溃可能丢失最大1秒的数据
- 1 – 默认值,每次事务提交时调用 fsync,这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差
- 2 – 每次事务提交都将数据写入系统高速缓存,但仅在固定间隔调用一次 fsync 强制刷新高速缓冲,安全性高于配置为 0
通常,为了绝对的安全性,我们会配置为 1,但在追求最高的写入性能时,我们通常配置为 2,因为设置为 2 与设置为 0 在性能上差异不大,但配置为 2 却在安全性上高于配置为 0。
同时为了保证 binlog 的安全性,我们同时要配置 sync_binlog 为 1,保证每次 binlog 都直接写入磁盘,而不进行缓存。
6.4. innodb_flush_log_at_timeout
上面提到了刷新告诉缓存的固定间隔,这个“固定间隔”就是通过 innodb_flush_log_at_timeout 配置项指定的,默认是 1 秒。
但实际上,如果 redo log 的缓存占用超过一半,也会立即触发缓冲的刷新。
7. 微信公众号
欢迎关注微信公众号,以技术为主,涉及历史、人文等多领域的学习与感悟,每周三到七篇推文,只有全部原创,只有干货没有鸡汤。

8. 参考资料
https://www.jianshu.com/p/9d98dac77a2b。
https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html。
https://blog.csdn.net/GDUFZXP/article/details/84350363。
https://blog.csdn.net/shaochenshuo/article/details/73239949。