字符串算法总结(一)
前言:
字符串是最自然的一种信息的表达方式,所以这方面的题目也会有许多。可以分为两个方面,一方面是求匹配长度,最长子串,回文串之类的,另一方面是字符串 d p dp dp。本文对前者做一些总结。
解决字符串的常用工具:
(1)kmp
(2)Ac自动机
(3)后缀数组
(4)后缀树
(5)后缀自动机
(6)manacher
(7)回文树。
其中 k m p kmp kmp与 A c Ac Ac自动机都不会考裸题,而且一般就是与 d p dp dp相联系,所以本文不讨论。 m a n a c h e r manacher manacher的话,大致上好像都可以用回文树解决,所以就只写回文树。最重要的当然是后缀三兄弟,其中后缀树通常是用后缀自动机建造,后缀数组也可用后缀自动机建造,但很麻烦,所以通常用倍增与 S A I S SAIS SAIS。
后缀数组
后缀数组的基本知识见这里:传送门。
例题
后缀自动机
后缀自动机的主要几个比较重要的性质
1)
后缀自动机的一个节点的 r i g h t right right集合是其在 p a r e n t parent parent树上的儿子的并集,注意这里是指在 p a r e n t parent parent树上的儿子,是指对于一个节点 p p p,对于 l i n k [ q ] = = p link[q]==p link[q]==p的点 q q q才是 p p p的儿子,而不是 t r a n s [ p ] [ ′ a ′ − ′ z ′ ] trans[p]['a'-'z'] trans[p][′a′−′z′]这些转移。
2)
后缀自动机上一个节点存的是一个节点的 m a x l e n maxlen maxlen,就是以这个 r i g h t right right集合的字符串能表示的最长长度。然后如果要知道其能表示的最短长度 m i n l e n minlen minlen,我们有 m i n l e n [ p ] = m a x l e n [ l i n k [ p ] ] + 1 minlen[p] = maxlen[link[p]]+1 minlen[p]=maxlen[link[p]]+1,因为这是 l i n k link link的定义。
3)
如果要知道从一个节点出发能走多少不同的字符串,我们有这两种情况:
(Ⅰ)本质相同的要重复计算
(Ⅱ)本质相同的不重复计算。
那么我们分析一下,我们会发现,对于(Ⅰ)这种情况,每个节点带来的贡献就是其 r i g h t right right集合大小。
而对于(Ⅱ)就是默认这个 r i g h t right right就是 1 1 1。稍微说明一下(Ⅱ)是什么意思,就是相当于说从这个点走到 e n d end end状态有多少种走法,因为我们要求有多少不同的字串,而由于后缀自动机是最简自动机,所以相同的部分会被合并掉。
当然,根据定义,我们还可以得到对于(Ⅱ)还有一种计算方法,就是一个节点 x x x的贡献就是 l e n [ x ] − l e n [ l i n k [ x ] ] len[x] - len[link[x]] len[x]−len[link[x]],原理与后缀数组差不多。
4)
(图片之前的都是鬼扯,之前没明白的时候写的,正确的在下面)
用后缀自动机建造后缀树。这个东西比较鬼畜,最难理解的地方就是说为什么 n q nq nq这个虚拟节点不是一个后缀节点。网上的大部分资料都只是说因为其实虚拟节点,但是还是有些云里雾里的。我这里讲一下为什么。
