问答系统(QA)0
现有的检索系统,无论是受限领域的检索还是互联网搜索引擎,一般都是
基于关键字检索(1.相关答案多2.意图表达差3.语言层,未触及语义层)。
![]()
1、word分词器
2、ansj分词器
3、mmseg4j分词器
4、ik-analyzer分词器
5、jcseg分词器
6、fudannlp分词器[复旦大学]
7、smartcn分词器
8、jieba分词器
9、stanford分词器
10、hanlp分词器
从速度,分词效果,限领域分词效果尚未测试。
词性标注:stanford-postagger中文词性标注较好
语法分析:句法分析是指对自然语言的语法结构进行形式化定义,可以划分为短语结构语法与依存语法。
命名实体识别:命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
问题分类:借助语义词典如WordNet(22) 、HowNet(23)等对问题上下位词、同义词进行扩充。问题分类主要有 基于模式规则匹配的方法和基于统计学习的方法,其中机器学习的方法占据主导。基于模式匹配优点是无需语料库,也没有人工标注的错误率和工作量,同时还可以保证不错的效果。但由于中文表述形式的灵活性,许多问句甚至不含疑问词,所以规则方法适用性不强。
在中文领域:
1. 一种特征提取的新方法,此方法依赖于句法分析结果,通过把主干词和疑问词及其附属成分作为BN 的特征输入。
2. 用HowNet 语义词典,把疑问句、句法结构、疑问意向词在知网中的首义原作为特征输入, 采用EM 分类器。
3. 提取问题疑问词、关键核心词的主要义原、核心关键词的首义原、问句主谓宾的主要义原、命名实体、名词单复数等六种特征,采用SVM 分类器对事实疑问句进行不同特征组合的分类对比。
问题扩展:目前有两种主流的方式,一是通过搜索引擎等外部文本扩展,或者借助知识库如WordNet或Wikipedia等, 挖掘词之间的内在联系。
问题在经过上面的处理过后,如何表示?
问题解析过程在基于知识库的问答系统中尤为重要,其主流方法有两类,一类是基于符号的表示方法,另一类基于深度学习的分布式表示方法。
基于符号的表示方法把问题问句表示为形式化的查询形式, 如逻辑表达式、Lambda、 Calculus、DCS-TREE或Fun-QL等形式,之后再转化为对应的查询语言如SQL、SPARQL、Prolog、FunQL等。
信息检索:信息检索则以问题解析模块的结果作为输入,从底层知识库中返回一系列相关的排序文档。检索常用的模型有布尔模型、向量空间模型以及概率模型。
1. 布尔模型是一种简单检索模型,基于集合论和布尔代数。其查询由联接符AND、OR 和NOT 构成,通过对每个关键词对应的倒排索引取交集、并集或补集,返回若干相关文档给用户。
举例:下面有2个文档:
文档1:a b c f g h;
文档2:a f b x y z;
用户想找出出现a或者b但一定要出现z的文档(三元组)。当然我们仔细一看,结果显而易见是文档2符合用户的需求。但是对于计算机布尔排序模型它是怎么实现的呢 ?将查询表示为布尔表达式Q=(a∨b)∧z,并转换成析取范式qDNF=(1,0,1)∨(0,1,1)∨(1,1,1)(三元组);文档1和文档2的三元组对应值分别为(1,1,0)和(1,1,1);经过匹配,将文档2返回;
布尔模型的优点:通过使用复杂的布尔表达式,可以很方便地控制查询结果;
布尔模型问题:1.不支持部分匹配,而完全匹配会导致太多或者太少的,非常刚性:“与”意味着全部;“或”意味着任何一个;2.很难控制被检索的文档数量原则上讲,所有被匹配的文档都将被返回;3.很难对输出进行排序;
2. 向量空间模型是现在的文本检索系统以及网络搜索引擎的基础, 它把文档以及用户的查询都表示成向量空间中的点,用它们之间夹角的余弦值作为相似性度量。
举例:若文档有K 个词, 表示K个词在文档j中的权重。假设文档集合大小为N,fij为词i在某篇文档j中的次数。
表示K个词在文档j中的权重。假设文档集合大小为N,fij为词i在某篇文档j中的次数。
原理:R:相关文档集NR:不相关文档集q:用户查询dj:文档j
PRP(probability ranking principle):概率排序原理,利用概率模型来估计每篇文档和需求相关概率,然后对结果进行排序。
贝叶斯最优决策原理,基于最小损失风险作出决策,返回相关的可能性大于不相关的可能性的文档;
条件概率的公式:P(AB)=P(A)P(B|A)=P(B)P(A|B)
![]() 答案抽取:
答案抽取:
1) 模式匹配:例如问句"姚明出生于什么地方",其答案通常为"姚明出身于上海",则
其答案模式可设置为" <人物〉出生于〈地点>"。
2) 关系预定义:关系抽取的一种有效的实现方式是将句子转换为由主语、谓语、宾语构成的三元组形式,然后从中抽取答案。
![]()
![]()
Frequently Asked Questions,FAQ,即通过提取问题特征进行相似度计算来返回排序后的答案,
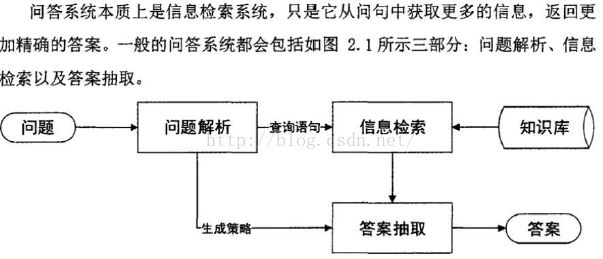
问题解析:主要包括分词、词性标注、句法分析、命名实体识别、问题分类、问题扩展等。
