CUDA C最佳实践-CUDA Best Practices(二)
9. 内存优化
看页数也知道,内存优化是性能提升最重要的途径。目标在于通过最大化带宽获得对硬件的最大使用率。最好使用快速内存而减少慢速内存的访问。这章就是各种讨论内存优化。
9.1. 主机和设备之间的数据传输
设备内存的带宽是上百G而PCIe总线的带宽就8G,所以最重要的就是尽量不要传输数据,要把数据放到GPU上,即使在当前的Kernel用不到也要放在上头。并且,由于传输数据消耗很大,要尽量把小批量的数据合并成大批量的数据。最后,使用页锁定内存能获得更高的带宽。
9.1.1. 页锁定内存
页锁定内存就不用多说了,是主存上的一种内存形式,可以使用cudaHostAlloc()来申请也可以用cudaHostRegister()将内存注册为页锁定内存。CUDA Sample里的bandwidthTest这个例子就展示了这种内存的使用(打一波广告:CUDA Samples).但是要注意了,页锁定内存虽好可不能贪杯哦,它占用了很多内存空间又不能被替换出去,会降低系统的性能,而且从长远来开,页锁定相比于其他内存分配对于系统来说消耗很大,所以与其他的优化一样,要测试系统性能以获得最佳的参数。
9.1.2. 数据传输与计算异步重叠
想要进行异步拷贝(cudaMemcpyAsync()),就要使用页锁定内存。而且异步传输可以将执行与数据传输重叠,代码如下:
//最后一个参数是流的参数
cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, 0);
kernel<<>>(a_d);
//这个CPU程序也是重叠的,因为内存拷贝和Kernel执行开始之后会马上把控制权交个host
cpuFunction(); 而使用多个流,就能够更好地利用这种重叠。前提是数据可以被分解块被Kernel计算。
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaMemcpyAsync(a_d, a_h, size, cudaMemcpyHostToDevice, stream1);
kernel<<0, stream2>>>(otherData_d); 重点是多个流:
size=N*sizeof(float)/nStreams;
for (i=0; i0,stream[i]>>>(a_d+offset);
} 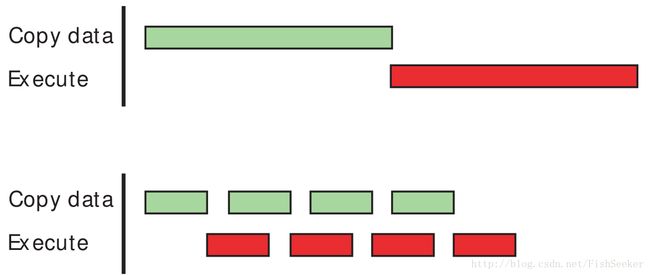
绿色的条是数据传输的时间,红色的条是执行的时间分别用tt,te来表示。当数据传输时间比较长的时候,总体时间是tt+te/n。如果反过来就是te+tt/n。
9.1.3. 零拷贝
这是2.2之后加入的特性。可以让GPU直接使用主机内存。在集成的GPU上,这是有好处的因为它避免了数据拷贝,但是对于独立于CPU的GPU来说,如果数据就只用一次,这个开销还是很大的。这个可以用于替代stream,因为使用这个让Kernel向数据传输自动与执行重叠而不用费心关于流的设置。
下面是关于零拷贝内存的代码:
float *a_h, *a_map;
...
cudaGetDeviceProperties(&prop, 0);
//用来判断是否支持零拷贝内存
if (!prop.canMapHostMemory)
exit(0);
//在选择设备和在进行CUDA调用之前,一定要执行下面的语句使得零拷贝内存可用
cudaSetDeviceFlags(cudaDeviceMapHost);
//使用下面的函数申请领考别内存
cudaHostAlloc(&a_h, nBytes, cudaHostAllocMapped);
cudaHostGetDevicePointer(&a_map, a_h, 0);
kernel<<>>(a_map); 9.1.4. 统一虚拟地址
主机内存和设备内存有统一的虚拟地址。cudaPointerGetAttributes()这个函数可以让内存指向你想要的地方,但是一般cudaHostAlloc分配好的可以直接指向规定的区域(有参数设置)。同时这对P2P也有很大帮助,详情请看CUDA C Programming Guide里有关UVA和P2P的章节。
9.2. 设备内存空间
CUDA使用的内存图:
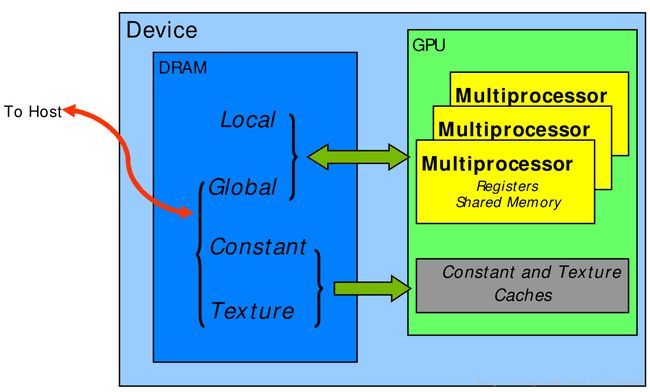
下面是关于各种内存空间特性的表:

