prometheus监控部署使用
这个文档主要学习了fabric设计到的监控系统部署和使用
什么是TSDB
时间序列数据库的特点
大部分时间都是写入操作。
写入操作几乎是顺序添加,大多数时候数据到达后都以时间排序。
写操作很少写入很久之前的数据,也很少更新数据。大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库。
删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据。
基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用。
读操作是十分典型的升序或者降序的顺序读。
高并发的读操作十分常见。
什么是Prometheus?
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等
组件介绍
Prometheus 生态系统包含了几个关键的组件:Prometheus server、Pushgateway、Alertmanager、Web UI 等,其中最核心的组件是 Prometheus server ,它负责收集和存储指标数据,支持表达式查询,和告警的生成。
Prometheus安装方法一:
yum -y install wget gcc-c++
wget https://github.com/prometheus/prometheus/releases/download/v2.12.0/prometheus-2.12.0.linux-amd64.tar.gz
tar xf prometheus-2.12.0.linux-amd64.tar.gz
chown -R root.root prometheus-2.12.0.linux-amd64
mv prometheus-2.12.0.linux-amd64 /usr/local/prometheus
cd /usr/local/prometheus/
./prometheus --config.file=prometheus.yml &S
Prometheus安装方法二:使用 Docker 镜像安装Prometheus server(推荐)
[root@localhost ~]# mkdir prometheus
chmod 777 -R prometheus
vim prometheus.yml
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: []
scheme: http
timeout: 10s
api_version: v1
scrape_configs:
- job_name: prometheus
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- localhost:9090
启动:(一般要指定配置文件,因为后续添加监控节点需要调整)
docker run -d -p 9090:9090 -v /root/prometheus:/etc/prometheus --name prometheus prom/prometheus
#可以通过 docker inspect 命名看看容器在运行时默认的参数
例如:docker inspect prometheus浏览器访问:http://localhost:3000/ 进入Prometheus的登陆页面。

安装grafana
docker run --name grafana -d -p 3000:3000 grafana/Grafana
浏览器访问:http://localhost:3000/ 进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin),第一次登陆会强制要求修改密码。


点击添加数据源:

#要注意的是,这里的 Access 指的是 Grafana 访问数据源的方式,有 Browser 和 Proxy 两种方式。Browser 方式表示当用户访问 Grafana 面板时,浏览器直接通过 URL 访问数据源的;而 Proxy 方式表示浏览器先访问 Grafana 的某个代理接口(接口地址是 /api/datasources/proxy/ ),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。
导入三个仪表盘:
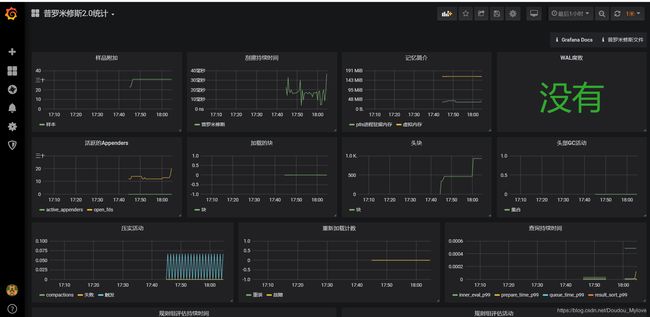
Home位置点击查看刚刚导入的Prometheus2.0酷炫面板:
以docker方式安装 alertmanager(报警)
docker run --name alertmanager -d -p 9093:9093 prom/alertmanager
使用 Exporter 收集指标
node-exporter监控服务器(监控服务器CPU、内存、磁盘、I/O等信息,首先需要安装node_exporter。node_exporter的作用是用于机器系统数据收集)
源码安装exporter(官方推荐)
wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz
tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz
cd node_exporter-0.16.0.linux-amd64
./node_exporter &
docker安装exporter
docker run -d -p 9100:9100 --name node-exporter prom/node-exporter
浏览器访问http://192.168.2.221:9100/metrics/metrics
返回很多指标数据,说明能正常获取服务器指标。
#一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
docker run -d \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
quay.io/prometheus/node-exporter \
--path.rootfs /host
如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到 scrape_configs 中:
vim /root/prometheus/prometheus.yml
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: []
scheme: http
timeout: 10s
api_version: v1
scrape_configs:
- job_name: prometheus
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- localhost:9090
- job_name: 'server'
static_configs:
- targets:
- 192.168.2.221:9100
修改配置后,需要重启 Prometheus 服务,或者发送 HUP 信号也可以让 Prometheus 重新加载配置:
docker restart prometheus
#killall -HUP prometheus
在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器:
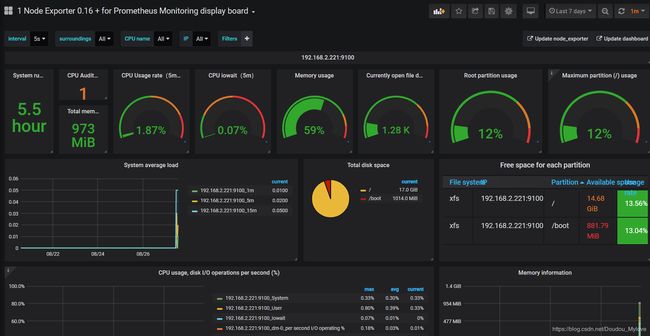
在 Graph 页面的指标下拉框可以看到很多名称以 node 开头的指标,譬如我们输入 node_load1 观察服务器负载:

grafana查看node-exporter监控:
先下载再导入
下载json文件:https://grafana.com/grafana/dashboards

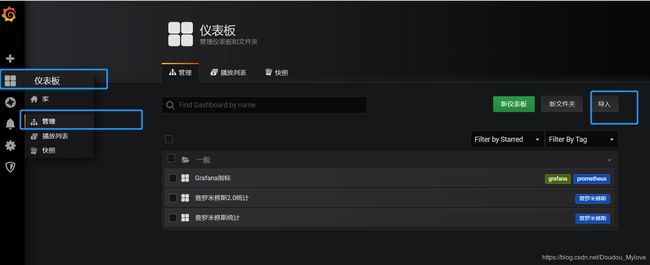



提示插件未安装,解决方法如下:
dockser stop Grafana
改为yum安装:
vim /etc/yum.repos.d/grafana.repo
[grafana]
name=grafana
baseurl=https://packages.grafana.com/oss/rpm
repo_gpgcheck=1
enabled=1
gpgcheck=1
gpgkey=https://packages.grafana.com/gpg.key
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
yum -y install grafana
systemctl start grafana-server
安装插件:
grafana-cli plugins install grafana-piechart-panel
systemctl restart grafana-server
#附加kubernetes应用安装:

