Python机器学习--训练一个分类器
目录
内容:
情景带入:
使用Python实现线性分类器
内容:
1. 建立机器学习算法的直觉性
2. 使用Numpy, Pandas, Matplotlib读取数据,处理数据,可视化数据.
3. 使用python实现一个线性分类器
情景带入:
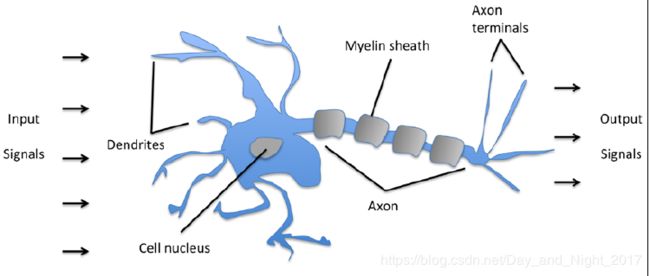
我们将输入的信号与对应的权值进行乘法运算,得到的结果进行加法运算,得到输出结果.通过对比输出结果与阈值的相对大小,对数据进行分类.这就是经典的二分类问题.
我们用w代表权值,x代表输入:
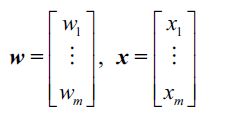
通过上述的步骤计算输出:
![]()
给定阈值,判断类别:

我们对计算的结果进行处理(令X0 = 1 , W0 = -):
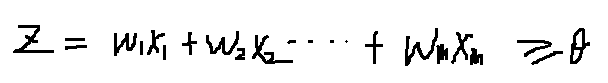
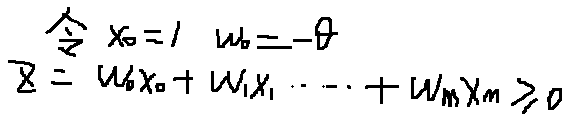
我们得到新的激活函数:
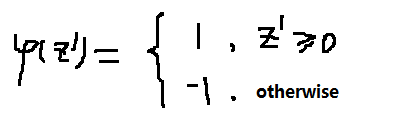
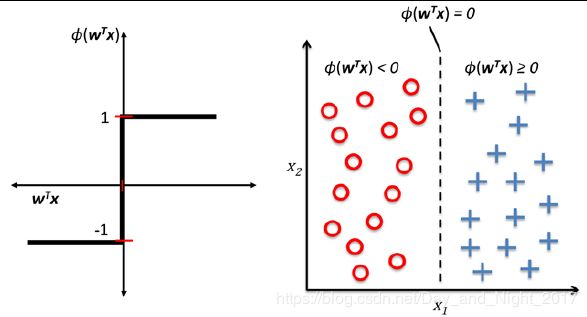
达到分类的效果:
参数更新过程:
1.随机初始化权重
2. 计算每个训练数据对应的输出值, 更新权重.
权重更新公式:

![]() 变化量根据如下公式计算:
变化量根据如下公式计算:
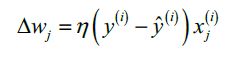
其中,![]() 是学习率,
是学习率, ![]() 是真实值,
是真实值, ![]() 是预测值,
是预测值, ![]() 是输入值
是输入值
需要注意的是, 这里的w的更新,对于同一个训练数据来说,他们的更新是同步的:
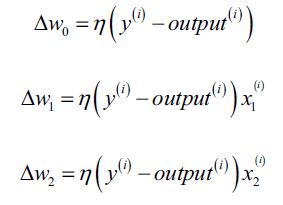
小结:
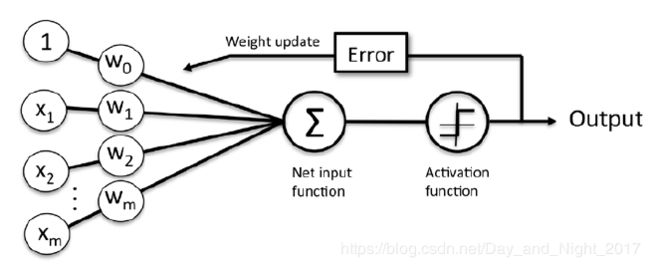
基本过程如下,来一条训练数据后, 会根据对应的权值计算Z输出(权值与输入相乘,结果相加), 再通过激活函数(如单位阶跃函数) 输出类别, 通过计算误差,调整权值,需要注意的是,权值的更新是同步的.
