最近闲来无事,想研究下图片识别,经过一番搜索,决定研究研究tesseract
首先是一些基础概念
- OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
- Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。当前版本为3.01.
首先介绍windows中使用命令行来使用Tesseract
- 下载安装Tesseract-OCR引擎(3.0版本+才支持中文识别) 下载链接 tesseract-ocr-setup-3.02.02
- 下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。如果想能识别中文,可以到https://github.com/tesseract-ocr/tessdata下载对应的语言的字库文件.
- 使用Tessract-OCR引擎识别验证码
打开DOS界面,输入tesseract,出现下图证明成功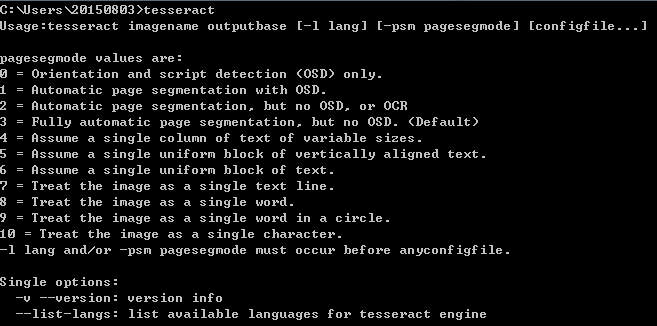
- 我准备了一张验证码code.png
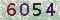 放在D盘根目录下的test文件夹下,上图:
放在D盘根目录下的test文件夹下,上图:

查看result.txt中解析结果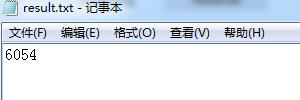 解析成功
解析成功 - 那对中文的解析如何,准备一张中文图片
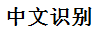
,在上述github上下载对应的中文语言库文件,键入命令 tesseract zhongwen.png result -l chi_sim,显示指定语言为中文,然后会发现控制台输出read_params_file: parameter not found: allow_blob_division,这是由于我们使用的版本是3.02,而github最新的资源版本已经是3.04了,这边我们下载个3.02版本下的中文简体字体就可以了,传送门http://download.csdn.net/detail/u011538446/9439080替换后执行结果为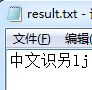 识别准确率还是可以的,毕竟我们还可以通过训练提高识别的准群率
识别准确率还是可以的,毕竟我们还可以通过训练提高识别的准群率 - 附录:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
-
多数情况下,我们需要在程序中动态的调用,这边我们以java为例,演示如何在java中动态调用tesseract进行图像识别,我们在代码中识别下述的图片

下面是核心代码package com.layou; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.List; import org.jdesktop.swingx.util.OS; public class OCRHelper { private final String LANG_OPTION = "-l"; private final String EOL = System.getProperty("line.separator"); private String tessPath = "D://Program Files (x86)//Tesseract-OCR"; /** * @param imageFile * 传入的图像文件 * @param imageFormat * 传入的图像格式 * @return 识别后的字符串 */ public String recognizeText(File imageFile) throws Exception { /** * 设置输出文件的保存的文件目录 */ File outputFile = new File(imageFile.getParentFile(), "output"); StringBuffer strB = new StringBuffer(); Listcmd = new ArrayList (); if (OS.isWindowsXP()) { cmd.add(tessPath + "\\tesseract"); } else if (OS.isLinux()) { cmd.add("tesseract"); } else { cmd.add(tessPath + "\\tesseract"); } cmd.add(""); cmd.add(outputFile.getName()); cmd.add(LANG_OPTION); // cmd.add("chi_sim"); cmd.add("eng"); ProcessBuilder pb = new ProcessBuilder(); /** * Sets this process builder's working directory. */ pb.directory(imageFile.getParentFile()); cmd.set(1, imageFile.getName()); pb.command(cmd); pb.redirectErrorStream(true); Process process = pb.start(); // tesseract.exe 1.jpg 1 -l chi_sim // Runtime.getRuntime().exec("tesseract.exe 1.jpg 1 -l chi_sim"); /** * the exit value of the process. By convention, 0 indicates normal * termination. */ // System.out.println(cmd.toString()); int w = process.waitFor(); if (w == 0) // 0代表正常退出 { BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream(outputFile.getAbsolutePath() + ".txt"), "UTF-8")); String str; while ((str = in.readLine()) != null) { strB.append(str).append(EOL); } in.close(); } else { String msg; switch (w) { case 1: msg = "Errors accessing files. There may be spaces in your image's filename."; break; case 29: msg = "Cannot recognize the image or its selected region."; break; case 31: msg = "Unsupported image format."; break; default: msg = "Errors occurred."; } throw new RuntimeException(msg); } new File(outputFile.getAbsolutePath() + ".txt").delete(); return strB.toString().replaceAll("\\s*", ""); } }
运行结果如下package com.layou; import java.io.File; public class Test { public static void main(String[] args) { try { File testDataDir = new File("D://test"); System.out.println(testDataDir.listFiles().length); int i = 0; for (int j=0; j<24; j++) { i++; String recognizeText = new OCRHelper().recognizeText(new File("D://test/code" + j + ".jpg")); System.out.print(recognizeText + "\t"); if (i % 8 == 0) { System.out.println(); } } } catch (Exception e) { e.printStackTrace(); } } }

