《现代信息检索导论》课程梳理
目录
什么是信息检索?
一个文本检索系统是怎样的?
一、分词
二、索引
1.索引怎么得来:
2.构建索引:
3.怎么查询:
4.索引压缩:
5.索引的解压
三、评分
那么怎么来评分呢?
四、反馈
1.相关反馈:
2.查询扩展:
五、结果摘要
六、怎么加速检索?
1.精确top K检索及其加速办法
2.非精确top K检索的可行性
七、信息检索的评价指标
1.对单个查询进行评估的指标(对单个查询得到一个结果):
2.对多个查询进行评估的指标(在多个查询上检索系统的得分求平均)
八、向量空间模型VS 概率检索模型 VS 统计语言模型
1.向量空间模型:
2.概率检索模型:
3.统计语言模型:(本质上也是概率模型的一种)
九、文档分类
十、Web搜索
1.爬虫
2.PageRank VS HITS
什么是信息检索?
信息检索的概念:从大规模非结构化数据(通常是文本)的集合中找出满足用户需求的资料(通常是文档)的过程。而传统数据库往往是结构化数据(比如一张表中的数据),常常支持范围或者精确匹配查询。信息检索已经替代传统的数据库式搜索而成为信息访问的主要形式。
一个文本检索系统是怎样的?
一个文本检索系统=分词+索引+评分+反馈(+结果摘要)
下面有两幅图,可以让大家在脑海中对一个信息检索系统有个大概的轮廓
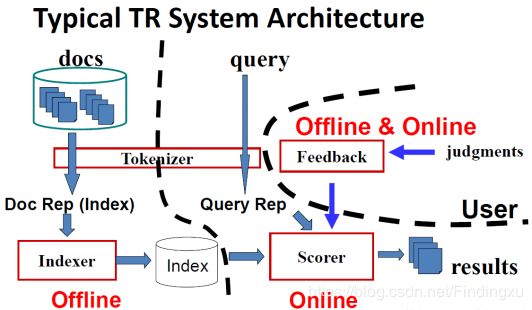

拿到 文本集和查询需求 时,要分词成为某种表现形式,文本集要建立成索引,然后进行查询,对结果评分,返回分数高的哪些结果(摘要),在打分的过程中还会加入反馈,从而使得结果越来越好。
一、分词
分词的流程:
文本通过词条化为词条,词条归一化为词项,词项就是我们最终放入倒排索引的词典中,是我们要索引的对象。

二、索引
索引是把文档变为一种便于快速查找的数据结构。其中最主要的一种思想是倒排索引(Inverted index)。倒排索引是以词作为关键词,记录词出现的文档编号,以及在文档中的词频、位置等信息。
倒排索引的数据结构:词典 + 倒排记录表
1.索引怎么得来:

2.构建索引:
面对现实中的信息量大、读取效率、分布式等问题,有各种构建索引的方法:
2.1两种索引构建算法: BSBI (简单) 和 SPIMI (更符合实际情况)
2.2分布式索引构建: MapReduce
2.3动态索引构建: 如何随着文档集变化更新索引
3.怎么查询:
3.1 布尔检索 (使用布尔表达式):对查询语句进行布尔化,对倒排记录表进行并集,交集,差集等操作
3.2 查词典:词典是存储词项词汇表的数据结构,在查字典时,用到哈希表和树结构两种数据结构
3.3 通配查询的处理(包含通配符*的查询):轮排索引和k-gram索引
3.4 拼写出错的查询:
对查询进行拼写校正(不改变文档)
词独立法:只关心当前单词有没有拼错,方法有:编辑距离计算和k-gram相似度
上下文敏感法:考虑上下文
soundex算法:针对发音相同而出现的拼写错误
4.索引压缩:
词典压缩:将整部词典看成单一字符串,把该字符串按块存储,然后采用前端编码(因为同一块下的词项前缀很多相同)
倒排记录表压缩:对间隔编码,可变字节编码,![]() 编码
编码
5.索引的解压
最近的文本压缩方法允许在压缩文本上直接进行查找,而且,查找速度快于在未压缩文本上的查找速度。同时,在压缩文本任一点上的直接存取也可以实现。因此,信息检索系统可以在压缩文本上直接存取一个给定的词,而不需要从压缩文本的开始处解压缩整个文本。
三、评分
布尔检索,即文档(与查询)要么匹配要么不匹配,结果过少或者过多,需要大量技巧来生成一个可以获得合适规模结果的查询
而在我们日常浏览器中见到的是排序式检索
排序式检索会对查询和文档的匹配程度进行排序,即给出一个查询和文档匹配评分,相关度大的文档结果会排在相关度小的文档结果之前。
那么怎么来评分呢?
