《机器学习》K-近邻算法相关知识点小结
在机器学习中,最为简单的模型,也是入门级别的模型,应该算KNN了。KNN是一种简单的机器学习算法,是这一种监督式学习的分类算法。所谓的K-近邻算法的主要思想如下:
找出训练集中距离样本最接近的K个点,取分类出现最多的作为测试集的测试结果。
根据这个原理,我们就可以进行相应的开发了。按照一般的步骤,第一步,训练模型。
#训练模型
def train(inX,inY):
data = inX
label = inY
return inX,label这个步骤主要是讲我们收集到的数据去训练我们的模型。
第二步,用KNN算法预测分类。
#用KNN算法进行预测分类
def predict(data,label,x,k):
xsize = data.shape[0]
xarray = np.tile(x,(xsize,1))
sqrXArr = (data - xarray)**2
sumXArr = sqrXArr.sum(axis = 1)
sqrtXArr = np.sqrt(sumXArr)
sortedArr = sqrtXArr.argsort()
classCount = {}
for i in range(0,k):
classCount[label[i]] = classCount.get(label[i],0)+ 1
maxNum = 0
ksize = len(classCount)
for i in range(0,ksize):
if classCount.get(label[i],0)>maxNum:
maxNum = classCount.get(label[i],0)
xlabel = label[i]
return xlabel具体的实现并没有统一的标准,我写的这段求出现次数最多的分类你们也 可以用其余方法来写,这个只是一个参考方法,我写的是比较简单,容易想到的方法。
上面两个部分是一般的KNN常见的步骤。在我们具体的使用中,我们还需要考虑其余的问题,一方面是关于数据的读取,另一方面是关于数据的使用。
以约会网站为例,我们用到的大量的网站会员的相关数据的读取是一个工作量比较大的事情,常规的靠人为手动输入,存取是一件不符合实际,不利于二次使用的事情。在此考虑的做法是通过读取文件的形式来获取数据。
#以文件的方式读取数据,获取训练集数据
def read_matrix(self,filename):
fr = open(filename)
lines = fr.readlines()
classLabelVector = []
index = 0
dataMat = np.zeros((len(lines),3))
#
for line in lines:
line = line.strip()
lineData = line.split('\t')
dataMat[index,:] = lineData[0:3]
classLabelVector.append(lineData[-1])
index = index + 1
return dataMat,classLabelVector此处需要注意的事情是,读取文件获取的数据集和分类两类信息时的读取方式需要根据实际情况来指定,如下面的手写识别软件单个文件存储的是32*32的二进制数据时的处理方式就很不一样。
def img2Vector(filename):
returnVector = np.zeros((1,1024))
file = open(filename)
for j in range(32):
line = file.readline()
for i in range(32):
print(int(line[i]))
returnVector[0,32*j+i] = int(line[i])
return returnVector具体训练集数据的使用,还需要考虑的问题是,数据的归一化问题。在数据的特征比较多的时候,考虑这个问题很有必要。归一化的处理,能够避免因为一些取值差距比较大的项对分类结果造成比较大的干扰。主要用到的公式就是:![]()
#KNN涉及数据归一化处理,为了防止数据项取值范围过大给结果造成比较大的影响(归一化特征)
def autoNorm(self,dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normalDataSet = np.zeros(dataSet.shape)
dataSetSize = dataSet.shape[0]
normalDataSet = dataSet - np.tile(minVals,(dataSetSize,1))
normalDataSet = normalDataSet / np.tile(ranges,(dataSetSize,1))
return normalDataSet,ranges,minVals自己根据《机器学习实战》这本书写了点代码,相关的数据可以从链接:https://pan.baidu.com/s/1A1oS_2l_TgCE_mzE4ng94Q
提取码:s7y3进行下载提取
下面是实现的手写识别系统的例子,
# !usr/local/bin
# _*_ coding=utf8 _*_
import numpy as np
from os import listdir
import operator
def img2Vector(filename):
returnVector = np.zeros((1,1024))
file = open(filename)
for j in range(32):
line = file.readline()
for i in range(32):
print(int(line[i]))
returnVector[0,32*j+i] = int(line[i])
return returnVector
#训练模型
def train(inX,inY):
data = inX
label = inY
return inX,label
#用KNN算法进行预测分类
def predict(data,label,x,k):
xsize = data.shape[0]
xarray = np.tile(x,(xsize,1))
sqrXArr = (data - xarray)**2
sumXArr = sqrXArr.sum(axis = 1)
sqrtXArr = np.sqrt(sumXArr)
sortedArr = sqrtXArr.argsort()
classCount = {}
for i in range(0,k):
tempLabel = label[sortedArr[i]]
classCount[tempLabel] = classCount.get(tempLabel,0)+ 1
maxNum = 0
xlabel = 0
ksize = len(classCount)
for key,value in classCount.items():
if value >maxNum:
maxNum = value
xlabel = key
return xlabel
def classify0(dataSet,inX, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def handwritingClassTest():
hwLabels = []
#准备训练集数据
trainingFieldList = listdir('trainingDigits')
m = len(trainingFieldList)
trainMat = np.zeros((m,1024))
for i in range(m):
fileNameStr = trainingFieldList[i]
fileStr = fileNameStr.split('.')[0]
ClassNumStr = int(fileStr.split('_')[0])
hwLabels.append(ClassNumStr)
trainMat[i,:] = img2Vector('trainingDigits/%s' % fileNameStr)
trainMat,hwLabels = train(trainMat,hwLabels)
#准备测试数据
testFieldList = listdir('testDigits')
mTest = len(testFieldList)
erroCount = 0.0
for i in range(mTest):
fileNameStr = testFieldList[i]
fileStr = fileNameStr.split('.')[0]
ClassNumStr = int(fileStr.split('_')[0])
testMat = img2Vector(('testDigits/%s' % fileNameStr))
classifierResult = predict(trainMat,hwLabels,testMat,3)
print('KNN算出的分类结果是:{},其真实分类是:{}'.format(ClassNumStr,classifierResult))
if ClassNumStr != classifierResult:
print(ClassNumStr,'-----',classifierResult)
erroCount += 1
print('本系统的错误率为:{}'.format(erroCount/mTest))
#rst = img2Vector('trainingDigits/0_0.txt')
#print(str(rst))
handwritingClassTest()
运行结果如下图
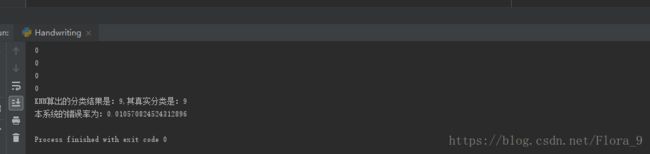
错误率是1%,分类结果还是比较好的。
虽然KNN算法看起来简单易懂,但是还存在一些缺点:
第一,需要的占据比较大的存储空间,训练集占据大部分。
第二,训练集数据量大,训练样本占据的时间会比较长
在实际的应用中,应该根据实际情况考虑。