使用Python实现线性分类器
我们的实现方式:将感知器封装成一个类,调用fit函数进行训练, 调用predict函数进行预测.
1.引入numpy包
#引入numpy包, 这个包是处理大型矩阵运算非常好用的一个包, import numpy as np 这里重命名为np了,为了简便
import numpy as np2.定义感知器类
#定义类:
#eta:学习率0.0-1.0
#n_iter:迭代次数
#w_:训练好的权值
#errors_:错误分类的个数
class Perceptron(object):
#定义初始化函数,通过构造器赋值学习率和迭代次数
def _init_(self, eta = 0.1, n_iter = 10):
self.eta = eta
self.n_iter = n_iter
#定义训练函数
def fit(self, X, y):
self.w_ = np.zeros(1 + X.shape[1])
self.errors_ = []
#开始迭代
for _ in range(self.n_iter):
errors = 0
#循环每一条训练数据
for xi, target in zip(X, y):
#计算误差
update = self.eta * (target - self.predict(xi))
#更新权值
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0)
#追加本次迭代样本错误个数
self.errors_.append(errors)
#计算输出
def net_input(self, X):
return np.dot(X, self.w_[1:]) + self.w_[0]
#定义预测函数
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, -1);几个numpy的函数释义:
self.w_ = np.zeros(1 + X.shape[1])
np.zero(n) 将产生n维的向量(矩阵)
np.dot(X, self.w_[1:])
np.dot(A, B) 计算矩阵乘法
np.where(self.net_input(X) >= 0.0, 1, -1);
np.where(A, B, C)三元表达式,A成立结果为B,否则为C
3.在鸢尾花数据集上进行测试
设定:
1. 使用Setosa和Versicolor两类花(因为是二分类)
2. 只考虑sepal length和petal length两个特征
#引入pandas包
import pandas as pd
#读取数据
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header = None)
#检查数据(显示末尾后五条)
df.tail()#引入matplotlib
import matplotlib.pyplot as plt
#将真实的类别信息存入y
y = df.iloc[0:100, 4].values
#将真实值映射到+1,-1
y = np.where(y == 'Iris-setosa', -1, 1)
#将两种特征存入X
X = df.iloc[0:100, [0,2]].values
#绘制数据的二维图表
#获取第一类数据进行绘制(X,Y,颜色,标注,标签)
plt.scatter(X[:50, 0], X[:50, 1], color = 'red', marker = 'o', label = 'setosa')
#获取第二类数据进行绘制(X,Y,颜色,标注,标签)
plt.scatter(X[50:100, 0], X[50:100, 1], color = 'blue', marker = 'x', label = 'versicolor')
#设置x标签
plt.xlabel('petal length')
#设置y标签
plt.ylabel('sepal length')
#设置图例位置
plt.legend(loc = 'upper left')
#开始绘制
plt.show()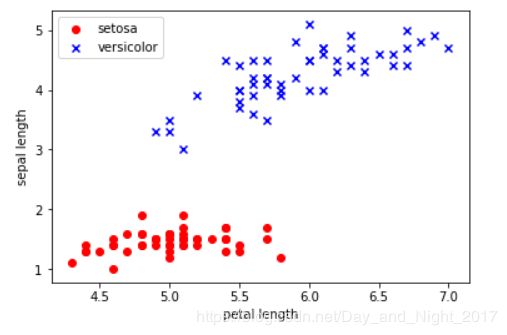
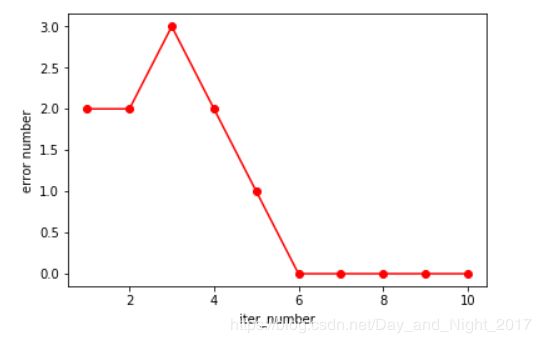
4.开始训练
#开始训练
ppn = Perceptron(eta = 0.1, n_iter = 10)
ppn.fit(X, y)
plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, color = 'red', marker = 'o')
plt.xlabel('iter_number')
plt.ylabel('error number')
plt.show()