word2vec原理及实现
word2vec
内容源自对论文的理解。
Introduction
字词的向量空间模型依靠将语意相近的词语聚在一起来提高自然语言处理的表现。比如训练集中可能会有句子1.the dog is walking和句子2.the cat is walking。很明显因为dog和cat的 上下文(context) 的概率分布很相似,出现dog的句子中,将dog换成cat也很有可能得到一个合法的句子,而将dog换成一个其他一些和dog上下文概率分布不相似的词,就很有可能得到一个不太可能合法的词,比如beautiful。
因此自然有了将相似词(指上下文相似,下同)聚集到一起,将不相似词远离的处理思想。这样也会缩减后续处理中预测误差对最终结果的影响。如果未做上述处理,最终一点
利用人工神经网络训练的字词向量非常有趣,因为它可以用来编码许多线性翻译的模式。比如:利用向量关系表示:Madrid 之于 Spain = Paris 之于 France :
vec(“Madrid”) - vec(“spain”) = vec(“Paris”) - vec(“France”).因此对于一个好的训练结果往往可以通过计算 与vec(“Paris”) + vec(“Spain”) - vec(“Marid”)向量最近的词来求出 France.
这叫作类别推理,这也是目前检测一个词向量系统质量的常用方法。
The Model
cbow(连续词袋模型)利用词语的上下文来预测词语。与之相反,skip-gram利用词语来预测它的上下文。
具体来说,给定一个训练的句子:w1,w2,w3,…,wt.skip-gram模型的目标是最大化以下极大似然估计:
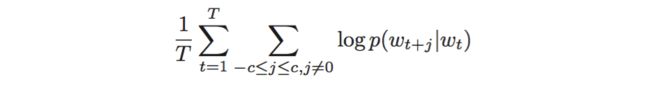
其中t表示单词表中的词数。j表示上下文窗口的大小。
一种比较直观的模型构建方式如下(skip-gram model):
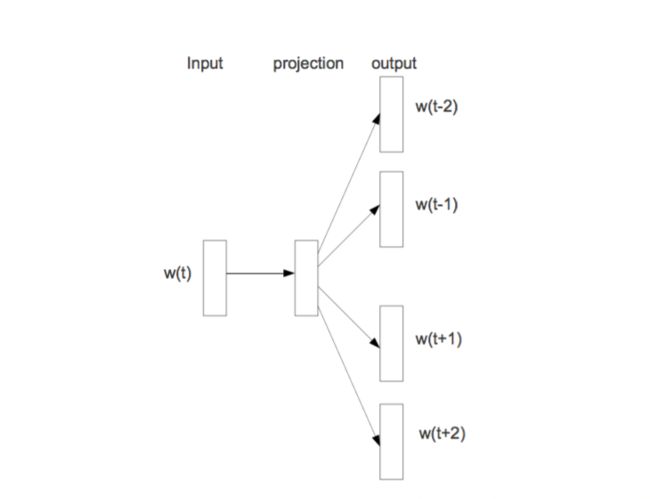
输入一个词的向量表示,利用一个隐含层进行抽象,输出层节点数目等于单词表中词的数目。表示预测各词组成输入词上下文的概率,通常选用softmax来表示输出。
损失函数常选以上极大似然估计的相反数。可以选用一些常见的,如随机梯度下降(SGD)来训练模型。
以上都是skip-gram model的模型表示和训练方法。
cbow model与之大同小异。只是输入由一个单词变成了一个词袋(若干个单词)。
Optimize
以上模型表示的一大缺点是,训练数据量较大时,往往导致单词表中的单词数目很大,在每次前后向传播时,计算softmax将时一个很大的开销。
因此有人提出了使用分层softmax的方法来替代普通的softmax,它在几乎不太影响模型效果的前提下,大大提高了模型的训练速度,真正使模型变得实用。
主要思想是,构造一颗二叉树,使得单词表中的单词均为二叉树的叶子节点。该叶子节点的概率为:从二叉树的根节点到该叶子节点的路径上各个节点与输入单词的向量点乘的连乘:
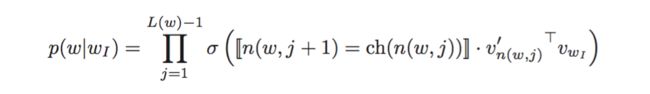
并选择任意方向,如向左为正方向,向右为负方向,利用sigmoid作为概率激活函数。
这样计算每个输入时softmax的计算复杂度由原来的O(n)变成了log(n)。
其实上述分层softmax利用了二分类的思想。每次为一个单词从两个抽象分类中选择其中一种,利用sigmoid函数为两个类分配概率。一直对单词分类直到标定清楚一个单词的具体表示。
就像这样:只不过,下图每个决策点不全是二分类。
因此训练结果中的二叉树的非叶子节点都表示某一抽象类。
构造二叉树的方法有很多,不同构造方法会对计算效率和准确率有略微的影响。
一种常见方法是根据单词的词频构建huffman编码树。可以利用编码01标记每次的正负概率。更重要的思想是,是高频词汇路径短,提高上式连乘速度。
More
其他优化还有
– negtive sampling提高计算效率和效果。
– subsampling提高低频词的计算效果。
字词向量表示(并不只有word2vec一种方法)已成为使用deep learning处理nlp问题常见而卓有成效的预处理方法。
implementation
google code中有原作者团队的纯c实现版本。
tensorflow官方github仓库中也有使用skip-gram思路实现的word2vec版本。
这里再给出利用tensorflwo实现cbow思路的版本。方便在接下来学习和实现doc2vec,sentences2vec和paragraph2vec过程中作参考。
#!/usr/bin/env python
# coding=utf-8
# File Name: cbow1.py
# Author: Fang Pin
# Mail: [email protected]
# Created Time: 2016年08月12日 星期五 15时59分41秒
import tensorflow as tf
import numpy as np
import collections
import math
sentences = []
words = []
batch_size = 128
embedding_size = 128
learning_rate = 1.0
thread_hold = 2 # the frequence of word in vocabulary must greater than thread_hold
skip_window = 1
steps = 1000001
valid_size = 16 # Random set of words to evaluate similarity on.
valid_window = 100 # Only pick dev samples in the head of the distribution.
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64 # Number of negative examples to sample.
for line in open('data.txt','r'):
sentences.append(line)
for word in line.split():
words.append(word)
def build_dataset(words):
count_tmp = []
count_tmp.extend(collections.Counter(words).most_common())
count = [item for item in count_tmp if item[1]>thread_hold]
dic={}
dic['UNK'] = 0
for word,_ in count:
dic[word] = len(dic)
reverse_dic = dict(zip(dic.values(),dic.keys()))
return dic,reverse_dic
dic, reverse_dic = build_dataset(words)
vocabulary_size = len(dic)
del words
sentences_index = 0
word_of_sentencs_index = 0
def generate_batch(batch_size=128, skip_window=1, dic=dic):
global sentences_index
global word_of_sentencs_index
features = np.ndarray([batch_size,2*skip_window],dtype=np.int32)
labels = np.ndarray([batch_size,1],dtype=np.int32)
for i in range(batch_size):
labels[i,0] = dic.get(sentences[sentences_index].split()[word_of_sentencs_index],0)
left_index = word_of_sentencs_index - skip_window
right_index = word_of_sentencs_index + skip_window
left = 0
right = 2*skip_window - 1
for j in range(skip_window):
if left_index < 0:
features[i,left] = 0
else:
features[i,left] = dic.get(sentences[sentences_index].split()[left_index],0)
left_index += 1
left += 1
if right_index >= len(sentences[sentences_index].split()):
features[i,right] = 0
else:
features[i,right] = dic.get(sentences[sentences_index].split()[word_of_sentencs_index],0)
right_index -= 1
right -= 1
word_of_sentencs_index += 1
if word_of_sentencs_index == len(sentences[sentences_index].split()):
word_of_sentencs_index = 0
sentences_index = (sentences_index+1)%len(sentences)
return features,labels
print valid_examples
train_features = tf.placeholder(tf.int32,shape=[batch_size, skip_window * 2])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_features)
reduce_embed = tf.div(tf.reduce_sum(embed, 1), skip_window*2)
nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size],stddev=1.0 / math.sqrt(embedding_size)))
nce_bias = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(tf.nn.nce_loss(nce_weights, nce_bias, reduce_embed, train_labels,num_sampled, vocabulary_size))
train = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul( valid_embeddings, normalized_embeddings, transpose_b=True)
init = tf.initialize_all_variables()
with tf.Session() as session:
init.run()
print("Initialized")
average_loss = 0
for step in xrange(100001):
batch_features, batch_labels = generate_batch()
feed_dict = {train_features : batch_features, train_labels : batch_labels}
_, loss_val = session.run([train, loss], feed_dict=feed_dict)
average_loss += loss_val
if step % 2000 == 0:
if step > 0:
average_loss /= 2000.0
print "at step %d avg_loss average_loss %f"%(step, average_loss)
average_loss = 0
if step % 20000 == 0:
sim = similarity.eval()
for i in xrange(valid_size):
valid_word = reverse_dic[valid_examples[i]]
top_k = 8 # number of nearest neighbors
nearest = (-sim[i, :]).argsort()[1:top_k+1]
log_str = "Nearest to %s:" % valid_word
for k in xrange(top_k):
close_word = reverse_dic[nearest[k]]
log_str = "%s %s," % (log_str, close_word)
print log_str