python3爬虫实战之小说(一)
一、目标
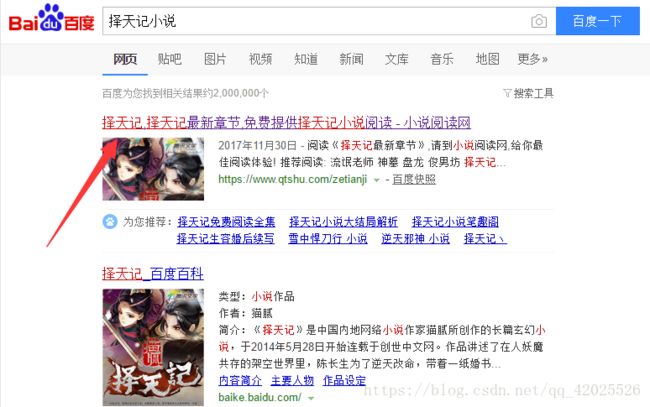
以前看过择天记,挺喜欢的,这次选它为目标
知乎:https://zhuanlan.zhihu.com/p/41282580
GitHub:https://github.com/FanShuixing/git_webspider
(ps:支持正版,本文纯属学习交流)
二、知识点
1、pyquery解析网页,相比较BeautifulSoup,我选择pyquery,pyquery在css选择上很是强大和方便,一会我们来感受一下
若是没有安装,直接pip3 install pyquery,同时推荐崔大的 https://cuiqingcai.com/5551.html
2、requests库的使用
如不熟悉可参考文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
三、进入正题
整体思路:先下载网页,并提取出这一页的标题和链接—>根据链接,抓取每一页的数据。
进入上图中的链接后,我们首先下载这个网页,并打印出来(ps:本文提供思路和方法,如requests和pyquery的详细介绍可参考知识点中罗列出来的网址)
import requests
def crawle():
url='https://www.qtshu.com/zetianji/'
req=requests.get(url=url)
html=req.text
print(html)
crawle()输出如下图:
编码不正确,使用encoding可以改变编码,首先我们需要知道网页采用的是什么编码,我们打开网页的开发者工具(F12),查看head标签下的信息
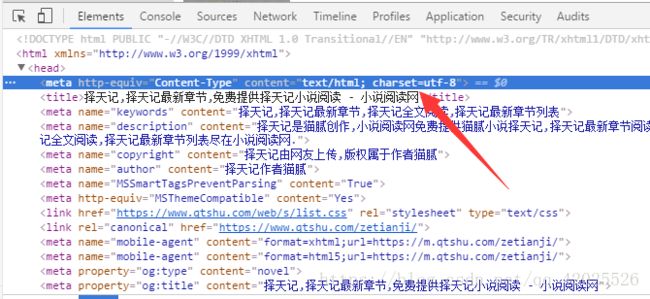
charset中的‘utf-8’就是网页的编码,改变编码
import requests
def crawle():
url='https://www.qtshu.com/zetianji/'
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
print(html)
crawle()这下网页就被正确的打印出来了。
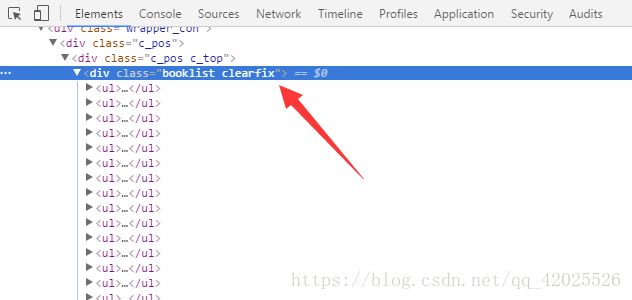
只是单纯的下载网页没有什么意义,爬虫主要的目的是提取数据,接下来我们通过pyquery提取标题和链接,在任意一个标题下右键审查元素,得到下图,可见整篇文章内容都是在class为booklist clearfix的标签中
import requests
from pyquery import PyQuery as pq
def crawle():
url='https://www.qtshu.com/zetianji/'
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
# print(html)
#初始化pyquery对象
doc=pq(html)
#传入css选择器
items=doc('.booklist ul li').items()
for each in items:
title=each.text()
url=each.find('a').attr('href')
print(title,url)
crawle()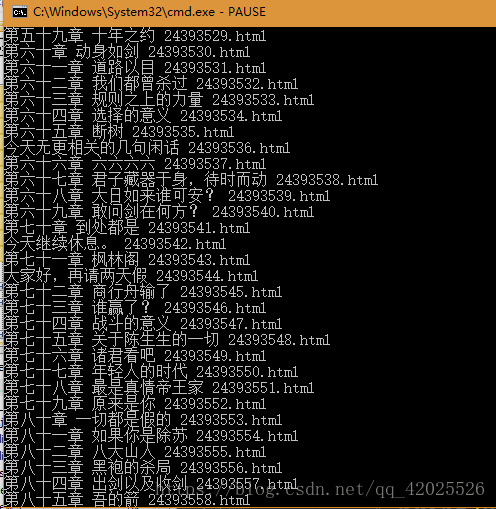
只需要在url前面加上’https://www.qtshu.com/zetianji/‘就可以得到每章的链接了
那么得到链接后当然该爬取小说正文了,依然利用pyquery解析网页
def Text(url):
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
doc=pq(html)
item=doc('.contentbox p').text()
print(item)
# crawle()
url='https://www.qtshu.com/zetianji/2988454.html'
Text(url)
接下来综合代码:
import requests
from pyquery import PyQuery as pq
def crawle():
url='https://www.qtshu.com/zetianji/'
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
# print(html)
#初始化pyquery对象
doc=pq(html)
#传入css选择器
items=doc('.booklist ul li').items()
for each in items:
title=each.text()
url=each.find('a').attr('href')
#有的没有url
if url:
url='https://www.qtshu.com/zetianji/'+url
print(title,url)
Text(url)
def Text(url):
print('正在提取:',url)
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
doc=pq(html)
item=doc('.contentbox p').text()
print(item)
crawle()
# url='https://www.qtshu.com/zetianji/2988454.html'
# Text(url)数据提取出来当然是拿来用的,我们需要把数据存储下来。
import requests
from pyquery import PyQuery as pq
import os,sys
os.chdir('E:/爬虫数据')
def crawle():
url='https://www.qtshu.com/zetianji/'
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
# print(html)
#初始化pyquery对象
doc=pq(html)
#传入css选择器
items=doc('.booklist ul li').items()
#m和index是为了计算下载进度
m=len(doc('.booklist ul li'))
fr=open('择天记.txt','w')
index=1
for each in items:
title=each.text()
url=each.find('a').attr('href')
#有的没有url
if url:
index+=1
url='https://www.qtshu.com/zetianji/'+url
# print(title,url)
text=Text(url)
fr.write(title)
fr.write('\n\n')
fr.write(text)
fr.write('\n\n')
sys.stdout.write('已下载:%.3f%%'%float(index/m)+'\r')
sys.stdout.flush()
from bs4 import BeautifulSoup
def Text(url):
print('正在提取:',url)
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
doc=pq(html)
item=doc('.contentbox p').text()
return item
crawle()
# url='https://www.qtshu.com/zetianji/2988454.html'
# Text(url)运行之后程序便报错了
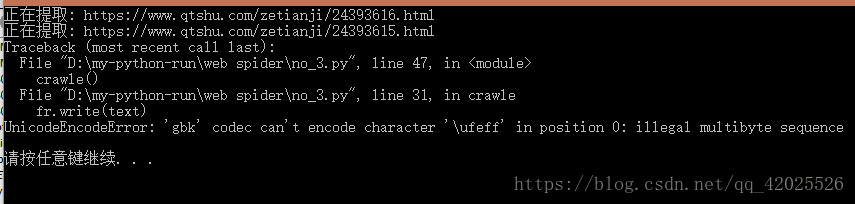
UnicodeEncodeError: ‘gbk’ codec can’t encode character …
这个问题在python提取数据存储到本地时经常出现,举一个简单的例子说明这个问题错误来源于哪里
a='¥'
b='¥'
print(a)
print(b)
print(a.encode())
print(b.encode())
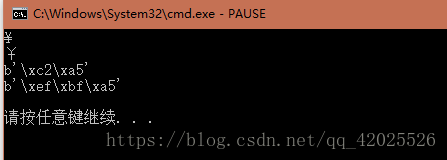
上面两个字符表达的是同一个意思,但是他们是不同的字符,我们只是让它输出显示的时候,通过print这两个字符分别都可以显示。现在,我们尝试着把他们写入到本地,先写a
a='¥'
b='¥'
print(a)
print(b)
print(a.encode())
print(b.encode())
print('\n\n')
with open('a.txt','w') as fr:
fr.write(a)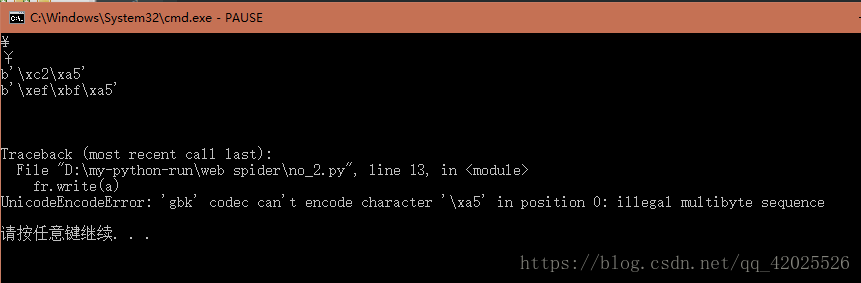
再尝试把第二个字符写入到本地
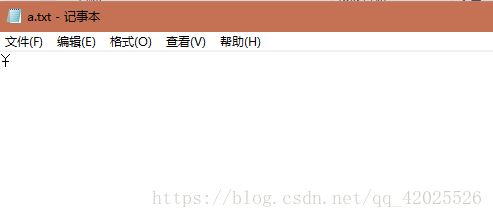
第二个字符被正确的写入到里面
解决办法:二种
一、把第一个字符用第二个字符替换掉,这种稍微麻烦一点,因为第一个字符通常是来自于浏览器中,你需要找到是哪个字符不能正确被编译,第二个字符很好办,在浏览器中找到第一个字符后,把它复制到你的编译器中(我的是notepad++),它就会自动变成第二个字符。然后我们用个replace替换掉就好
if '¥' in a:
a=a.replace('¥','¥')
二、刚才报错写的是
UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa5’ in position 0: illegal multibyte sequence
我们就直接这样:
if '\xa5' in a:
a=a.replace('\xa5','')
我们采用第二种方式:
import requests
from pyquery import PyQuery as pq
import os,sys
os.chdir('E:/爬虫数据')
def crawle():
url='https://www.qtshu.com/zetianji/'
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
# print(html)
#初始化pyquery对象
doc=pq(html)
#传入css选择器
items=doc('.booklist ul li').items()
#m和index是为了计算进度
m=len(doc('.booklist ul li'))
index=1
fr=open('择天记.txt','w')
print('*'*100)
print(' '*50,'欢迎学习交流')
print('*'*100)
for each in items:
title=each.text()
url=each.find('a').attr('href')
#有的没有url
if url:
index+=1
url='https://www.qtshu.com/zetianji/'+url
# print(title,url)
text=Text(url)
fr.write(title)
fr.write('\n\n')
fr.write(text)
fr.write('\n\n')
#进度条显示
sys.stdout.write('已下载:%.3f%%'%float(index/m)+'\r')
sys.stdout.flush()
from bs4 import BeautifulSoup
def Text(url):
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
doc=pq(html)
item=doc('.contentbox p').text()
if '\ufeff' in item:
item=item.replace('\ufeff','')
if '\xa0' in item:
item=item.replace('\xa0','')
return item
crawle()
# url='https://www.qtshu.com/zetianji/2988454.html'
# Text(url)
到此为止,程序算小完成了,但是考虑到网络不稳定,在下载小说页面的时候很有可能会中途出错而停止下载,要是能够把下载的网页存储到本地就好了,这样要是遇到下载错误的时候,我们不用再重新下载下过的页面,直接从网页调取就是了。
这儿有个福利,以前在学爬虫教程的时候写好了下载并缓存到本地的类,我们可以直接调用这个类,需要改的地方只有一处
import requests
from pyquery import PyQuery as pq
import os,sys
from Cache import Downloader
from Cache import DiskCache
os.chdir('E:/爬虫数据')
def crawle():
url='https://www.qtshu.com/zetianji/'
req=requests.get(url=url)
req.encoding='utf-8'
html=req.text
# print(html)
#初始化pyquery对象
doc=pq(html)
#传入css选择器
items=doc('.booklist ul li').items()
#m和index是为了计算进度
m=len(doc('.booklist ul li'))
index=1
fr=open('择天记.txt','w')
print('*'*100)
print(' '*50,'欢迎学习交流')
print('*'*100)
for each in items:
title=each.text()
url=each.find('a').attr('href')
#有的没有url
if url:
index+=1
url='https://www.qtshu.com/zetianji/'+url
# print(title,url)
text=Text(url)
fr.write(title)
fr.write('\n\n')
fr.write(text)
fr.write('\n\n')