一个十字花:在计算力2.x的时候允许cache L1 和L2,在更高的计算力下默认只cache L2,虽然也可以通过设置打开L1
俩十字花:在计算力2.x和3.xcache L1 and L2,在计算力5.x时默认L2
9.2.1. 聚合访问全局内存
就是,一定一定一定要合并访问全局内存,这样才能减少事务的个数。
对于计算力2.x的设备,请求可以简单的总结如下:线程束内线程并行地访问将会聚合成一系列事务,事务的数量和为warp的所有线程服务所需的cache 块一样。默认情况下,所有的访问都经过L1(128个字节)。对于分散的访问模式,为了减少过度取数据,可以只用L2 cache,因为它一块有32个字节。
对于计算力3.x的设备,只经过L2。L1是用来给本地内存使用的。一些计算力比如3.5,3.7和5.2允许设置L1。
9.2.1.1. 一个简单的访问模式
这个简单的模式是这样的:
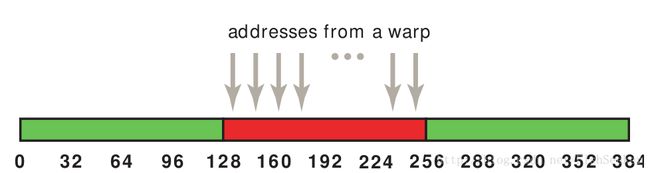
这个访问方式触发一个128字节的内存事务。就算是如果有些数据没用,但是还是会被全部取到cache里。
9.2.1.2. 顺序但非对齐的访问模式
下面是非对齐的:

对于这样非对齐的,就会导致两个内存事务。
如果是用L2的话这种情况会有所改善:

因此,让block的大小是warp的倍数很重要,想象一下如果不是倍数关系,那第二个、第三个块都是不对齐的,会造成多大的浪费。
9.2.1.3. 高效地对齐访问
为了验证我们的结果,设计了以下的实验:
__global__ void offsetCopy(float *odata, float* idata, int offset)
{
//offset取值从0-32
int xid = blockIdx.x * blockDim.x + threadIdx.x + offset;
odata[xid] = idata[xid];
}不同的offset下有不同的带宽,实验结果如下:

虽然根据上文的分析,应该是non-caching的效率会更高,但是实验结果却不是这样,这是因为线程束使用了它们相邻线程束所取到的数据。如果相邻的线程束依赖关系不那么多,才会出现我们理想的结果。
9.2.1.4. 有步长的访问
由上面可以得出一点建议就是尽可能充分使用你取到的数据。下面我们再看另一种情况:
__global__ void strideCopy(float *odata, float* idata, int stride)
{
int xid = (blockIdx.x*blockDim.x + threadIdx.x)*stride;
odata[xid] = idata[xid];
}这会导致fetch到的数据有一半都用不着,随着stride的增加,利用率会极速下降:

所以这种情况一定要避免。
9.2.2. 共享内存
共享内存是片上的,高带宽低延时,但是有存储片冲突。
9.2.2.1. 共享内存和存储片
存储片和存储片冲突可以看这个:GPU 共享内存bank冲突(shared memory bank conflicts)
重点是,硬件竟然可以把有冲突的请求分解成没冲突的。通过利用一个和内存请求数相等的因子来降低有效带宽。而且,共享内存还有个广播机制。
对于不同的计算能力,存储片的构造是不一样的,有些大有些小,详细情况请查看CUDA C Programming Guide。
9.2.2.2. 使用共享内存计算矩阵乘法(C=AB)
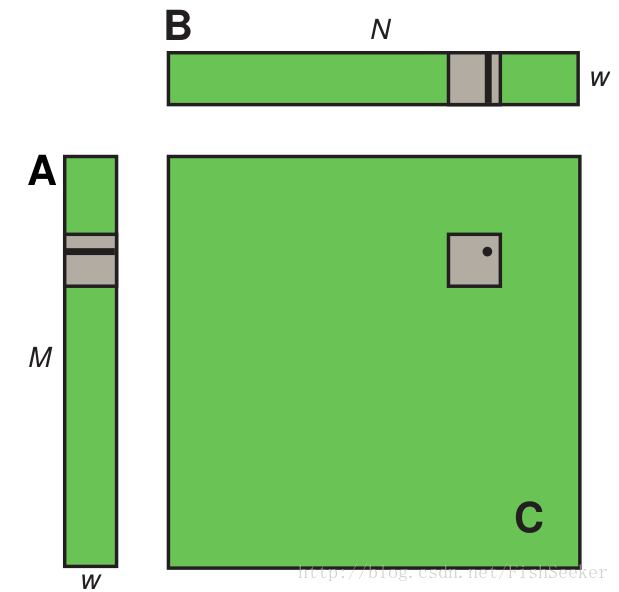
讲真,我觉得这节很多地方都写错了。。。所以还是直接上程序吧:
__global__ void sharedABMultiply(float *a, float* b, float *c,int N)
{
//申请两个临时数组存放a,b的块
__shared__ float aTile[TILE_DIM][TILE_DIM],bTile[TILE_DIM][TILE_DIM];
//这是当前线程操作的坐标,注意这里线程的坐标已经是两维的了
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
//0.0f标记单精度浮点数,加速且防止与主机交换数据产生错误
float sum = 0.0f;
//把数值赋值给临时数组
aTile[threadIdx.y][threadIdx.x] = a[row*TILE_DIM+threadIdx.x];
bTile[threadIdx.y][threadIdx.x] = b[threadIdx.y*N+col];
//要等待所有的线程都赋值完
__syncthreads();
//利用循环乘加
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i]* bTile[i][threadIdx.x];
}
//再赋值给c
c[row*N+col] = sum;
}9.2.2.3. 使用共享内存计算矩阵乘法 (C=AAT)
这节就和上一节一样,不过是转置的矩阵相乘:
__global__ void coalescedMultiply(float *a, float *c, int M)
{
__shared__ float aTile[TILE_DIM][TILE_DIM],transposedTile[TILE_DIM][TILE_DIM];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float sum = 0.0f;
aTile[threadIdx.y][threadIdx.x] = a[row*TILE_DIM+threadIdx.x];
//这个就是找个方法计算出其转置的那个位置
transposedTile[threadIdx.x][threadIdx.y] =a[(blockIdx.x*blockDim.x + threadIdx.y)*TILE_DIM +threadIdx.x];
__syncthreads();
for (int i = 0; i < TILE_DIM; i++) {
sum += aTile[threadIdx.y][i]* transposedTile[i][threadIdx.x];
}
c[row*M+col] = sum;
}9.2.3. 本地内存
本地内存实际上是片外的。因此访问本地内存和访问全局内存一样开销很大。local只被用来放自动变量,这是由NVCC控制,当它发现木有足够的寄存器来放变量的时候,就会把变量放到Local里。自动变量就是那些比寄存器大得多的数据,比如数组或者很大的结构体。通过看PTX代码可以知道哪些变量被放在local里了。还能使用–ptxas-options=-v这个选项来看Local到底用了多少。
9.2.4. 纹理内存
其实一直对纹理内存都是拒绝的,不知道为啥
在地址确定的情况下,从纹理内存取数据要比从全局内存或者常量内存取数据快得多。
9.2.4.1. 额外的纹理能力
使用tex1D() , tex2D() , or tex3D()可能比tex1Dfetch()快。
9.2.5. 常量内存
设备上一共64KB的常量内存。在访问的时候不同的线程只能顺序访问不同的地址,如果访问相同的地址就会变得很快。
9.2.6. 寄存器
虽然访问寄存器几乎不耗费时间,但是读后写等访问模式是造成访问寄存器时延的一大原因。不过这一时延被多线程很好的掩盖了。而且,对于寄存器的访问,编译器也会尽量优化防止冲突,当一个线程块有64个线程的时候冲突最小。
9.2.6.1. 寄存器压力
当没有足够的寄存器分配给任务的时候就会出现寄存器压力。即时每个SM都要上千个32位寄存器,但会被并发的线程共享。为了阻止编译器分配过多的寄存器,使用-maxrregcount=N命令来控制分配给每个线程的最大寄存器数量。
9.3. 内存分配
使用cudaMalloc() 和 cudaFree()来申请和释放内存的开销很大,因此数据能重用就用哇~