准确率(accuracy),精确度(precision),召回率(recall) ——评价标准学习 part1
在学习机器学习算法过程中,在学习评价标准(accuracy, precision, recall)内容的时候,记录一下自己遇到的问题。
在网上查找准确率,召回率,一般会发现两套描述。一套是对于信息检索的,一套是对于分类问题的。
一、 信息检索问题
Recall 查全率,也叫召回率,通用。
Precision 查准率,(强调,这里记汉语容易弄错,记英文词不会错。我查到的资料是,在信息检索领域中,查准率也叫准确率;而在分类领域中,查准率叫精确率)
信息检索中概念公式:
查全率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数
查准率(Precision)= 系统检索到的相关文件 / 系统所有检索到的文件总数
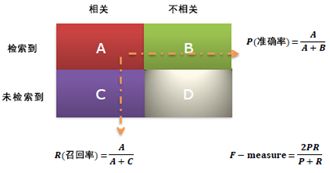
例子
假如某个班 全部 男生80人,女生20人,共计100人。
目标是找出所有女生。
现在 挑出50人,其中20人是女生(对),其他30个人是男生(错)
这个问题中,
目的是找寻女生, 因此相关就是总女生20人,不相关就是总男生80人。
挑出来的即检索挑出到的, 挑出的相关(对)女生20人,挑出的不相关(错)是男生30人
未挑出来的即检索未挑出, 未挑出相关 0 人 ,未挑出的不相关是 男生50人
(TP 正类,检测正确T,检测到 P ), ( FP 负类,检测错误F,检测到 P )
(FN 正类,检测错误F,未检测到N ), ( TN 负类,检测正确T,未检测到 N )
【------------------附加一段,可忽略
一直对这个符号记法纠结不已,检索到未检索到 是直观量
相关的不相关的 是直观量
检测对检测不对 是间接量
我觉得采用图示记忆法,按照混淆矩阵的位置
检索到(相关)、 检索到(不相关)
未检索到(相关)、未检索到(不相关)
记号采用任意对应的字母如 UL检索到(相关) UR
DL DR
每行每列只变一个因素,看起来更对称,更有美感。不过流传的是这种记法了,也就接受吧。
-----------------------------------------------------------------------------------】
言归正传,分为两部分记忆,前面的部分是True/False,表示检测正确还是错误,后面的部分是positive/negative,表示相关还是不相关。
查准率P是: 结果正确的 检测到的 / 实际检测到的
是: 结果正确的 检测到的 / (结果正确的 检测到的+ 结果错误的检测到的)
是: 20/50=40%
召回率R是: 结果正确的 检测到的 / 应该检测到的( 女生 )
是: 结果正确的 检测到的 / (正确的,即检测到的女生+ 错误的,即未检测到的女生)
是: 20/20=100%
F1-measure = 2PR/(P+R)=2X0.4/1.4=57.143%
用符号公式表示为:
准确率P = TP / ( TP+FP )
召回率R = TP / ( TP+FN )
二、信息检索问题
分类领域中,评价标准有准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure。 Precision也叫查准率,Recall也叫查全率。
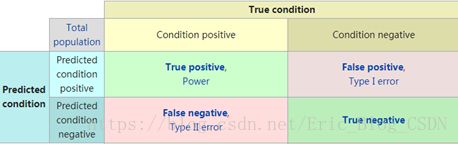
分类问题中,
目的是找寻A类, 因此实际正类就是A类,实际负类就是B类。
预测到的即判定的A, 判定A(对)实际是A类,判定B(错)实际是B类
未预测的即判定的B, 判定B(错)实际是A类,判定B(对)实际是B类
(TP 正类,判定正确T,判定正类 P ), ( FP 负类,判定错误F,判定正类 P )
(FN 正类,判定错误F,判定B类N ), ( TN 负类,判定正确T,判定负类 N )
或者这样
true positives(TP 正类判定为正类), false positives(FP 负类判定为正类)
false negatives(FN 正类判定为负类),true negatives(TN 负类判定为负类
准确率A是: 结果正确的(判定结果=真实结果) / 全部个数
是: (结果正确的 判定正类 正类+ 结果正确的 判定负类 负类) / 全部个数
是:70//100 = 70%
精确率P是: 结果正确的 判定正类 / 判定正类的
是: 结果正确的 判定正类 / (结果正确的 判定正类+ 结果错误的判定正类)
是: 20/50=40%
召回率R是: 结果正确的 判定正类 / 应该找到的 正类
是: 结果正确的 判定正类 / (正确的,判定正类,正类+ 错误的,判定负类,正类) (头晕)
是: 20/20=100%
用符号公式表示为:
准确率 A = (TP+TN) / (TP+TN+FP+FN)
精确率 P = TP / ( TP+FP )
召回率 R = TP / ( TP+FN )
F1-measure = 2PR/(P+R)
总结
可以发现两种表述其实意义上相同的,只是中文词准确率 用在了不同的 内容上。大家学习机器学习方法时,按照机器学习领域的描述来,不要弄混了,个人觉得最好是记住英文。
参考博文
https://www.cnblogs.com/freebird92/p/9021405.html
https://www.cnblogs.com/sddai/p/5696870.html