#进度条显示
sys.stdout.write('已下载:%.3f%%'%float(index/m)+'\r')
sys.stdout.flush()
from bs4 import BeautifulSoup
def Text(url):
html=D(url)
doc=pq(html)
item=doc('.contentbox p').text()
if '\ufeff' in item:
item=item.replace('\ufeff','')
if '\xa0' in item:
item=item.replace('\xa0','')
return item
cache=DiskCache()
D=Downloader(cache)
crawle()
# url='https://www.qtshu.com/zetianji/2988454.html'
# Text(url)#Cache.py
import urllib.request
import re,os
import pickle,requests
from urllib.parse import quote
os.chdir("E:/爬虫数据")
#这个模块可以当作模板来使用,不怎么用修改
class Downloader:
def __init__(self,cache):
self.cache=cache
def __call__(self,url):
result=None
if self.cache:
try:
result=self.cache[url]
# print("已调入数据")
except:
pass
if result==None:
result=self.download(url)
if self.cache:
# print(type(url))
self.cache[url]=result
return result
def download(self,url,num_retry=2):
# print('下载中:',url)
headers={'User-agent':'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)'}
req=requests.get(url=url,headers=headers)
req.encoding='utf-8'
html=req.text
return(html)
class DiskCache:
def __init__(self,cache_dir='Cache'):
self.cache_dir=cache_dir
def __getitem__(self,url):
path=self.url_to_path(url)
if os.path.exists(path):
with open(path,'rb') as fp:
return pickle.load(fp)
def __setitem__(self,url,result):
path=self.url_to_path(url)
folder=os.path.dirname(path)
if not os.path.exists(folder):
os.makedirs(folder)
with open(path,'wb') as fp:
fp.write(pickle.dumps(result))
def url_to_path(self,url):
components=urllib.parse.urlsplit(url)
path=components.path
if not path: #即path为空
path='nihao'
elif path.endswith('/'):
path+='index.html'
filename=components.netloc+path+components.query
filename=re.sub('[^/0-9a-zA-Z\-.,;_]','_',filename)
filename='/'.join(segment[:255] for segment in filename.split('/'))
return(os.path.join(self.cache_dir,filename))
if __name__=='__main__':
a=Downloader(DiskCache())
a.download('https://book.douban.com/subject/1059336/')
在Cache中只需要修改一处,就是Downloader类中的download()方法,其中编码要试网页而定,不同的网页编码不一样,
req.encoding='utf-8'这个Cache模块非常方便,它会把网页缓存到本地,当需要的时候会被调用。
