python爬虫实战——青果教务网系统,并用xpath提取成绩
一.分析青果网页
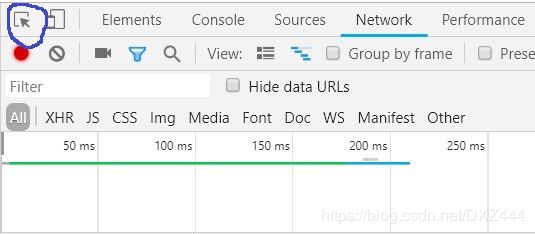
进去教务网登录页面,按F12后点击network,点击页面查看From data如下:
点击这个箭头,然后点击学号后面的白框
![]()
发现学号的属性为txt_dsdsdsdjkjkjc

密码的属性为txt_dsdfdgfouyy,然后输一个错误的密码,之后点击network页面,发现为post请求,查看携带的数据如下

密码对应的为空,但是最后一行有数据,这是把密码加密后数字
查看原网页,发现加密算法如下
function chkpwd(obj)
{
var schoolcode="10623";
var yhm=document.all.txt_dsdsdsdjkjkjc.value;
if(obj.value!="")
{
if(document.all.Sel_Type.value=="ADM")
yhm=yhm.toUpperCase();
var s=md5(yhm+md5(obj.value).substring(0,30).toUpperCase()+schoolcode).substring(0,30).toUpperCase();
document.all.efdfdfuuyyuuckjg.value=s;
}
else
{
document.all.efdfdfuuyyuuckjg.value=obj.value;
}
}将其改写为对应的python代码
def encrypt_paswd(self):
import hashlib
m = hashlib.md5()
m.update(self.password.encode('utf-8'))
password = m.hexdigest()#hexdigest为md5加密
string = self.username + password.upper()[:30] + '10611'
n = hashlib.md5()
n.update(string.encode('utf-8'))
encr = n.hexdigest().upper()[:30]
return encr网页分析就结束了
二.模拟登陆
1.伪装头部信息
让系统认为是人在访问,F12查看requests headers
headers = {'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36"}
2.携带数据
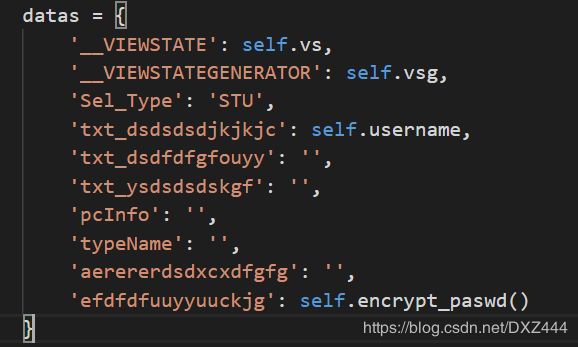
self.encrypt_paswd()为加密密码的函数
self.vs和self.vsg抓包查看后写在初始函数中
3.使用session()来保持登陆状态
s = requests.Session()
res = s.post(url, data=datas, headers=headers)这样就实现了登陆的过程
三.数据抓取(XPath库)
我做的是将课程名和分数爬取后打印出来,其他原理相同。
定位到需要爬取的页面,比如某一科的分数,查看post请求需要的数据和头部信息,与第一步操作原理相同,这里就不重复了。
选中后右键检查,之后右键copy选xpath
//*[@id="ID_Table"]/tbody/tr[2]/td[7]
//*[@id="ID_Table"]/tbody/tr[3]/td[7]
//*[@id="ID_Table"]/tbody/tr[4]/td[7]
#直接复制后为//*[@id="ID_Table"]/tbody/tr[2]/td[7],需要将/tbody去除才能爬取信息,因为浏览器复制会对html文本进行一定的规范化
发现规律为tr[ ]标签处的数字不同,对应着每一科的成绩。
删除/tbody和tr的数字后为//*[@id="ID_Table"]/tr/td[7], 在最后加上/text()即可一次爬取所有科目的成绩存在一个列表中
res = requests.Session.post(scoreUrl,data = datas,headers= headers)
html = etree.HTML(res.text)
score = html.xpath('//*[@id="ID_Table"]/tr/td[7]/text()')
print(score)(记得from lxml import etree导入xpath库,以及这里的datas和headers要为成绩查询页面的,和登陆时的不同,自行抓包查看)