【DataWhale-Spark】2.1-Linux虚拟机部署Spark
在不考虑集群的情况下,有三种部署方式:
1.Window:
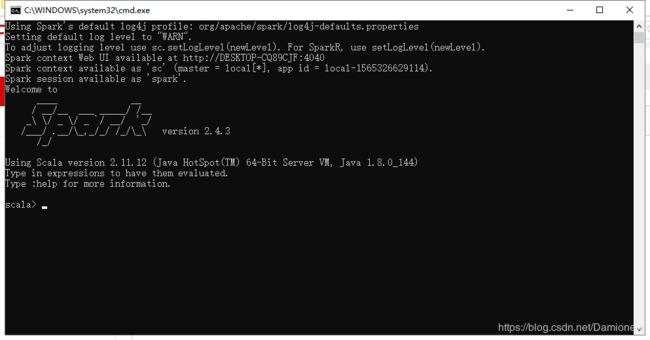
在已安装JDK8+的环境下,只需到Spark官网下载,解压,到bin目录下执行spark-shell.cmd即可运行Spark
2.Linux+Spark:
虚拟机安装Centos镜像,下载安装JDK,如Windows,进入bin目录使用 ./spark-shell
3.Linux+Docker+Centos+Spark
这是我使用的方式,使用Docker方便做集群,且不想创建多个虚拟机
具体操作为:虚拟机安装Centos镜像,安装完成后Linux系统中下载安装Docker,在Docker中运行Centos镜像生成容器,在容器中安装Spark。后续还会安装Hadoop,Scala等
安装详细操作如下
1、虚拟机安装Docker
--安装Docker
yum -y install docker-io
--启动Docker
service docker start
--查看Docker版本
docker -v
--测试hello-world镜像
docker run hello-world
失败。
原因:镜像在国外,网络不稳定,将镜像仓库修改为国内
--修改镜像仓库地址,改为阿里云镜像
vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://pee6w651.mirror.aliyuncs.com"]
}
--Docker仓库生效
sudo systemctl daemon-reload
--Docker重启生效
sudo systemctl restart docker
--测试hello-world镜像
docker run hello-world
成功。
可参考:https://www.jianshu.com/p/ee210190224f
2、Docker运行Centos镜像生成容器
--Linux安装Spark需要安装Centos系统
docker pull centos
--通过镜像创建容器,为保证centos容器一直运行,需加入/bin/bash
docker run -d -i -t --name spark centos /bin/bash
[root@localhost ~]# docker run -it centos /bin/bash
WARNING: IPv4 forwarding is disabled. Networking will not work.
解决:
vi /etc/sysctl.conf
net.ipv4.ip_forward=1
--重启网络
systemctl restart network
[root@bf5eeed38822 /]# systemctl restart network
Failed to get D-Bus connection: Operation not permitted
解决:
容器重启就可以,没有必要如部分博文所说运行时使用/init等命令
docker stop bf5eeed38822
docker start bf5eeed38822
3、容器中安装jdk并安装Spark
--安装JDK
yum install java-1.8.0-openjdk* -y
--spark路径
/usr/local/soft/apache/spark
--下载spark
wget https://www.apache.org/dyn/closer.lua/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
bash: wget: command not found
解决:
sudo yum -y install wget
--解压
tar xvzf spark-2.4.3-bin-hadoop2.7.tgz
gzip: stdin: not in gzip format
解决:
文件不完整,使用国内的源
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
tar xvzf spark-2.4.3-bin-hadoop2.7.tgz
--环境变量添加两个变量
vi ~/.bashrc
--增加两行
export SPARK_HOME=/usr/local/soft/apache/spark/spark-2.4.3-bin-hadoop2.7 export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
--使修改生效
source ~/.bashrc
--查看环境变量是否已配置完成
$PATH
--运行spark
cd spark-2.4.3-bin-hadoop2.7/bin
./spark-shell
至此如上方Windows中图,后续集群会在此基础上部署