Java多线程断点下载功能(可移植Android)
通常在下载文件时,为了加快文件下载速度,除了提高带宽,我们还可以采用多线程的下载方式;如果我们在下载期间,突然关闭了下载功能,等到下一次开启的时候,还是从原先暂停的地方开始下载,不需要重新下载,叫断点再续。所以为了达到这个功能,经过学习完成了Java多线程断点下载功能。
首先,先分析什么是多线程下载,如下图:
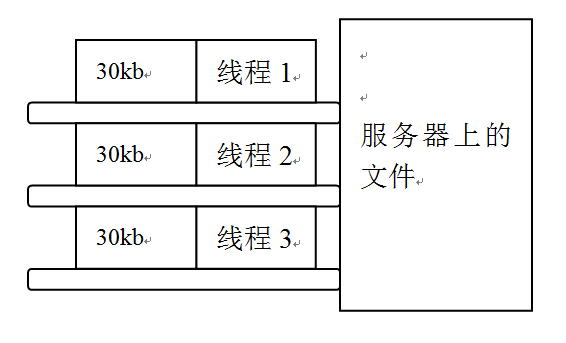
右边矩形代表的服务器上的文件,左边三个线条代表的是三个线程,每个线程下载30kb,同时间打开三个线程下载,比只开一个线程下载的要快,当然最终决定下载速度的还是带宽,你也可以开4个线程5个线程,但是不能无限制的开启,迅雷就是采用的这种多线程下载。相对单一线程要快。
其次,怎样用代码去完成功能,先以图的方式讲解:
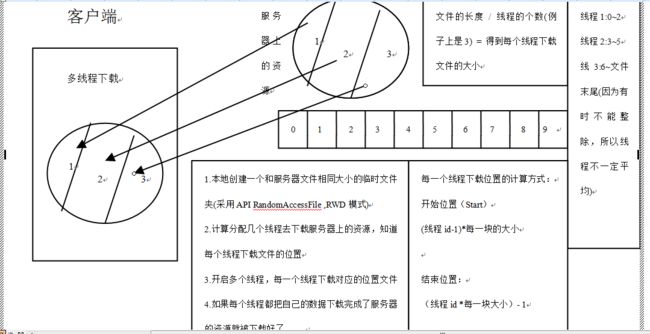
上图详细讲述了怎样用代码去实现,接着就是用代码来实现了:
1 方便起见,使用Tomcat服务器(所以我用的是HTTP协议进行文件的传输),把要下载的文件放在服务器上(我的Tomcat5.0是解压缩的,把下载文件放到Tomcat-->webapps -- >ROOT文件夹下,文件一般是exe文件,测试的时候好测试,因为MP3,jpg,即使下载过程中缺失了内容任然能显示,启动Tomcat的方式很多,上网查阅,我用的是MyEclipse来启动)
2 代码实现:
代码实现,我分为三个方面,首先先写Java下的多线程下载,然后在此基础上改写Java下的多线程断点下载,最后改成Android程序能使用的,简单点说就是移植。
2.1 Java下的多线程下载
注意点 1.RandomAccessFile API 的使用 ;2 请求头信息,向服务器请求资源的时候,请求部分资源,而不是整个资 源(Range头字段设置)
RandomAccessFile API介绍:如下图

以什么模式来进行写入

请求头信息Range字段
conn.setRequestProperty("Range", "bytes=" + startIndex + "-" +endIndex);import java.io.IOException;
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URI;
import java.net.URL;
import javax.xml.ws.http.HTTPBinding;
public class download {
private static int threadcount = 3;
//多线程的下载,通常请求网络的功能写在线程中
public static class downloadmessage implements Runnable{
@Override
public void run() {
// TODO Auto-generated method stub
//链接服务器,并且获得服务器的文件的长度,返回文件的长度
// String path = "http://172.23.235.1:8080/viewer.exe";
String path = "http://219.244.48.140:8080/lantern.exe";
try {
URL url = new URL(path);
try
{
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(5000);
conn.setRequestMethod("GET");
int code = conn.getResponseCode();
//System.out.print(code);
if(code == 200)
{
//获得服务器上的文件的长度
int length = conn.getContentLength();
String lengthtostring = String.valueOf(length);
//在客户端本地创造一个大小和服务器文件一样大的文件
RandomAccessFile rad = new RandomAccessFile("lantern.exe", "rwd");
rad.setLength(length);
rad.close();
//假设是三个线程去下载资源,首先要判断每一线程下载文件的大小
int blocksize = length / threadcount;
//循环开启3个线程
for(int threadId = 1 ; threadId <= threadcount ; threadId ++ ){
//设置每个线程开始下载的位置和终止下载的位置
int startIndex = (threadId - 1) * blocksize;
int endIndex = threadId * blocksize - 1;
//最后一个线程下载剩下的所有
if(threadId == threadcount){
endIndex = length;
}
System.out.print("线程" + threadId + "下载" + startIndex +"------"+endIndex + "\n");
//开启线程的下载
new Thread( new threaddownload(threadId, startIndex, endIndex, path)).start();
}
}
else
{
System.out.print("文件请求出现错误");;
}
}
catch (IOException e)
{
// TODO Auto-generated catch block
System.out.print("链接出现问题");
e.printStackTrace();
}
}
catch (MalformedURLException e)
{
// TODO Auto-generated catch block
System.out.print("url有问题");
e.printStackTrace();
}
}
}
//每个线程下载的内容
public static class threaddownload implements Runnable{
private int threadId;
private int startIndex;
private int endIndex;
private String path;
public threaddownload(int threadId , int start , int end , String path){
this.threadId = threadId;
this.startIndex = start;
this.endIndex = end;
this.path = path;
}
@Override
public void run() {
// TODO Auto-generated method stub
try
{
URL url = new URL(path);
HttpURLConnection conn;
try
{
conn = (HttpURLConnection)url.openConnection();
//非常重要,通过HTTP协议的range头字段,请求服务器
//下载文件的一部分,需要指定文件的位置(从什么位置下载到什么位置)
conn.setRequestProperty("Range", "bytes=" + startIndex + "-" +endIndex);
