静态网页爬虫
记小白的第一次爬虫经历。
实验环境:Python3.6 IDE :Spyder
需要用到的包:urllib.request(必备),bs4(必备),re,pandas
目标:爬取股吧论坛个股吧(每支股票)第一页帖子内容(股票代码、帖子url、帖子标题、帖子内容),并输出到csv文件
爬虫框架:

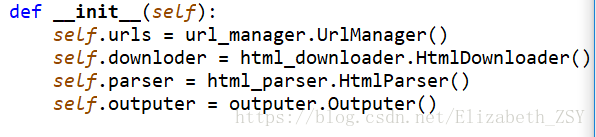
调度器class SpiderMain(object):
创建四个对象(分别为url管理器对象,下载对象,解析对象,输出对象):
爬虫函数def crawl(self, root_url):
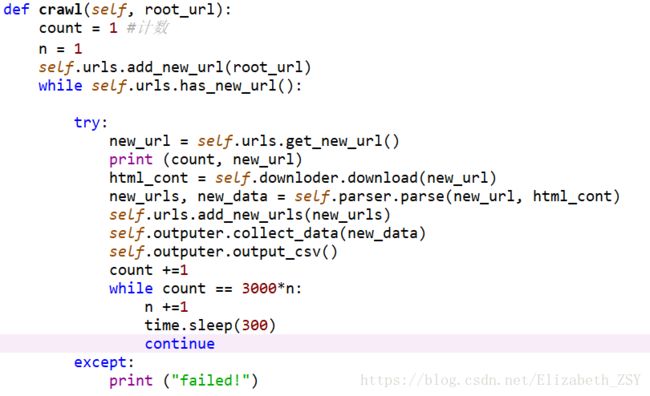
本段代码的主要逻辑很简单,就是从未爬取的url集合中取出一个一个url,下载url页面内容,解析页面内容,输出爬取价值信息内容,并将该url放入已爬取url集合中。
第二个while循环是为了设计没爬3000个url,就暂定停5分钟(本想设置成1个小时,为了测试代码是否有效先设置为五分钟)
主调度程序:
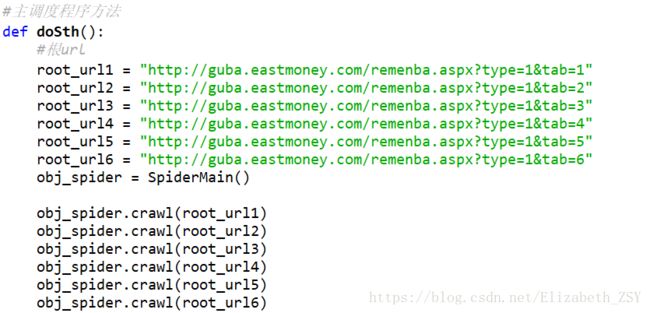
我是写在一个方法里,大家可以直接写在main函数里。
url管理器:
__init__(self):#两个set
add_new_url(self, url):#添加一个url
add_new_urls(self, urls):#添加一簇urls
has_new_url(self):#判断是否有未爬取的url
get_new_url(self):#获取一个未爬取的url,并将其放入已爬取url集合中
下载器:

重点:response = urllib.request.urlopen(url)
解析器class HtmlParser(object):
_get_new_urls(self, page_url, soup)#解析当前页面中的url
_get_new_data(self, page_url, soup)#解析当前页面价值信息(你想要的信息)
parse(self, page_url, html_cont):
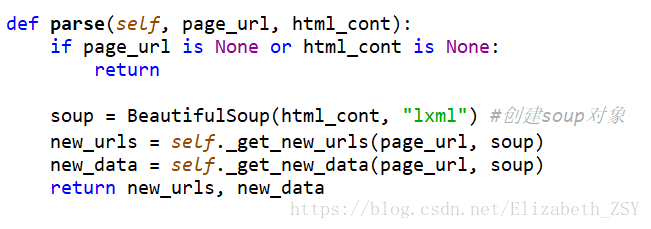
解析页面信息(包括url)需要大家研究所要爬取页面的源代码(右键,审查元素即可)。根据具体情况具体分析。解析时,利用BeautifulSoup创建的对象(上面该对象名为soup)找到所要爬取信息所在节点。大家可以看看BeautifulSoup这边文档,原理和使用方法写的很清楚。https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
输出:
输出就不仔细介绍了,看大家各自的要求。我选择将爬取并存储在字典中的数据,转为DadaFrame型,利用pandas.to_csv()方法写入到csv文件中。这里重点想说的是,大家一定要选用“utf-8”的编码,不然可能出现爬取的文本数据中有无法识别的编码。