因为考虑我们怎么构造这个虚拟节点的,就是说相当于在原串 T T T后面加上一个字符 x x x,然后原来的节点的 r i g h t right right集合大小对不上,然后专门新建一个 n q nq nq这个虚拟节点来表示 x x x这个字符转移,所以说,这个节点在后缀树上的边(它父亲连上它的那条边)就是表示 x x x这个字符,所以这个明显不是一个后缀(形象的理解,就是说设原串是 A x B C AxBC AxBC,那么这个虚拟节点表示的就是 B x Bx Bx这个串,所以就不是一个后缀)。
如图:比如串"DDCAACA"
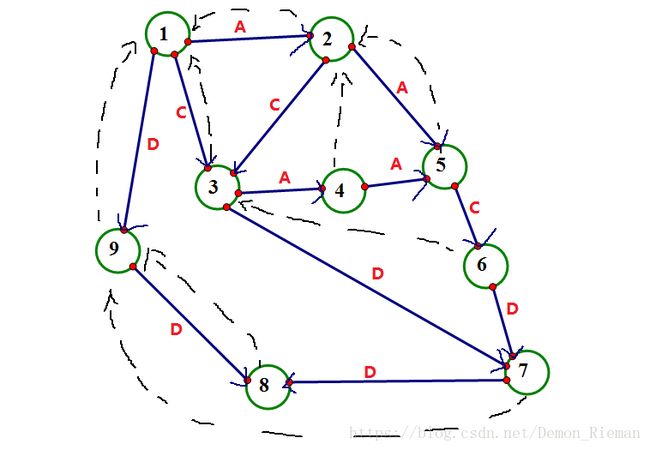
我们可知,其中 9 号 9号 9号节点是虚拟节点。所以其对应的后缀树如下:
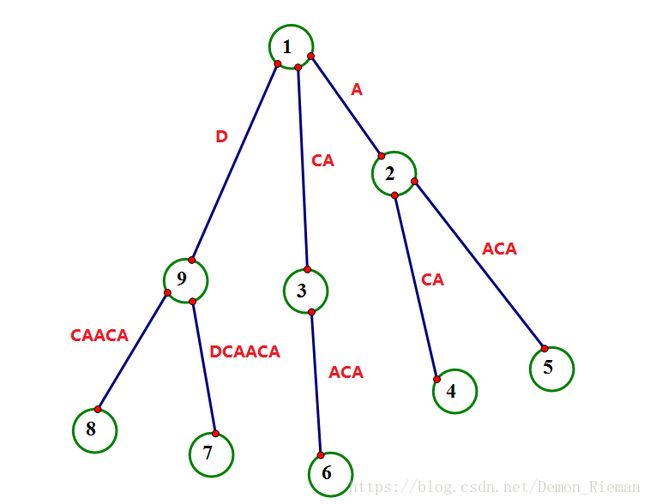
看到了吧,所以 9 号 9号 9号节点不是后缀节点。相当于说这个节点就只是一个子串。
update-2018-12-3
上面关于新建节点的不知道在说什么。
但是对后缀自动机构造不是很明白,现在明白了些。
首先,新增的节点np是一个前缀节点,不是后缀节点。然后虚拟节点是为了保证right集合不出问题而新加入的节点,自然不是前缀节点。
例题
- poj 1509:最小表示法
就是将原串 s s s写两次变成 s s ss ss,然后造出后缀自动机之后贪心的跳 n n n步就是答案。原因是这个最小表示法也肯定是 s s ss ss的字串。如何输出答案有两种方式。一种就是走一步记一步,一种是走到的节点的 l e n len len就是这个字符串的右端点。为什么呢?因为我们将原串重复写了两遍,所以我们可以知道当我们逐渐 e x t e n d extend extend后半部分时候,实际上就是增加了 s [ 1 ] + s s[1]+s s[1]+s, s [ 1 , 2 ] + s s[1,2]+s s[1,2]+s, s [ 1 , 3 ] + s s[1,3]+s s[1,3]+s这些后缀,所以会在共用前面造出来的自动机中表示 s s s的那个节点后面像一条链一样添加,所以此时的这些节点的 r i g h t right right大小为 1 1 1,那么其 l e n len len就是其右端点。
-
××××:求两个字串的最长公共字串
跟 A C AC AC自动机一样,就是暴力匹配。 -
spoj1812:多个串的最长公共字串
类似与上一题,先对第一个串建造后缀自动机,然后对于之后的串你只需要记录一下后缀自动机上的每个节点在之后的串中能匹配的最长位置,然后取一个 m i n min min。比如说二号节点在第 2 , 3 , 4 2,3,4 2,3,4个串中能匹配的最长长度分别是 2 , 3 , 1 2,3,1 2,3,1。所以 2 2 2号节点在所有字符串中就能最多匹配 1 1 1位。
- bzoj 3998:差异
这个就是性质 3 3 3。
- bzoj 4199:品酒大会
先考虑一个显然的性质,也是题上给出的,就是
一对 r r r相似的酒也是 r − 1 , r − 2...0 r-1,r-2...0 r−1,r−2...0相似的。
所以我们对于一对 p , q p,q p,q,只用考虑其能匹配的最远长度,所以说就是后缀 p p p与后缀 q q q的 l c p lcp lcp。这个可以怎么求?