conn.setRequestMethod("GET");
conn.setReadTimeout(5000);
//code 200 全部资源 206 部分资源 300 资源不存在,400资源没找到,500服务器内部出现错误
int code = conn.getResponseCode();
//System.out.print("code=" + code);
if(code == 206){
//获得服务器的流,获得的流的大小是通过设定的大小,因为前面用到了HTTP头的Range字段
InputStream is = conn.getInputStream();
//随机文件访问类,采用RWD模式()
//(在下载东西的时候,只要文件修改,就把文件同步到底层设备,也就是硬盘里,先存到缓存中,写到底层设备硬盘中)
RandomAccessFile file = new RandomAccessFile("lantern.exe", "rwd");
//随机写文件,从哪个文件开始写
file.seek(startIndex); //定位文件,写文件的开始
int len = 0;
int total = 0; //已经下载的数据长度
byte [] buffer = new byte[1024];
while( (len = is.read(buffer)) != -1){
file.write(buffer,0,len);
total += len;
}
System.out.print("线程" + threadId + "下载完毕" + "\n");
is.close();
file.close();
}
else
{
System.out.print("请求服务器文件失败");
}
}
catch (IOException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}
}
catch (MalformedURLException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public static void main(String ags[]){
download load = new download();
new Thread(new downloadmessage()).start();
}
}
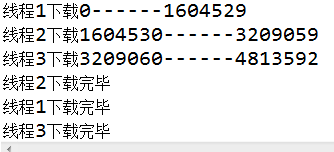
因为没有写具体的下载路径,只是写了下载文件的名字,所以文件最后会默认在本工程目录下生成。多线程下载就完成了,紧接着是多线程断点下载。
2.2 Java的多线程断点下载
断点下载指的是什么?就是你在下载过程中因为外界的因素比如断电,或者你中断了下载,或者暂停了下载,等到下次下载的时候,不需要重新下载而是仅接着上次下载的位置进行下载。
注意点 每次下载之前都需要检测是否已经下载了此文件,如果下载了,得到下载好的位置,从下载好的位置开始,如果没有下载重新开始下载,所以我们必须记录每个线程所下载的文件,以便每次重新下载时获得已经下载好的信息。
需要改的地方 1 记录每个线程下载文件的起始位置(写在文件中,等到下次下载再从文件中读取下载的起始位置,从 这个起始位置继续下载)
2 每次下载前需要检查是否有已经开始下的文件。
3 下载完成后,把每个用来记录文件起始位置的文件删掉(清除记录)
代码就在原先的基础上改就好,其它细节讲解在代码注释上,代码如下:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.RandomAccessFile;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
public class downdotload {
private static int threadcount = 3;
private static int runningThread = 3 ; //正在开启的线程数,例子是3
//多线程的下载,通常请求网络的功能写在线程中
public static class downloadmessage implements Runnable{
@Override
public void run() {
// TODO Auto-generated method stub
//链接服务器,并且获得服务器的文件的长度,返回文件的长度
// String path = "http://172.23.235.1:8080/viewer.exe";
String path = "http://219.244.48.140:8080/Setup.exe";
try {
URL url = new URL(path);
try
{
HttpURLConnection conn = (HttpURLConnection)url.openConnection();
conn.setConnectTimeout(5000);
conn.setRequestMethod("GET");
int code = conn.getResponseCode();
//System.out.print(code);
if(code == 200)
{
//获得服务器上的文件的长度
int length = conn.getContentLength();
String lengthtostring = String.valueOf(length);
//在客户端本地创造一个大小和服务器文件一样大的文件
RandomAccessFile rad = new RandomAccessFile("Setup.exe", "rwd");
rad.setLength(length);
rad.close();
//假设是三个线程去下载资源,首先要判断每一线程下载文件的大小
int blocksize = length / threadcount;
//循环开启3个线程
for(int threadId = 1 ; threadId <= threadcount ; threadId ++ ){
//设置每个线程开始下载的位置和终止下载的位置
int startIndex = (threadId - 1) * blocksize;
int endIndex = threadId * blocksize - 1;
//最后一个线程下载剩下的所有
if(threadId == threadcount){
endIndex = length;
}
System.out.print("线程" + threadId + "下载" + startIndex +"------"+endIndex + "\n");
//开启线程的下载
new Thread( new threaddownload(threadId, startIndex, endIndex, path)).start();
}
}
else
{
System.out.print("文件请求出现错误");;
}
}
catch (IOException e)
{
// TODO Auto-generated catch block
System.out.print("链接出现问题");
e.printStackTrace();
}
}
catch (MalformedURLException e)
{
// TODO Auto-generated catch block
System.out.print("url有问题");