对每个查询-文档对赋一个[0, 1]之间的分值来度量了文档和查询的匹配程度
不考虑Jaccard系数:计算两个集合重合度的常用方法,很多缺点。
查询-文档匹配评分计算:
词项频率 tf:指t 在d中出现的次数,是与文档相关的一个量,可以认为是文档内代表度的一个量
逆文档频率idf:dft是出现词项t的文档数目,dft 是和词项t的信息量成反比的一个值(物以稀为贵)
tf-idf权重计算:(采用对数来抑制影响)
![]()
随着词项频率的增大而增大 (局部信息),随着词项罕见度的增加而增大 (全局信息)
这里就用到了向量空间模型(VSM)
评分流程如下;
1.表示成向量:
(1)文档表示成向量:
每篇文档表示成一个基于tfidf权重的实值向量 ∈ R|V|,于是,我们有一个 |V|维实值空间,
空间的每一维都对应词项,文档都是该空间下的一个点或者向量;极高维向量:对于Web搜索引擎,空间会上千万维;对每个向量来说又非常稀疏,大部分都是0
(2)查询看成向量:
对于查询做同样的处理,即将查询表示成同一高维空间的向量,按照文档对查询的邻近程度排序
2.查询和文档两个向量之间的相似度计算:
采用夹角而不是距离来计算--->余弦相似度计算:要归一化
3.按照相似度大小将文档排序,将前K(如K =10)篇文档返回给用户
四、反馈
两种提高召回率的方法—相关反馈及查询扩展(实际也有可能提高正确率)
局部方法: 对用户查询进行局部的即时的分析
主要的局部方法: 相关反馈
全局方法: 进行一次性的全局分析(比如分析整个文档集)来产生同/近义词词典 (thesaurus),利用该词典进行查询扩展
1.相关反馈:
显式相关反馈:在初始检索结果的基础上,通过用户交互指定哪些文档相关或不相关,然后改进检索的结果,也叫用户相关反馈
隐式相关反馈:通过观察用户对当前检索结果采取的行为(点击行为、眼球行为等)来给出对检索结果的相关性判定
伪相关反馈:对于真实相关反馈的人工部分进行自动化,对于用户查询返回有序的检索结果
假定前 k 篇文档是相关的,进行相关反馈 (如 Rocchio)
最著名的相关反馈方法:Rocchio 相关反馈
2.查询扩展:
查询扩展(Query expansion): 通过在查询中加入同义或者相关的词项来提高检索结果
相关词项的来源: 人工编辑的同义词词典、自动构造的同义词词典、查询日志等等。
五、结果摘要
怎么呈现出结果,描述该列表中的每篇文档,用户往往根据该描述来判断结果的相关性,而不需要按次序点击所有文档
静态摘要:不论输入什么查询,文档的静态摘要都是不变的
动态摘要:而动态摘要依赖于查询,它试图解释当前文档返回的原因
六、怎么加速检索?