分词:中英文分词存在很大的区别,英文单词之间是以空格作为自然分界符的,而中文是以字为基本的书写单位,词语之间没有明显的区分标记。 分词中最常见的是基于规则的词典匹配的方法,当出现歧义分词时,也有最大切分(向前、向后、前后结合)、最少切分、全切分等策略,但都存在一定不足。在受限领域的分词,都需要构造自身的领域词典, 来提高分词的准确率。1、word分词器
2、ansj分词器
3、mmseg4j分词器
4、ik-analyzer分词器
5、jcseg分词器
6、fudannlp分词器[复旦大学]
7、smartcn分词器
8、jieba分词器
9、stanford分词器
10、hanlp分词器
从速度,分词效果,限领域分词效果尚未测试。
词性标注:stanford-postagger中文词性标注较好
语法分析:句法分析是指对自然语言的语法结构进行形式化定义,可以划分为短语结构语法与依存语法。
命名实体识别:命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
问题分类:借助语义词典如WordNet(22) 、HowNet(23)等对问题上下位词、同义词进行扩充。问题分类主要有 基于模式规则匹配的方法和基于统计学习的方法,其中机器学习的方法占据主导。基于模式匹配优点是无需语料库,也没有人工标注的错误率和工作量,同时还可以保证不错的效果。但由于中文表述形式的灵活性,许多问句甚至不含疑问词,所以规则方法适用性不强。
在中文领域:
1. 一种特征提取的新方法,此方法依赖于句法分析结果,通过把主干词和疑问词及其附属成分作为BN 的特征输入。
2. 用HowNet 语义词典,把疑问句、句法结构、疑问意向词在知网中的首义原作为特征输入, 采用EM 分类器。
3. 提取问题疑问词、关键核心词的主要义原、核心关键词的首义原、问句主谓宾的主要义原、命名实体、名词单复数等六种特征,采用SVM 分类器对事实疑问句进行不同特征组合的分类对比。
问题扩展:目前有两种主流的方式,一是通过搜索引擎等外部文本扩展,或者借助知识库如WordNet或Wikipedia等, 挖掘词之间的内在联系。
问题在经过上面的处理过后,如何表示?
问题解析过程在基于知识库的问答系统中尤为重要,其主流方法有两类,一类是基于符号的表示方法,另一类基于深度学习的分布式表示方法。
基于符号的表示方法把问题问句表示为形式化的查询形式, 如逻辑表达式、Lambda、 Calculus、DCS-TREE或Fun-QL等形式,之后再转化为对应的查询语言如SQL、SPARQL、Prolog、FunQL等。
信息检索:信息检索则以问题解析模块的结果作为输入,从底层知识库中返回一系列相关的排序文档。检索常用的模型有布尔模型、向量空间模型以及概率模型。
1. 布尔模型是一种简单检索模型,基于集合论和布尔代数。其查询由联接符AND、OR 和NOT 构成,通过对每个关键词对应的倒排索引取交集、并集或补集,返回若干相关文档给用户。
举例:下面有2个文档:
文档1:a b c f g h;
文档2:a f b x y z;
用户想找出出现a或者b但一定要出现z的文档(三元组)。当然我们仔细一看,结果显而易见是文档2符合用户的需求。但是对于计算机布尔排序模型它是怎么实现的呢 ?将查询表示为布尔表达式Q=(a∨b)∧z,并转换成析取范式qDNF=(1,0,1)∨(0,1,1)∨(1,1,1)(三元组);文档1和文档2的三元组对应值分别为(1,1,0)和(1,1,1);经过匹配,将文档2返回;
布尔模型的优点:通过使用复杂的布尔表达式,可以很方便地控制查询结果;
布尔模型问题:1.不支持部分匹配,而完全匹配会导致太多或者太少的,非常刚性:“与”意味着全部;“或”意味着任何一个;2.很难控制被检索的文档数量原则上讲,所有被匹配的文档都将被返回;3.很难对输出进行排序;
2. 向量空间模型是现在的文本检索系统以及网络搜索引擎的基础, 它把文档以及用户的查询都表示成向量空间中的点,用它们之间夹角的余弦值作为相似性度量。
举例:若文档有K 个词,



原理:R:相关文档集NR:不相关文档集q:用户查询dj:文档j
PRP(probability ranking principle):概率排序原理,利用概率模型来估计每篇文档和需求相关概率,然后对结果进行排序。
贝叶斯最优决策原理,基于最小损失风险作出决策,返回相关的可能性大于不相关的可能性的文档;
条件概率的公式:P(AB)=P(A)P(B|A)=P(B)P(A|B)
由条件概率公式推导出贝叶斯公式:P(B|A)=P(A|B)P(B)/P(A)

1) 模式匹配:例如问句"姚明出生于什么地方",其答案通常为"姚明出身于上海",则
其答案模式可设置为" <人物〉出生于〈地点>"。
2) 关系预定义:关系抽取的一种有效的实现方式是将句子转换为由主语、谓语、宾语构成的三元组形式,然后从中抽取答案。
3) 语义相似度:对于两个词W1和W2,定义其相似度为sim(W1, W2),其词距为dis(W1, W2),α为一个可调参数,则有
![]()
定义两个句子a和b,其中a 包含a1、a2、a3 、……、am 共m 个词, b 包含b1、b2、b3、……、加共n 个词,定义词间相似度为sim(ai, bj),则任意两个词相似度:
