C语言实现哈夫曼树、编码、解码及问题总结
一、准备知识
1、Huffman树
Huffman树是一类带权路径长度WPL最短的二叉树,中文名叫哈夫曼树或最优二叉树。
相关概念:
结点的路径长度:从根结点到该结点的路径上分支的数目。
树的路径长度:树中每个结点的路径长度之和。
树的带权路径长度:树中所有叶子结点的带权路径长度之和。
![]()
构造Huffman树的步骤:
1) 根据给定的n个权值,构造n棵只有一个根结点的二叉树,n个权值分别是这些二叉树根结点的权;
2) 设F是由这n棵二叉树构成的集合,在F中选取两棵根结点权值最小的树作为左、右子树,构造成一颗新的二叉树,置新二叉树根结点的权值等于左、右子树根结点的权值之和。为了使得到的哈夫曼树的结构唯一,规定根结点权值最小的作为新二叉树的左子树。
3) 从F中删除这两棵树,并将新树加入F;
4) 重复2)、3)步,直到F中只含一棵树为止,这棵树便是Huffman树。
说明:n个结点需要进行n-1次合并,每次合并都产生一个新的结点,最终的Huffman树共有2n-1个结点。
2、Huffman编码
Huffman树在通讯编码中的一个应用:
利用哈夫曼树构造一组最优前缀编码。主要用途是实现数据压缩。在某些通讯场合,需将传送的文字转换成由二进制字符组成的字符串进行传输。
方法:
利用哈夫曼树构造一种不等长的二进制编码,并且构造所得的哈夫曼编码是一种最优前缀编码,使所传电文的总长度最短。
不等长编码:即各个字符的编码长度不等(如:0,10,110,011),可以使传送电文的字符串的总长度尽可能地短。对出现频率高的字符采用尽可能短的编码,则传送电文的总长度便尽可能短。
前缀编码:任何一个字符的编码都不是同一字符集中另一个字符的编码的前缀。

二、代码实现
使用链表结构构建哈夫曼树并进行编码、解码,代码如下:
#include
#include
#include
typedef int ELEMTYPE;
// 哈夫曼树结点结构体
typedef struct HuffmanTree
{
ELEMTYPE weight;
ELEMTYPE id; // id用来主要用以区分权值相同的结点,这里代表了下标
struct HuffmanTree* lchild;
struct HuffmanTree* rchild;
}HuffmanNode;
// 构建哈夫曼树
HuffmanNode* createHuffmanTree(int* a, int n)
{
int i, j;
HuffmanNode **temp, *hufmTree;
temp = malloc(n*sizeof(HuffmanNode));
for (i=0; iweight = a[i];
temp[i]->id = i;
temp[i]->lchild = temp[i]->rchild = NULL;
}
for (i=0; iweight < temp[small1]->weight)
{
small2 = small1;
small1 = j;
} else if (temp[j]->weight < temp[small2]->weight)
{
small2 = j;
}
}
}
hufmTree = (HuffmanNode*)malloc(sizeof(HuffmanNode));
hufmTree->weight = temp[small1]->weight + temp[small2]->weight;
hufmTree->lchild = temp[small1];
hufmTree->rchild = temp[small2];
temp[small1] = hufmTree;
temp[small2] = NULL;
}
free(temp);
return hufmTree;
}
// 以广义表的形式打印哈夫曼树
void PrintHuffmanTree(HuffmanNode* hufmTree)
{
if (hufmTree)
{
printf("%d", hufmTree->weight);
if (hufmTree->lchild != NULL || hufmTree->rchild != NULL)
{
printf("(");
PrintHuffmanTree(hufmTree->lchild);
printf(",");
PrintHuffmanTree(hufmTree->rchild);
printf(")");
}
}
}
// 递归进行哈夫曼编码
void HuffmanCode(HuffmanNode* hufmTree, int depth) // depth是哈夫曼树的深度
{
static int code[10];
if (hufmTree)
{
if (hufmTree->lchild==NULL && hufmTree->rchild==NULL)
{
printf("id为%d权值为%d的叶子结点的哈夫曼编码为 ", hufmTree->id, hufmTree->weight);
int i;
for (i=0; ilchild, depth+1);
code[depth] = 1;
HuffmanCode(hufmTree->rchild, depth+1);
}
}
}
// 哈夫曼解码
void HuffmanDecode(char ch[], HuffmanNode* hufmTree, char string[]) // ch是要解码的01串,string是结点对应的字符
{
int i;
int num[100];
HuffmanNode* tempTree = NULL;
for (i=0; ilchild!=NULL && tempTree->rchild!=NULL)
{
if (num[i] == 0)
{
tempTree = tempTree->lchild;
} else
{
tempTree = tempTree->rchild;
}
++i;
}
printf("%c", string[tempTree->id]); // 输出解码后对应结点的字符
}
}
}
int main()
{
int i, n;
printf("请输入叶子结点的个数:\n");
while(1)
{
scanf("%d", &n);
if (n>1)
break;
else
printf("输入错误,请重新输入n值!");
}
int* arr;
arr=(int*)malloc(n*sizeof(ELEMTYPE));
printf("请输入%d个叶子结点的权值:\n", n);
for (i=0; i 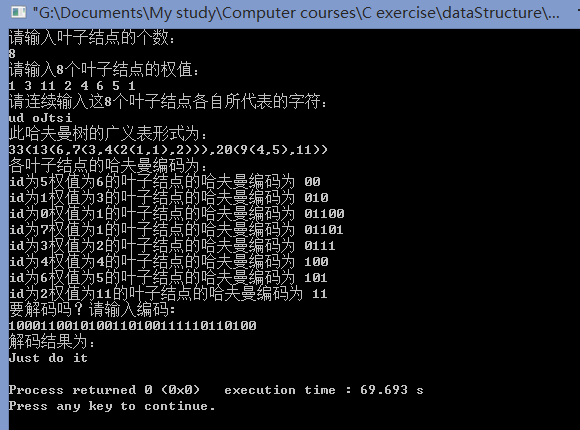
三、程序实现过程当中遇到的问题总结
1)关于哈夫曼树,知道了叶子结点,如何不用静态数组存储整个哈夫曼树及构建过程中的生成树?
答:使用malloc函数开辟一段内存空间存结构体类型的树,若往树中添加新的结点挂在结构体指针上即可,这就要求定义的结构体里面包含结构体指针,这也是结构体指针的作用。也就是使用链表动态存储,每个结点都是一个包含结构体指针的结构体,生成过程中动态开辟,不管这棵树有多少个结点都可以存下。
2)
typedef struct stHuNode
{
int data; // 权值
struct stHuNode* lchild; //这两句等价于 struct stHuNode* lchild, *rchild;
struct stHuNode* rchild;
}HUNODE;
3)scanf语句里不要有换行符?scanf函数的用法,scanf(" %d", &i);和scanf("%d ",&i);效果不同,差别在哪?
答:scanf函数的一般形式为:scanf(“格式控制字符串”, 地址表列);格式控制字符串中不能显示非格式字符串,也就是不能显示提示字符串和换行符。” %d” 和“%d”作用一样,%d前面的空格不起作用,”%d “空格加在%d后面赋值时要多输入一个值,实际赋值操作时多输入的数并没有被赋值只是缓存到了输入流stdin中,下次如果再有scanf和gets语句要求赋值时,要先用fflush(stdin);语句强制清除缓存再赋值,否则原先在stdin中的值就会被赋过去导致错误。
4)灵感:怎样解码?根据输入的01串解出相应的权值?
答:No!如果两个不同的字符对应的权值相同呢?如何区分?起初想到如果在建立哈夫曼树的过程中可以记录下相应的下标就不会导致相同权值无法区别的问题,但在具体如何实现上,刚开始想输出每一次建树的small1和small2,但发现这样很不清晰,用户要想确定每个字符的下标得按照建树过程走一遍才行,那要程序何用,而且给用户造成了很大的麻烦,不可取。后来想到,可以在结点的结构体中添加id信息,这样即使权值相同的结点也可以区分开来,这里的id可以是下标,因为用户输入权值的顺序一定则下标唯一。如果解码解出来的是权值标号的话就没有异议了,可是下标又不是很直观清晰,不如直接输出相应的字符好,又想到两个解决办法:a)将结点id信息直接定义成字符,只不过在建树的过程中要将字符和权值都加入结点中;b)id仍然是下标,在用户输入权值对应的字符时,用字符数组存储并和id对应起来,这样解码得到id之后,可以输出对应的字符,实现起来相对比较简单。
5)疑问:如果根据用户输入的字符串进行编码解码得到了新的字符串,旧字符串和新字符串有没有直接看出来的规律,就是说人眼观察和推导能否得到相应的规律,或者说有没有可能直接能得出规律不用经过编码解码。留为疑问!
答:后经测试发现不行。
6)gets()函数的用法,如何获取一个字符串,赋值时跳过gets()函数的执行,貌似gets()没起作用的问题。
答:当使用gets()函数之前有过数据输入,并且,操作者输入了回车确认,这个回车符没有被清理,被保存在输入缓存中时,gets()会读到这个字符,结束读字符操作。因此,从用户表面上看,gets()没有起作用,跳过了。
解决办法:
方法一、在gets()前加fflush(stdin); //强行清除缓存中的数据(windows下可行)
方法二、根据程序代码,确定前面是否有输入语句,如果有,则增加一个getchar()命令,然后再调用 gets()命令。
方法三、检查输入结果,如果得到的字符串是空串,则继续读入,如:
char str[100]={0};
do {
gets(str);
} while( !str[0] );
7)初始化数组语句:memset(str,0, sizeof(str)); 理解一下!
答:函数解释:将 str 中前 n 个字节用 ch 替换并返回 str。memset(str, 0, sizeof(str));意思是将数组str的长度(字节数,不是元素个数)置零。
memset:作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法。
8)关于strlen()函数
答:strlen函数的用法,包含头文件string.h。且是对字符数组中的字符串求长度!
其原型为: unsigned int strlen (char *s);
【参数说明】s为指定的字符串。
strlen()用来计算指定的字符串s 的长度,不包括结束字符"\0"。
【返回值】返回字符串s 的字符数。
注意:strlen() 函数计算的是字符串的实际长度,遇到第一个'\0'结束。如果你只定义没有给它赋初值,这个结果是不定的,它会从首地址一直找下去,直到遇到'\0'停止。而sizeof返回的是变量声明后所占的内存数,不是实际长度,此外sizeof不是函数,仅仅是一个操作符,strlen()是函数。