建出后缀树之后, p p p与 q q q的 l c p lcp lcp长度就是其 l c a lca lca的 m a x l e n maxlen maxlen。那么这个我们可以很明显树形 d p dp dp一下,但是就如同之前所说的, n q nq nq节点是不能算贡献的,就是它可以作为后缀节点的 l c a lca lca但是自己不能当作后缀节点。至于第二问,由于有负数权值,所以记一下一个 r r r相似的 m i n min min与 m a x max max值就行了,这个不明白的不多作解释(重点是第一问)。
- bzoj 4560
首先,我们求出匹配的位置。怎么求?就是启发式合并right集合就好了。
然后贪心,枚举一下子串的顺序。这里的顺序是指左端点的顺序。
然后很显然,如果要最大,那么应该使得下一个串左端点刚好在之前最右端点的右边。如果最小,那么应当使得下一个串的左端点刚好在上一个串左端点的右边。
然而这样又 T T T又 W W W。怎么回事?因为启发式合并 r i g h t right right集合空间消耗很大,而且复杂度是 l o g log log的。但是我们注意到,我们只要求 4 4 4个串的 r i g h t right right集合。我们就可以来一点鬼畜的做法:暴力枚举每一个后缀节点,然后判断 l c a lca lca。然后,就过了…
- bzoj 1396:识别字串
好题。题目就是说对于一个字符串 s s s的一个位置 x x x,求一个包含 x x x的字串 T T T使得 T T T在 s s s中只出现一次同时最短。我们考虑后缀自动机上的一个节点会有什么贡献,假设其能表示的范围是 [ m i n l e n , m a x l e n ] [minlen,maxlen] [minlen,maxlen],那么首先这个节点的 r i g h t right right集合大小必须是 1 1 1,不然就不只出现了一次。
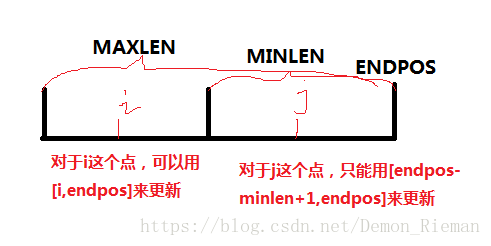
所以这个点表示的串的 e n d p o s endpos endpos是只有一个的,对于 [ e n d p o s − m a x l e n + 1 , e n d p o s − m i n l e n + 1 ] [endpos-maxlen+1,endpos-minlen+1] [endpos−maxlen+1,endpos−minlen+1]这个区间的点 i i i,可以用 [ i − e n d p o s ] [i-endpos] [i−endpos]这个字串来更新答案。
然后对于 [ e n d p o s − m i n l e n + 1 , e n d p o s ] [endpos-minlen+1,endpos] [endpos−minlen+1,endpos]这个部分,可以用 m i n l e n minlen minlen来更新答案。因为对于 [ k , e n d p o s ] [k,endpos] [k,endpos],如果 k > e n d p o s − m i n + 1 k>endpos-min+1 k>endpos−min+1,那么这个串也不只出现了一次。
- bzoj 2342
广义后缀自动机,简单说一下怎么回事。有两种建法。一种是在多个序列上建造自动机,这种自动机的造法很简单,就是每次造一个串时,跳到 r o o t root root。还有一种是在 t r i e trie trie树上,这样子要记一下 l a s t last last,什么意思?就是先在树上 d f s dfs dfs的时候,传参如下
void dfs(int x,int fat,int last)
然后接下来如下
void dfs(int x,int fat,int last)
{
int k=extend(x,last);
dfs(son,x,k);
}
然后之前后缀自动机的时候要把 p p p指针设到 l a s t last last,这样子 l a s t last last就传到后缀自动机中,而不是全局变量。
update-2018.12.3
(上面说的广义后缀自动机不知道在说什么,下面的才是对的)
构建分为离线与在线两种。当然离线复杂度要低一些。现在开始考虑如何构造。
倘若离线构造,应当是采用BFS序,而非DFS序构造。这点应当谨记。传参与之前一样。
倘若在线构造,我们可能遇到的问题是主链上的点可能已经有了,这时候就与之前q的讨论一样。
这里说一下复杂度,离线构造的复杂度达到了理论下界,就是建造trie的复杂度,在线构造复杂度上界则是trie的所有节点深度之和(大部分时候达不到,以致与 O ( n ) O(n) O(n)差不多)。
然而网上大部分代码都是错的,要么在线构造时候没有讨论,离线构造的时候没有按照BFS序,而是按照DFS序。
然而可能是因为数据难以构造,所以那些错误的代码居然都可以通过。
但是为了严谨,我们还是按照正确的方法来。
下面贴一个在线构造的模板:
void extend(int c)
{
int cur = st[last].nex[c] , p ;
if (cur){
if (st[cur].len == st[last].len + 1){
last = cur;
}else{
int clone = ++sz;
st[clone].len = st[last].len + 1;
st[clone].link = st[cur].link;
memcpy(st[clone].nex , st[cur].nex , sizeof st[clone].nex);
st[cur].link = clone;
for (p = last ; p && st[p].next[c] == cur; p = st[p].link) st[p].next[c] = clone;
last = clone;
}
}else{
cur = ++sz;
st[cur].len = st[last].len + 1;
for (p = last; p &&!st[p].next[c]; p=st[p].link) st[p].next[c] = cur;
if ( !p ) st[cur].link = 1;
else
{
int q = st[p].next[c];
if (st[p].len+1==st[q].len) st[cur].link = q;
else
{
int clone = ++sz;
st[clone].len = st[p].len + 1;
st[clone].link = st[q].link;
memcpy(st[clone].next , st[q].next , sizeof (st[clone].next));
for (; p && st[p].next[c]==q; p=st[p].link) st[p].next[c] = clone;
st[q].link = st[cur].link = clone;
}
}
last = cur;
}
}
- bzoj 3926
t r i e trie trie树上的广义自动机。这道题要分析一个性质:
对于一个树上的任意一条路径,都可以将某个子节点转成根,然后该路径就是一条新树上的链,所以此题就很明显了。
- bzoj 4180
真的好题,题解在这里。
后缀自动机与数据结构结合
这个东西是真的毒。因为可以结合的东西很多。
首先,常见的是与 l c t lct lct搞在一起。什么意思?就是动态加入一个字符。然后通过lct维护每个节点的 r i g h t right right集合大小。思路很清晰,明朗。注意,这里我们实际上是要求一个子树和一样的东西。所以要写一个维护子树信息的 l c t lct lct。网上还有一些不用维护子树信息的做法,我还不了解。
例题
- bzoj 2555
就是之前所说的。这里说一些细节。
首先, e x t e n d extend extend的时候,不是有一种情况会把 q q q节点的 f a t h e r father father改变吗?这个怎么实现。我一开始傻逼了,一位很复杂,后来发现,这不就是 c u t cut cut吗?
查询的时候,别忘了把后缀自动机的开始节点设为根。
- bzoj 4516
支持在后面插入字符,询问串中有多少不同的子串。
首先,如我之前所说,一个节点 x x x不同子串就是 l e n [ x ] − l e n [ f a [ x ] ] len[x] - len[fa[x]] len[x]−len[fa[x]],那么很明显就是要维护这个东西。貌似很容易?因为每次最多有 3 3 3对父子关系变化,直接搞就行了。
- bzoj 4545
就是上两题的结合版。
- bzoj 5084
一道 p p t ppt ppt题目。具体的,因为每次新建节点时候,我们最多增加两个新节点。而且我们注意到,他的更新是先跳一段,更新。然后再跳一段。所以我们可以这样:把每步的关键点记下来。然而想了一想发现很难,有很多讨论。后来翻了一下题解,发现一个绝妙的方法:把每次修改的东西放进一个 p a i r pair pair里面,然后就可以直接搞了。
typedef pair<int*,int> pIi;
这是定义。然后,每次需要记录的时候,这样子:
pIi recover[N] ;int tail;
#define push(x) (recover[++tail] = pIi(&x,x), rcnt[now]++)
这样子修改时直接把栈中上一步加进去的部分直接改就行了。因为你记录了加入的指针,就可以直接修改。
回文树:
回文自动机的博客见这里。
例题
- bzoj2342
建出回文树之后,就很简单了, d f s dfs dfs的时候,如果走到过 l e n / 2 len/2 len/2的点,那么就是可行的。