运行结果还是相当令人满意的 -
当然了,有时候图片被扭曲或者模糊的很厉害,很不容易识别,所以下面我给大家介绍一个去噪的辅助类,绝对碉堡了,先看下效果图。

一个类,不依赖任何jar,把图像中的干扰线消灭了,是不是很给力,然后再拿这样的图片去识别,会不会效果更好呢,嘿嘿,大家自己实验~
package com.layou; import java.awt.Color; import java.awt.image.BufferedImage; import java.io.File; import java.io.IOException; import javax.imageio.ImageIO; public class ClearImageHelper { public static void main(String[] args) throws IOException { File testDataDir = new File("d://test"); final String destDir = testDataDir.getAbsolutePath() + "/tmp"; for (File file : testDataDir.listFiles()) { cleanImage(file, destDir); } } /** * * @param sfile * 需要去噪的图像 * @param destDir * 去噪后的图像保存地址 * @throws IOException */ public static void cleanImage(File sfile, String destDir) throws IOException { File destF = new File(destDir); if (!destF.exists()) { destF.mkdirs(); } BufferedImage bufferedImage = ImageIO.read(sfile); int h = bufferedImage.getHeight(); int w = bufferedImage.getWidth(); // 灰度化 int[][] gray = new int[w][h]; for (int x = 0; x < w; x++) { for (int y = 0; y < h; y++) { int argb = bufferedImage.getRGB(x, y); // 图像加亮(调整亮度识别率非常高) int r = (int) (((argb >> 16) & 0xFF) * 1.1 + 30); int g = (int) (((argb >> 8) & 0xFF) * 1.1 + 30); int b = (int) (((argb >> 0) & 0xFF) * 1.1 + 30); if (r >= 255) { r = 255; } if (g >= 255) { g = 255; } if (b >= 255) { b = 255; } gray[x][y] = (int) Math.pow((Math.pow(r, 2.2) * 0.2973 + Math.pow(g, 2.2) * 0.6274 + Math.pow(b, 2.2) * 0.0753), 1 / 2.2); } } // 二值化 int threshold = ostu(gray, w, h); BufferedImage binaryBufferedImage = new BufferedImage(w, h, BufferedImage.TYPE_BYTE_BINARY); for (int x = 0; x < w; x++) { for (int y = 0; y < h; y++) { if (gray[x][y] > threshold) { gray[x][y] |= 0x00FFFF; } else { gray[x][y] &= 0xFF0000; } binaryBufferedImage.setRGB(x, y, gray[x][y]); } } // 矩阵打印 for (int y = 0; y < h; y++) { for (int x = 0; x < w; x++) { if (isBlack(binaryBufferedImage.getRGB(x, y))) { System.out.print("*"); } else { System.out.print(" "); } } System.out.println(); } ImageIO.write(binaryBufferedImage, "jpg", new File(destDir, sfile.getName())); } public static boolean isBlack(int colorInt) { Color color = new Color(colorInt); if (color.getRed() + color.getGreen() + color.getBlue() <= 300) { return true; } return false; } public static boolean isWhite(int colorInt) { Color color = new Color(colorInt); if (color.getRed() + color.getGreen() + color.getBlue() > 300) { return true; } return false; } public static int isBlackOrWhite(int colorInt) { if (getColorBright(colorInt) < 30 || getColorBright(colorInt) > 730) { return 1; } return 0; } public static int getColorBright(int colorInt) { Color color = new Color(colorInt); return color.getRed() + color.getGreen() + color.getBlue(); } public static int ostu(int[][] gray, int w, int h) { int[] histData = new int[w * h]; // Calculate histogram for (int x = 0; x < w; x++) { for (int y = 0; y < h; y++) { int red = 0xFF & gray[x][y]; histData[red]++; } } // Total number of pixels int total = w * h; float sum = 0; for (int t = 0; t < 256; t++) sum += t * histData[t]; float sumB = 0; int wB = 0; int wF = 0; float varMax = 0; int threshold = 0; for (int t = 0; t < 256; t++) { wB += histData[t]; // Weight Background if (wB == 0) continue; wF = total - wB; // Weight Foreground if (wF == 0) break; sumB += (float) (t * histData[t]); float mB = sumB / wB; // Mean Background float mF = (sum - sumB) / wF; // Mean Foreground // Calculate Between Class Variance float varBetween = (float) wB * (float) wF * (mB - mF) * (mB - mF); // Check if new maximum found if (varBetween > varMax) { varMax = varBetween; threshold = t; } } return threshold; } }好拉,初步研究就到这边了,后期项目如果使用到的话,在深入研究吧,java部分参考http://blog.csdn.net/lmj623565791/article/details/23960391