1.精确top K检索及其加速办法
目标:从文档集的所有文档中找出K 个离查询最近的文档
(一般)步骤:对每个文档评分(余弦相似度),按照评分高低排序,选出前K个结果
如何加速:
思路一:加快每个余弦相似度的计算--->无权重查询
思路二:不对所有文档的评分结果排序而直接选出Top K篇文档---->用堆方法
思路三:能否不需要计算所有N篇文档的得分?--->提前终止计算
2.非精确top K检索的可行性
索引去除,胜者表,静态质量得分排序方式,影响度(Impact)排序,簇剪枝
非docID的倒排记录表排序方法,多层次索引等
七、信息检索的评价指标
1.对单个查询进行评估的指标(对单个查询得到一个结果):
召回率(Recall),正确率(Precision)
缓冲池(Pooling)方法:对多个检索系统的Top k个结果组成的集合(并集)进行人工标注,标注出的相关文档集合作为整个相关文档集合。
F值(F-measure):召回率R和正确率P的调和平均值
R-Precision:检索结果中,在所有相关文档总数位置上的准确率。
正确率-召回率 P-R曲线
2.对多个查询进行评估的指标(在多个查询上检索系统的得分求平均)
平均的求法:宏平均,微平均
MAP(Mean AP),Bpref,GMAP,NDCG
八、向量空间模型VS 概率检索模型 VS 统计语言模型
1.向量空间模型:
优点:简洁直观,可以应用到很多其他领域(文本分类、生物信息学)。支持部分匹配和近似匹配,结果可以排序;检索效果不错
缺点:理论上不够严谨,往往基于直觉的经验性公式;词项之间的独立性假设与实际不符:实际上,词项的出现之间是有关系的,并不是完全独立的。如:“张继科”、“乒乓球”的出现不是独立的。
2.概率检索模型:
通过概率的方法将查询和文档联系起来
定义3个随机变量R、Q、D:相关度R={0,1},查询Q={q1,q2,…},文档D={d1,d2,…},则可以通过计算条件概率P(R=1|Q=q,D=d)来度量文档和查询的相关度。
概率模型包括一系列模型,如Logistic Regression(回归)模型及最经典的二值独立概率模型BIM、BM25模型等等(还有贝叶斯网络模型)
3.统计语言模型:(本质上也是概率模型的一种)
广泛使用于语音识别和统计机器翻译领域,利用概率统计理论研究语言
SLM广泛使用于语音识别和统计机器翻译领域,利用概率统计理论研究语言。
规则方法:词、句、篇章的生成比如满足某些规则,不满足该规则就不应存在。
统计方法:任何语言片断都有存在的可能,只是可能性大小不同
对于一个文档片段d=w1w2…wn,统计语言模型是指概率P(w1w2…wn)求解,根据Bayes公式,有
统计语言建模IR模型(SLMIR)
1.查询似然模型:把相关度看成是每篇文档对应的语言下生成该查询的可能性
2.翻译模型:假设查询经过某个噪声信道变形成某篇文章,则由文档还原成该查询的概率(翻译模型)可以视为相关度
3.KL距离模型:查询对应某种语言,每篇文档对应某种语言,查询语言和文档语言的KL距离作为相关度度量
九、文档分类
统计分类是一个成功的搜索引擎所必需的关键技术,给定一系列文档及其归属类别的前提下,将新文档分配到某个或者某几个类别中去。
朴素贝叶斯算法:该算法概念虽然简单,但是文本分类的效率很高),
基于向量空间模型的分类方法: Rocchio 和 kNN
支持向量机:这是目前公认的效果最好的文本分类算法
十、Web搜索
1.爬虫
Web 采集器。基本的采集过程为,初始化采集 URL 种子队列,重复的 1.取出 URL 2.下载
并分析网页 3.从网页中抽取更多的 URL 4.将 URL 放到队列中。
2.PageRank VS HITS
PageRank:从很多优质网站链接过来的网页肯定还是优质的网页。
HITS:既然搜索开始于用户的检索提问,那么每个页面的重要性也依赖于用户的检索提问。现代信息检索