e.printStackTrace();
}
}
}
//每个线程下载的内容
public static class threaddownload implements Runnable{
private int threadId;
private int startIndex;
private int endIndex;
private String path;
public threaddownload(int threadId , int start , int end , String path){
this.threadId = threadId;
this.startIndex = start;
this.endIndex = end;
this.path = path;
}
@Override
public void run() {
// TODO Auto-generated method stub
try
{ //检查是否存在记录下载的文件,如果存在读取文件数据得到长度
File file1 = new File(threadId+".txt");
if(file1.exists() && file1.length() > 0){
try {
FileInputStream fread = new FileInputStream(file1);
byte [] temp = new byte[1024];
try {
int length = fread.read(temp);
String downloadlen = new String(temp,0,length);
int downlen = Integer.parseInt(downloadlen); //获得长度
startIndex = downlen; //修改下载真实的开始位置
fread.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
}
URL url = new URL(path);
HttpURLConnection conn;
try
{
conn = (HttpURLConnection)url.openConnection();
//非常重要,通过HTTP协议的range头字段,请求服务器
//下载文件的一部分,需要指定文件的位置(从什么位置下载到什么位置)
conn.setRequestProperty("Range", "bytes=" + startIndex + "-" +endIndex);
conn.setRequestMethod("GET");
conn.setReadTimeout(5000);
System.out.print("线程" + threadId + "真实开始的下载位置" + startIndex +"---" + endIndex);
//code 200 全部资源 206 部分资源 300 资源不存在,400资源没找到,500服务器内部出现错误
int code = conn.getResponseCode();
//System.out.print("code=" + code);
if(code == 206){
//获得服务器的流,获得的流的大小是通过设定的大小,因为前面用到了HTTP头的Range字段
InputStream is = conn.getInputStream();
//随机文件访问类,采用RWD模式()
//(在下载东西的时候,只要文件修改,就把文件同步到底层设备,也就是硬盘里,先存到缓存中,写到底层设备硬盘中)
RandomAccessFile file = new RandomAccessFile("Setup.exe", "rwd");
//随机写文件,从哪个文件开始写
file.seek(startIndex); //定位文件,写文件的开始
int len = 0;
int total = 0; //已经下载的数据长度
byte [] buffer = new byte[1024];
//这个文件用来记录当前线程下载的数据长度
File filerecord = new File(threadId +".txt");
while( (len = is.read(buffer)) != -1){
//此时写文件的API还是使用RandomAccessFile,如果使用普通的FileOutputSteram会来不及写入
//会出现空的现象(也就是下载了很多,任然记录的长度为0)
//FileOutputStream output = new FileOutputStream(filerecord);
RandomAccessFile output = new RandomAccessFile(threadId+".txt", "rwd");
file.write(buffer,0,len);
total += len;
//记录的是下载的位置
output.write(String.valueOf(total + startIndex + "").getBytes()) ;
output.close();
}
System.out.print("线程" + threadId + "下载完毕" + "\n");
is.close();
file.close();
}
else
{
System.out.print("请求服务器文件失败");
}
}
catch (IOException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}
}
catch (MalformedURLException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
}
//如何去判断应用程序已经下载完毕,然后删除多余的记录长度的文件
finally{
runningThread -- ;
if(runningThread == 0){ //所有线程已经执行完
//删除所有文件
for(int i =1 ; i <= 3 ; i++){
File file = new File(i+".txt");
file.delete();
}
System.out.print("下载完毕,文件清除");
}
}
}
}
public static void main(String ags[]){
downdotload load = new downdotload();
new Thread(new downloadmessage()).start();
}
}
在运行的过程中,如果暂停了,则会在路径下产生跟线程个数一样多的文件,每个文件保存了每个线程下载文件的起始位置,如下图:

每个文件中存储的起始位置
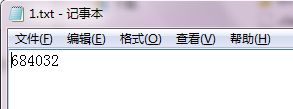
下载完成,如下图:

以上就是关于多线程下载以及多线程断点下载的解释和代码实现,如果有问题或者更好的方法,共同探讨,也希望大家能指出我的不足之处,互相学习。因为此博客篇幅过长,所以关于移植Android的在下次博客中写吧
Java 多线程下载源码地址:http://download.csdn.net/detail/danielntz/9676458
Java多线程断点下载源码地址:http://download.csdn.net/detail/danielntz/9676461
Java API 1.6中文版开发文档:http://download.csdn.net/detail/danielntz/9676457