PyTorch学习2—Autograd: 自动微分法
引言
关于这节内容的翻译是真的迷,鉴于我薄弱的英语能力,出现语句不通或语法错误的现象的话,请别太激动…
Autograd
在pytorch中所有关于神经网络的服务都在 autograd 包中。我们先对这个包来一个简单的浏览,然后我们会训练我们第一个神经网络。
autograd 包对所有基于tensors的操作提供了自动微分法。它是一个由运行而定义的框架,这意味着你的反向传播由你代码的运行情况而定义,并且每一个单独的迭代都可以是不同的。
让我们用一些例子来体会这些简单的要点
Variable(变量)
autograd.Variable 是这个包的核心类。它封装了一个tensor,并且支持几乎所有基于这个tensor的操作。当你完成你的计算时,你可以使用 .backward() 然后就可以自动计算所有的梯度了。
你可以通过 .data 属性来使用未处理过的 tensor ,同时关于这个变量的梯度都累积到 .grad 属性。
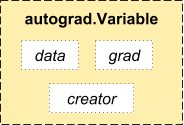
(上图中的creator已经改为 grad_fn )
还有一个非常重要的类—Function
Variable 和 Function 是相互联系的,并且组成了一个无环图,这个图记录了计算机计算的完整历史。每一个变量都有一个 .grad_fn 属性,这个属性参考了创建出了 Variable 的 Function(除了那些用户创建出来的变量,因为那些变量的 grad_fn 是空的)
如果你想计算导数,你可以使用 Variable 的 .backward() 。如果 Variable 是一个标量,你不需要为 backward() 明确指出任何说明,然而如果这个变量有多个元素,你就需要为 grad_output 明确指定来匹配 tensor 的样式。
import torch
from torch.autograd import Variable创建一个变量
x = Variable(torch.ones(2, 2), requires_grad=True)
print(x)输出:
Variable containing:
1 1
1 1
[torch.FloatTensor of size 2x2]对此变量进行一个操作
y = x + 2
print(y)输出:
Variable containing:
3 3
3 3
[torch.FloatTensor of size 2x2]y 是由上面操作创建出的一个变量,因此它有一个 grad_fn 变量
print(y.grad_fn)
#如果这条语句运行不出来,就运行下面的
print(y.creator)
#因为在新版里creator改成了grad_fn输出:
.autograd.function.AddConstantBackward object at 0x2b47f7fdbca8> 下面有更多关于 y 的操作:
z = y * y * 3
out = z.mean()
print(z, out)输出:
Variable containing:
27 27
27 27
[torch.FloatTensor of size 2x2]
Variable containing:
27
[torch.FloatTensor of size 1]Gradients(梯度)
现在 out.backward() 与 out.backward(torch.Tensor([1.0])) 是相等的
out.backward()输出 d(out)/dx 的梯度
print(x.grad)输出:
Variable containing:
4.5000 4.5000
4.5000 4.5000
[torch.FloatTensor of size 2x2]这是一个元素全为4.5的矩阵,4.5的由来如下:

你还可以用autograd做很多疯狂的事!
x = torch.randn(3)
x = Variable(x, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)输出:
Variable containing:
-265.3163
1134.7809
809.5146
[torch.FloatTensor of size 3]gradients = torch.FloatTensor([0.1, 1.0, 0.0001])
y.backward(gradients)
print(x.grad)输出:
Variable containing:
204.8000
2048.0000
0.2048
[torch.FloatTensor of size 3]最后
关于 Variable 和 Function 的文档在这里:Click here
原作者:Sphinx-Gallery